 Vinu Kumar is Chief Technologist at HorizonX, based in Sydney, Australia. Vinu helps businesses in unifying data, focusing on a centralized data architecture. In this guest post, reposted from the original here, he explains how to automate solving data quality using open source tools such as StreamSets Data Collector Engine, Apache Griffin and Apache Kafka to build smart data pipelines.
Vinu Kumar is Chief Technologist at HorizonX, based in Sydney, Australia. Vinu helps businesses in unifying data, focusing on a centralized data architecture. In this guest post, reposted from the original here, he explains how to automate solving data quality using open source tools such as StreamSets Data Collector Engine, Apache Griffin and Apache Kafka to build smart data pipelines.

“Data is the new oil. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.”
— Clive Humby (UK Mathematician and architect of Tesco’s Clubcard)
Clive Humby first coined the term “Data is the new oil” in 2006. The chaos in data always existed and the struggle from businesses to extract meaningful information from this data is universal. With the computing capability to process more data than we can handle, 90% of data we receive is unstructured. Only 0.5% of the data we receive is ever analysed and used.
Data quality issues form a key challenge in the data world. Unstructured data acquired from multiple sources often causes a delay in deriving insights or even simple analytics due to data quality issues.
What is Data Quality?
- How well it meets the expectations of the data consumer
- How will it fit into the Data Quality Dimensions like accuracy, completeness, consistency, timeliness, availability, and fitness for use
Most enterprises set up a Data Quality Framework that defines data quality capability and enforces it as a process by the organisation. A data quality framework will benefit data owners, data architects, business analysts and data scientists.
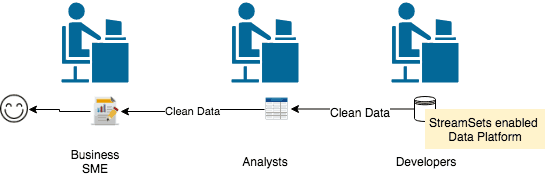
Imagine a process run by a business SME to consolidate a report to be sent to a regulatory body, but due to data errors introduced at the data entry stage, the numbers do not match. They then have to get help from other teams to fix the data quality issue before they can rerun the report.
This is illustrated below:
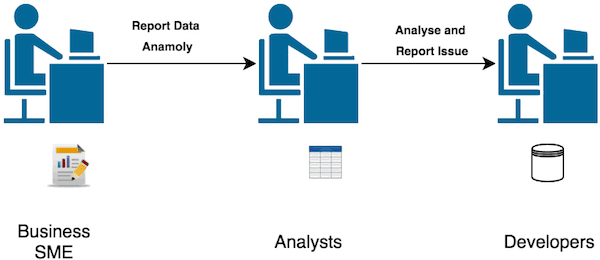
Due to the nature of the manual process involved, often an enterprise data quality strategy is created. There are definitive guidelines, but without an automated framework, it is going to be costly and more importantly time-consuming, not to mention the errors caused by human error.
The StreamSets DataOps Platform helps you build and operate data pipelines. Developers design pipelines with a minimum of code and operators get high reliability, end-to-end live metrics, SLA-based performance and in-stream data protection.
StreamSets Data Collector Engine is open source software that lets you easily build continuous data ingestion pipelines that have the following benefits:
- Design and execute data pipelines that are resilient to data drift, without hand coding.
- Early warning and actionable detection of outliers and anomalies on a stage-by-stage basis throughout the pipeline.
- Rich in-stream data cleansing and preparation capabilities to ensure timely delivery of consumption-ready data
- A large number of built-in integrations with source and destination systems
Apache Griffin is a data quality application that aims to solve the issues we find with data quality at scale. Griffin is an open-source solution for validating the quality of data in an environment with distributed data systems, such as Hadoop, Spark, and Storm. It creates a unified process to define, measure, and report quality for the data assets in these systems. You can see Griffin’s source code on GitHub.
