In this blog, we will review how easy it is to set up an end-to-end ETL data pipeline that runs on StreamSets Transformer as a Spark ETL tool to perform extract, transform, and load (ETL) operations. The pipeline uses Apache Spark for Azure HDInsight cluster to extract raw data and transform it (cleanse and curate) before storing it in multiple destinations for efficient downstream analysis. The pipeline also uses technologies like Azure Data Lake Storage Gen2 and Azure SQL database, and the curated data is queried and visualized in Power BI.
StreamSets Transformer is an execution engine that runs on Apache Spark, an open-source distributed cluster-computing framework, and it enables data engineers to perform transformations that require heavy processing on entire data sets in batch or streaming mode.
Pipeline Overview
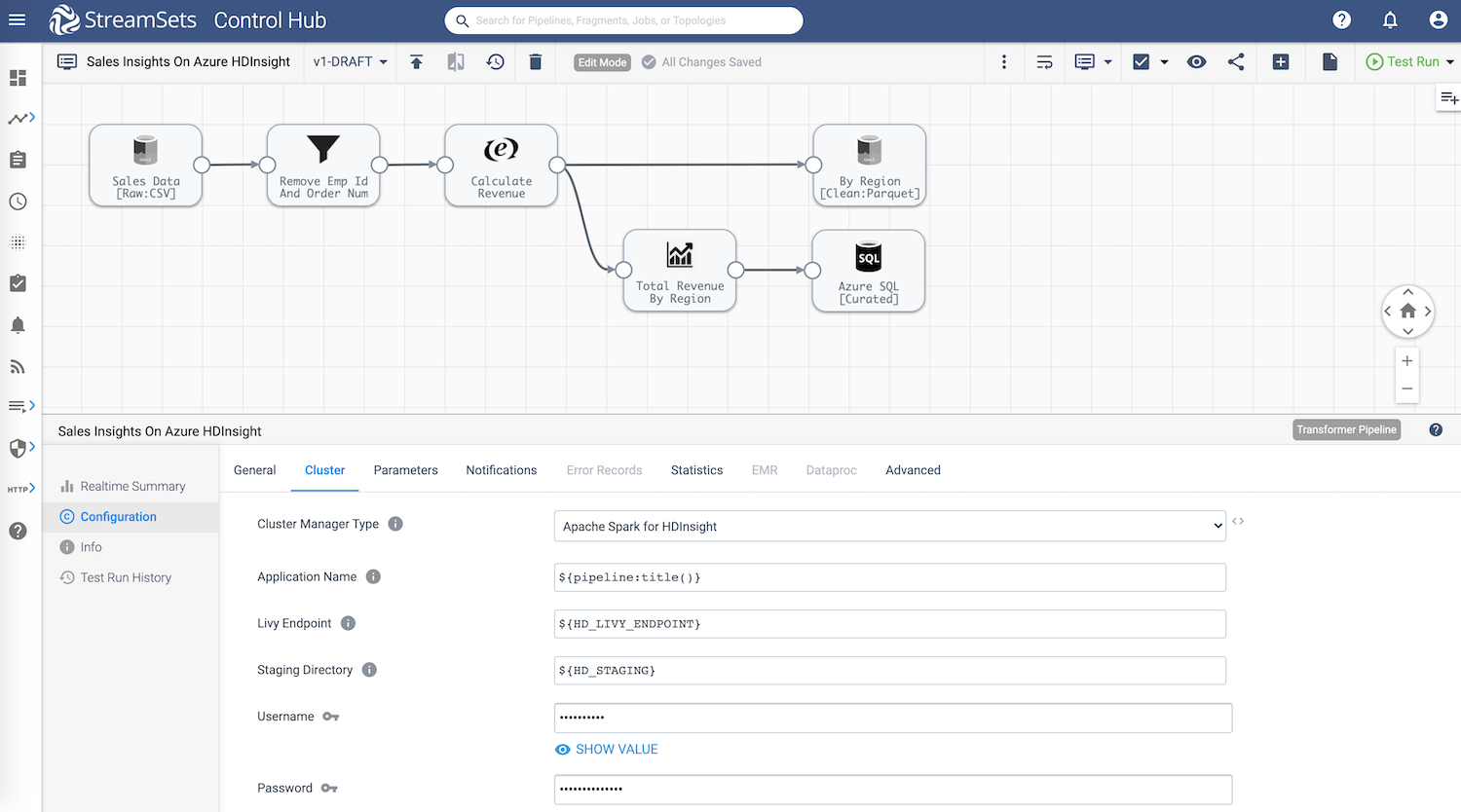
The pipeline is configured to run on Apache Spark for HDInsight as show above and its configuration details such as Livy Endpoint, credentials, etc. are passed in as pipeline parameters.
Here are the details of the data set and pipeline components:
- Data and Data Source: Company sales data stored in large number of .csv files is read from “Raw” zone in Azure Data Lake Storage Gen2 storage container using ADLS Gen2 origin.