From here, we’ll discuss a sample architecture for solving data quality using StreamSets Data Collector Engine, Kafka, Spark, Griffin and ElasticSearch
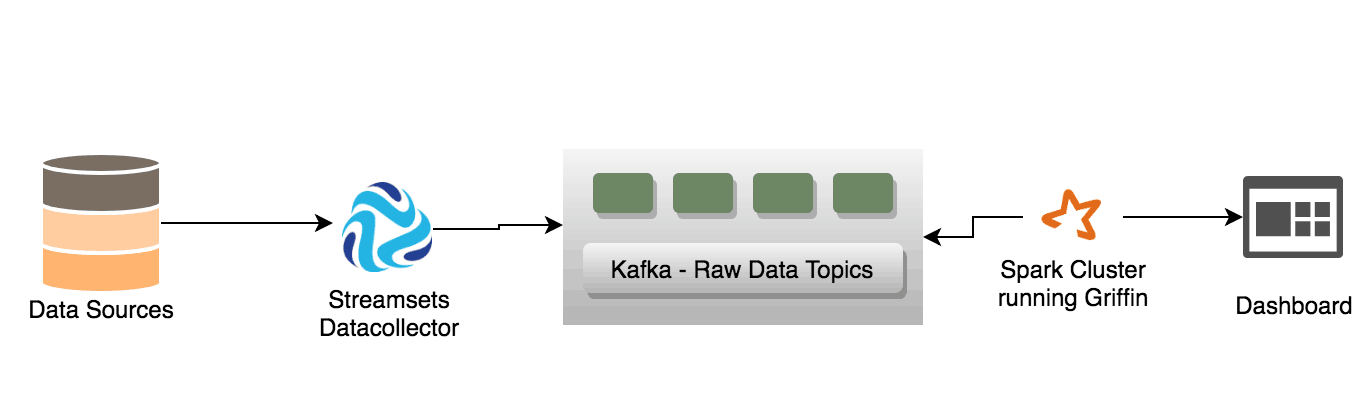
Following are the main components:
- StreamSets Data Collector — Ingest data from multiple data sources and publish to a Kafka producer
- Apache Griffin runs in spark collects the quality metrics and publish it into ElasticSearch. This process can be extended to email someone when a quality check fails or doesn’t meet the threshold while the rules are embedded in the Spark cluster as a JSON. Griffin supports data profiling, accuracy and anomaly detection.
- Kafka is the intermediary broker layer that enables the streaming process. This topic could also be tapped into by other consumers that are interested in the raw data
This is only a part of the solution. End-end automation would involve solving data quality issues within the stream and publishing to a different Kafka topic. This would then be transported to a data warehouse, data lake or a number of other consumers for the next step of data validation.
For this prototype, we used StreamSets & Kafka (with Zookeeper) in a GKE (Google Cloud Kubernetes Engine) cluster.
Setting up StreamSets and Kafka in a GKE
StreamSets is set up with a persistentVolume so that the libraries and pipelines are not lost when a new pod is created.
To use a persistentVolume, just create a persistentVolumeClaim
Example:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ss-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
and add it as a volume.
volumes:
- name: data
persistentVolumeClaim:
claimName: ss-data
readOnly: false
We’ll also set up the external libraries in the persistent volume.
Kafka & Zookeeper are setup using StatefulSets.
Because we need StreamSets to publish, we have to create a load balancer service in Kubernetes and update Kafka listeners with external advertised listeners setup.
We’ll share a separate blog post on how we setup everything in Kubernetes.