- The sales data contains these fields: ordernum,quant,region,store,saledate,dep,item,unitsold,unitprice,employeeID
- Transformations:
- Field Remover: Removes employeeID and ordernum fields assuming they’re not required for analysis
- Spark SQL Expression: Uses Spark SQL expression unitsold * unitprice to calculate order revenue and stores the result in a new field revenue
- Aggregate: Aggregates total revenue by region
- Destinations:
- Transformed data is partitioned by region and stored in “Clean” zone using ADLS Gen2 destination in Parquet format for efficient downstream processing in Spark
- Aggregated data is stored in “Curated” zone in Azure SQL database destination for querying, visualizing, and creating reports in Power BI.
Data Lake Zones
Here is a brief overview and some patterns of different data lake zones.
Raw Zone
This zone stores data in its originating state usually in its original format, such as JSON or CSV, but there may be use cases where it might make more sense to store it in compressed format such as Avro or Parque. As this zone normally stores large amounts of data, something to consider is to using lifecycle management to reduce long term storage costs. For instances, ADLS Gen2 supports moving data to the “cool” access tier either programmatically or through a lifecycle management policy. The policy lets you define a set of rules which can run once a day and can be assigned to the account or filesystem as well as at the folder level.
Clean Zone
This can be thought of as a filter zone that improves data quality and may also involve data enrichment. Some of the more common transformations include data type definition and conversion, removing unnecessary columns, and data enrichment by adding new columns and combining data sets to further improve the value of insights. The organization of this zone is normally dictated by business needs — for example, per region, date, department, etc.
Curated Zone
This is the consumption zone, optimized for analytics and not so much for data processing. This zone stores data in denormalized data marts or star schemas and is best suited for analysts or data scientists that want run ad hoc queries, analysis, or advanced analytics. As storage costs are generally lower in the data lake as compared to the data warehouse, it might be more cost effective to store granular data in the data lake and store aggregated data in this zone.
Pipeline Preview
Let’s see what the data, columns’ datatypes, and the transformations look like in preview mode.
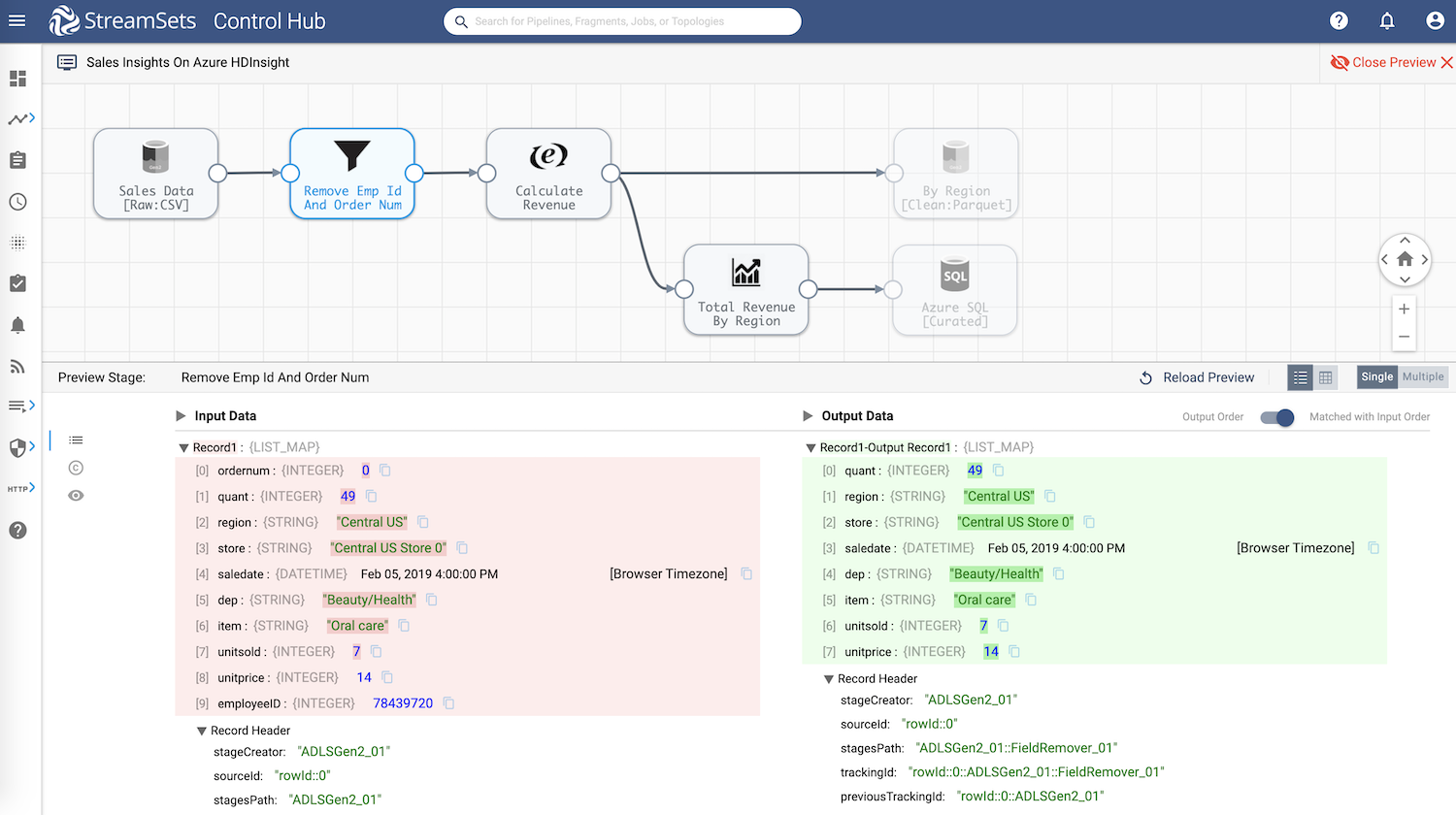
Field Remover
Remove fields that are not required for analysis: employeeID and ordernum.