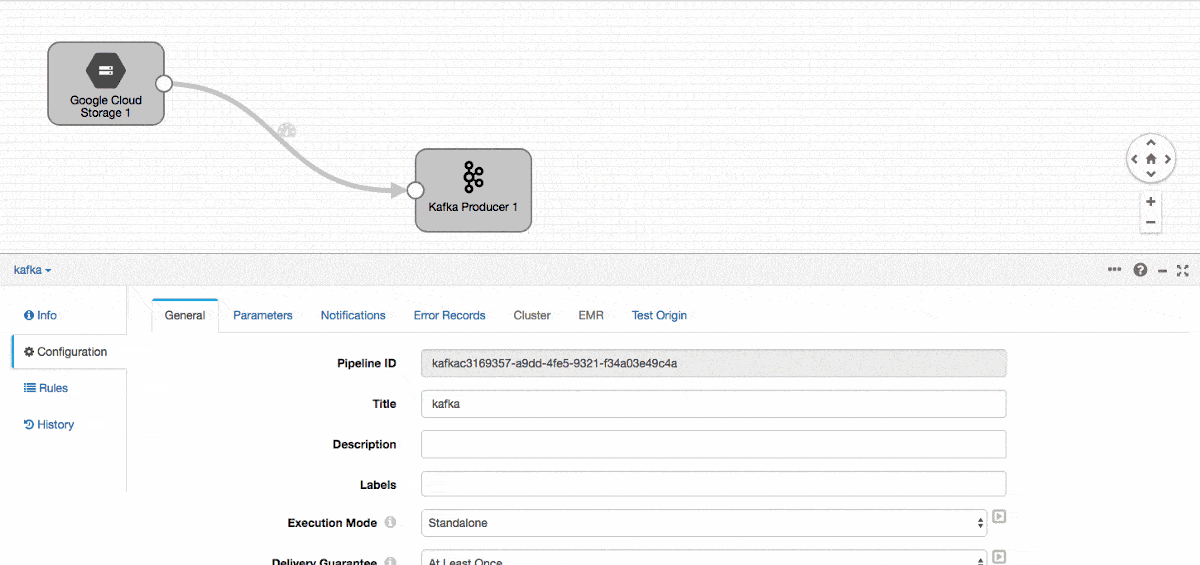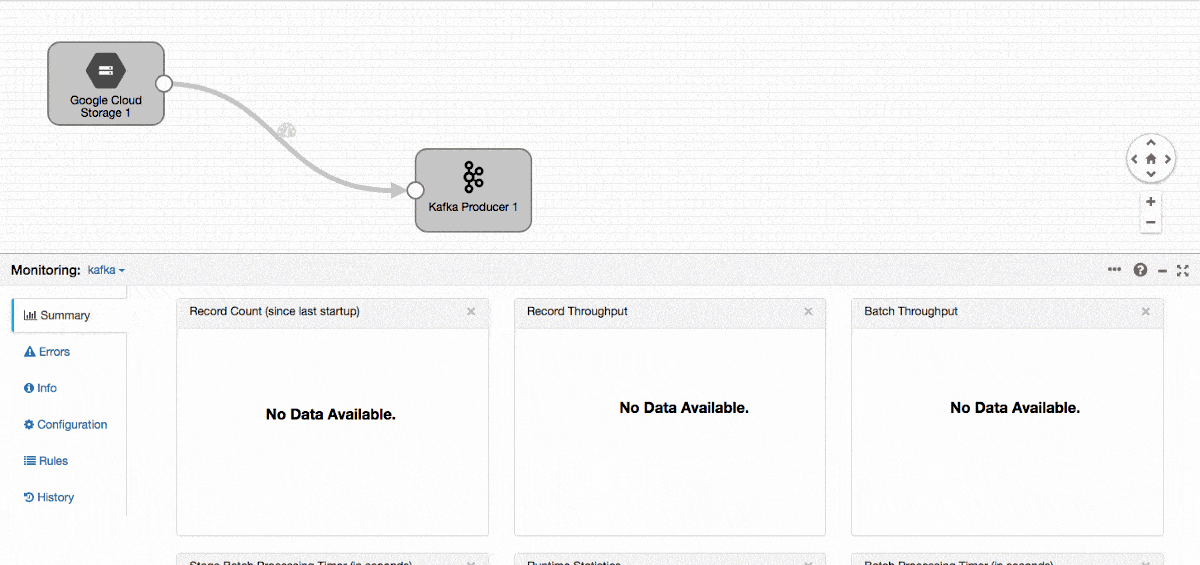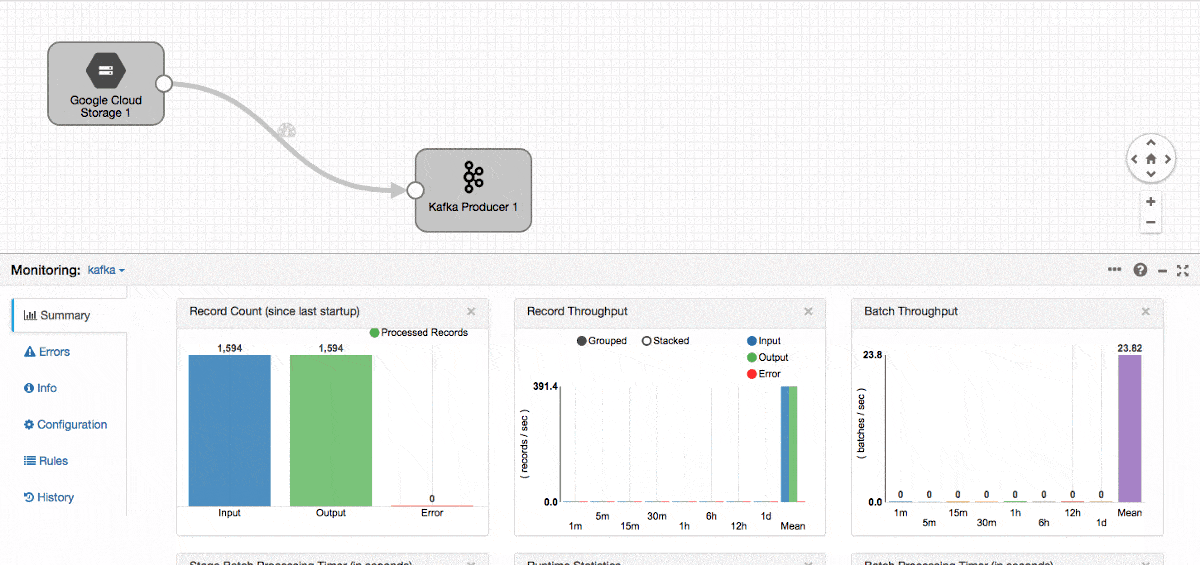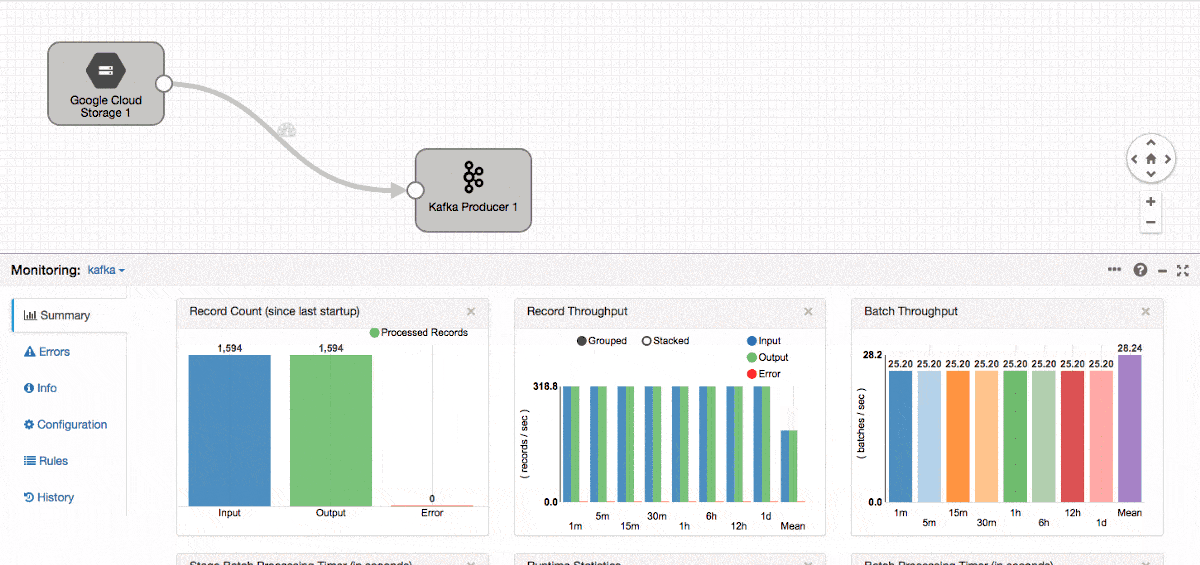
Figure 3: StreamSets Data Collector Engine

Once everything is up and running, we create a streaming data pipeline which reads JSON files from Google Cloud Storage and publishes to Kafka.
Once the pipeline is started, we can quickly jump into the Kafka node and test the consumer!
Run Apache Griffin Data Quality App on a Spark Cluster
The next step is to set up a Spark cluster to run the Griffin data quality application.
Here is a brief on the scenario:
A Hive datastore contains a customer’s country information. A Kafka stream comes with customer data associated with their company details. The Griffin application checks if the name associated with the id from Kakfa streams matches to that of Hive. Any anomaly is reported in Elasticsearch and visualized in Kibana.
Step 1 — Prepare configuration files:
Griffin env file:
{
"spark": {
"log.level": "WARN",
"checkpoint.dir": "hdfs:///griffin/checkpoint",
"batch.interval": "20s",
"process.interval": "1m",
"init.clear": true,
"config": {
"spark.default.parallelism": 4,
"spark.task.maxFailures": 5,
"spark.streaming.kafkaMaxRatePerPartition": 1000,
"spark.streaming.concurrentJobs": 4,
"spark.yarn.maxAppAttempts": 5,
"spark.yarn.am.attemptFailuresValidityInterval": "1h",
"spark.yarn.max.executor.failures": 120,
"spark.yarn.executor.failuresValidityInterval": "1h",
"spark.hadoop.fs.hdfs.impl.disable.cache": true
}
},
"sinks": [
{
"type": "console"
},
{
"type": "hdfs",
"config": {
"path": "hdfs:///griffin/persist"
}
},
{
"type": "elasticsearch",
"config": {
"method": "post",
"api": "http://:9200/griffin/accuracy"
}
}
],
"griffin.checkpoint": [
{
"type": "zk",
"config": {
"hosts": ":2181",
"namespace": "griffin/infocache",
"lock.path": "lock",
"mode": "persist",
"init.clear": true,
"close.clear": false
}
}
]
}
Setup Data Quality Configuration:
{
"name": "customer_data_accu",
"process.type": "streaming",
"data.sources": [
{
"name": "src",
"baseline": true,
"connectors": [
{
"type": "kafka",
"version": "1.0",
"config": {
"kafka.config": {
"bootstrap.servers": ":9092",
"group.id": "griffin",
"auto.offset.reset": "largest",
"auto.commit.enable": "false"
},
"topics": "source",
"key.type": "java.lang.String",
"value.type": "java.lang.String"
},
"pre.proc": [
{
"dsl.type": "df-opr",
"rule": "from_json"
}
]
}
],
"checkpoint": {
"type": "json",
"file.path": "hdfs:///griffin/streaming/dump/source",
"info.path": "source",
"ready.time.interval": "10s",
"ready.time.delay": "0",
"time.range": [
"-5m",
"0"
],
"updatable": true
}
},
{
"name": "tgt",
"connectors": [
{
"type": "hive",
"version": "2.1",
"config": {
"database": "default",
"table.name": "customers_country"
}
}
],
"checkpoint": {
"type": "json",
"file.path": "hdfs:///griffin/streaming/dump/target",
"info.path": "target",
"ready.time.interval": "10s",
"ready.time.delay": "0",
"time.range": [
"-1m",
"0"
]
}
}
],
"evaluate.rule": {
"rules": [
{
"dsl.type": "griffin-dsl",
"dq.type": "accuracy",
"out.dataframe.name": "accu",
"rule": "src.id = tgt.id AND src.first = tgt.first AND src.last = tgt.last ",
"details": {
"source": "src",
"target": "tgt",
"miss": "miss_count",
"total": "total_count",
"matched": "matched_count"
},
"out": [
{
"type": "metric",
"name": "accu"
},
{
"type": "record",
"name": "missRecords"
}
]
}
]
},
"sinks": [
"CONSOLE",
"HDFS",
"ELASTICSEARCH"
]
}
The above configuration sets up Kafka streams as a source and uses Hive as a destination to compare with. This is the rule:
"rule": "src.id = tgt.id AND src.first = tgt.first AND src.last = tgt.last "
This rule uses accuracy as a data quality measure. Griffin also supports profiling, where we would profile an incoming data in stream or batch to ensure it matches the required criteria.
"dq.type": "accuracy"

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Step 2 — Setup Spark Cluster in Google Cloud Data Proc
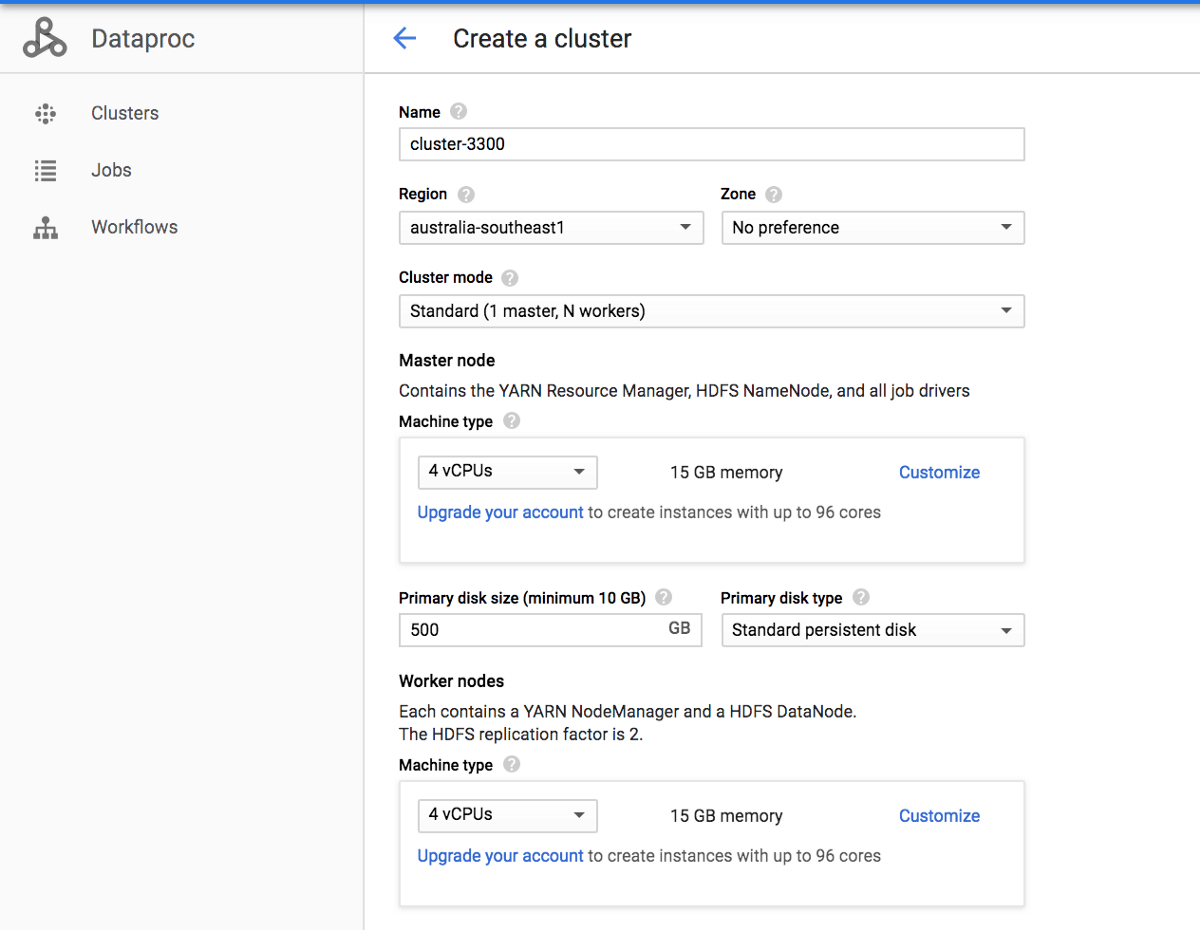
Select Spark 2.2 (from images), choose the CPU/Memory configuration, number of workers and launch the cluster
Copy env.json and dq.json into the master node of the cluster.
Download Apache Griffin source https://archive.apache.org/dist/griffin/0.4.0/griffin-0.4.0-source-release.zip, build and copy the measure-0.4.0.jar to the master node.
SSH to the master node and setup a hive table to be used for reference.
CREATE EXTERNAL TABLE `customers_country`( `id` STRING, `email` STRING, `first` STRING, `last` STRING, `country` STRING, `created_at` STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION 'hdfs:///griffin/data/customers/customers_country';
Import the reference data into the table:
LOAD DATA LOCAL INPATH 'customers_country.csv' INTO TABLE customers_country ;
Step 3 — Setup a Spark Job
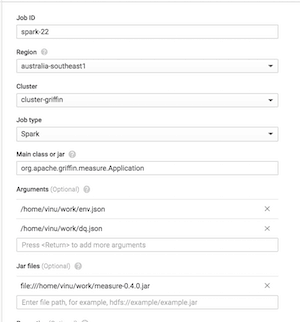
Choose the newly created cluster, provide the main Application name, i.e org.apache.griffin.measure.Application.
Provide the configuration files as arguments, starting with the env files.
Add the measuring jar file path and create the job. This is a streaming job, and the job will be running and constantly look for Kafka streams
9/02/19 05:39:45 INFO org.spark_project.jetty.util.log: Logging initialized @5135ms
19/02/19 05:39:45 INFO org.spark_project.jetty.server.Server: jetty-9.3.z-SNAPSHOT
19/02/19 05:39:45 INFO org.spark_project.jetty.server.Server: Started @5239ms
19/02/19 05:39:45 INFO org.spark_project.jetty.server.AbstractConnector: Started ServerConnector@5371d1e7{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
19/02/19 05:39:45 INFO org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at cluster-griffin-m/10.152.0.20:8032
19/02/19 05:39:49 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: Submitted application application_1550554583894_0001
Now, upload a JSON file into Google Cloud Storage, which would be picked up by StreamSets. The file contains JSON string in each line, and hence each message is a JSON string. Griffin application then consumes the stream and checks for any data quality issues as per the rules.
Below is an example of data where last names between two records mismatch:
From Kafka:
{
"id": 183,
"email": "verdie12@hotmail.com",
"first": "Angelina",
"last": "Stiedemannaaa",
"company": "Wunsch and Sons",
"created_at": "2014–12–13T09:16:07.580Z"
}
In Hive:
183,verdie12@hotmail.com,Angelina,Stiedemann,2014-12-13T09:16:07.580Z,Samoa
Griffin records this as inaccuracy and publishes the results to ElasticSearch.

This is just an example of one type of measurement. Depending on business need, various rules can be added or refined. Further customization to the platform can be done to even fix the data quality in flight and also to apply the cleaning rules to the original data ingestion pipeline within StreamSets Data Collector.
In summary, we have learned that we can anticipate and address solving data quality issues and downstream effects by building and automating a robust data quality framework!
Would you agree solving data quality is one of the key issues in your data-driven journey?
We believe in delivering quality data platforms, faster and cheaper. Let us know and together we could make you a better data-driven organization. Want to start building smart data pipelines today?
About HorizonX
We’re a team of passionate, expert and customer-obsessed practitioners, focusing on innovation and invention on our customer’s behalf. We follow a combination of the Lean and Agile methodologies and a transparent approach to deliver real value to our customers. We operate as the technical partner for your business, working as an extension of your digital teams. Talk to us today about your digital and data journey.