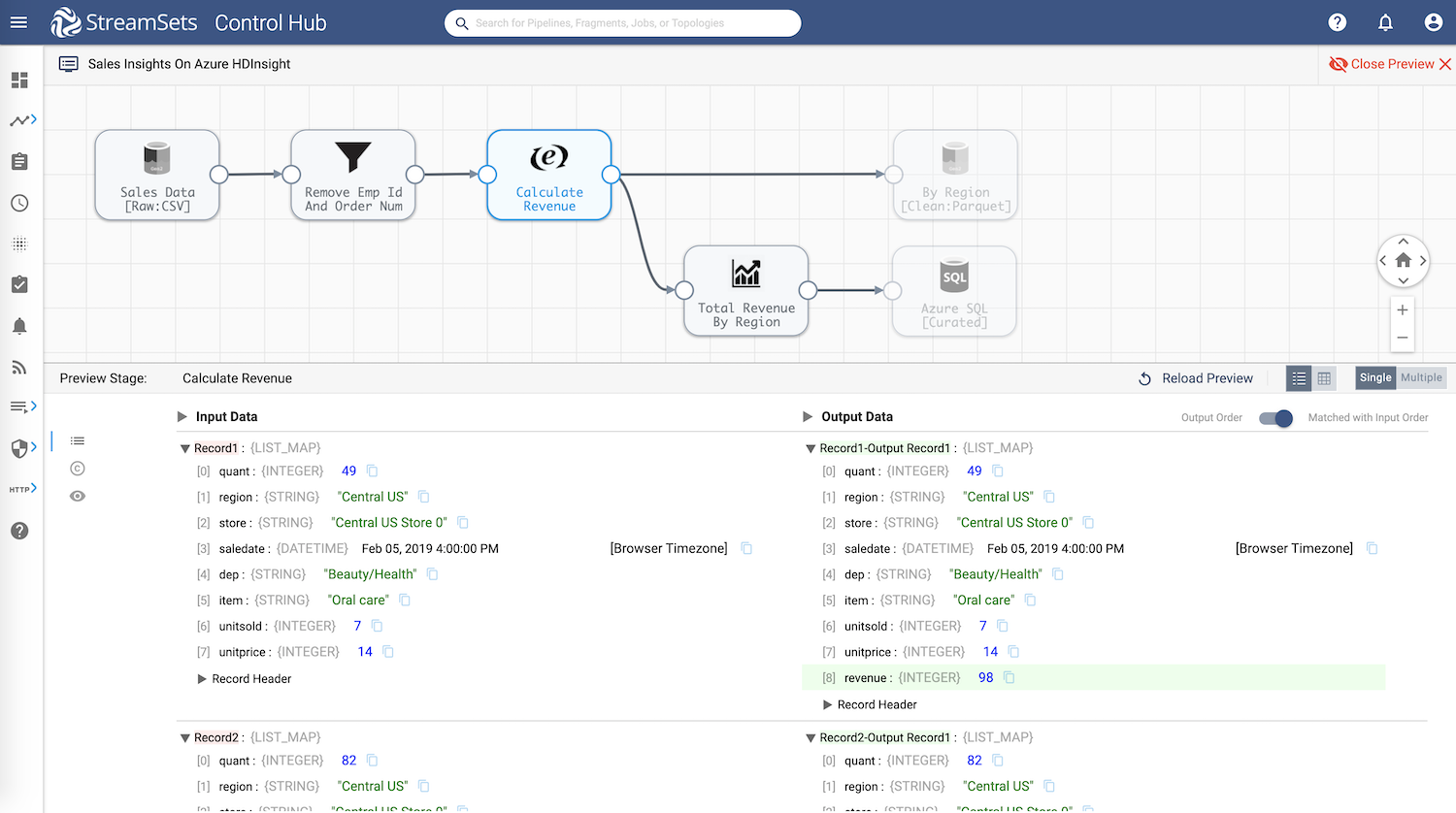
SQL Expression
Use Spark SQL expression unitsold * unitprice to calculate revenue and store the result in a new field revenue.
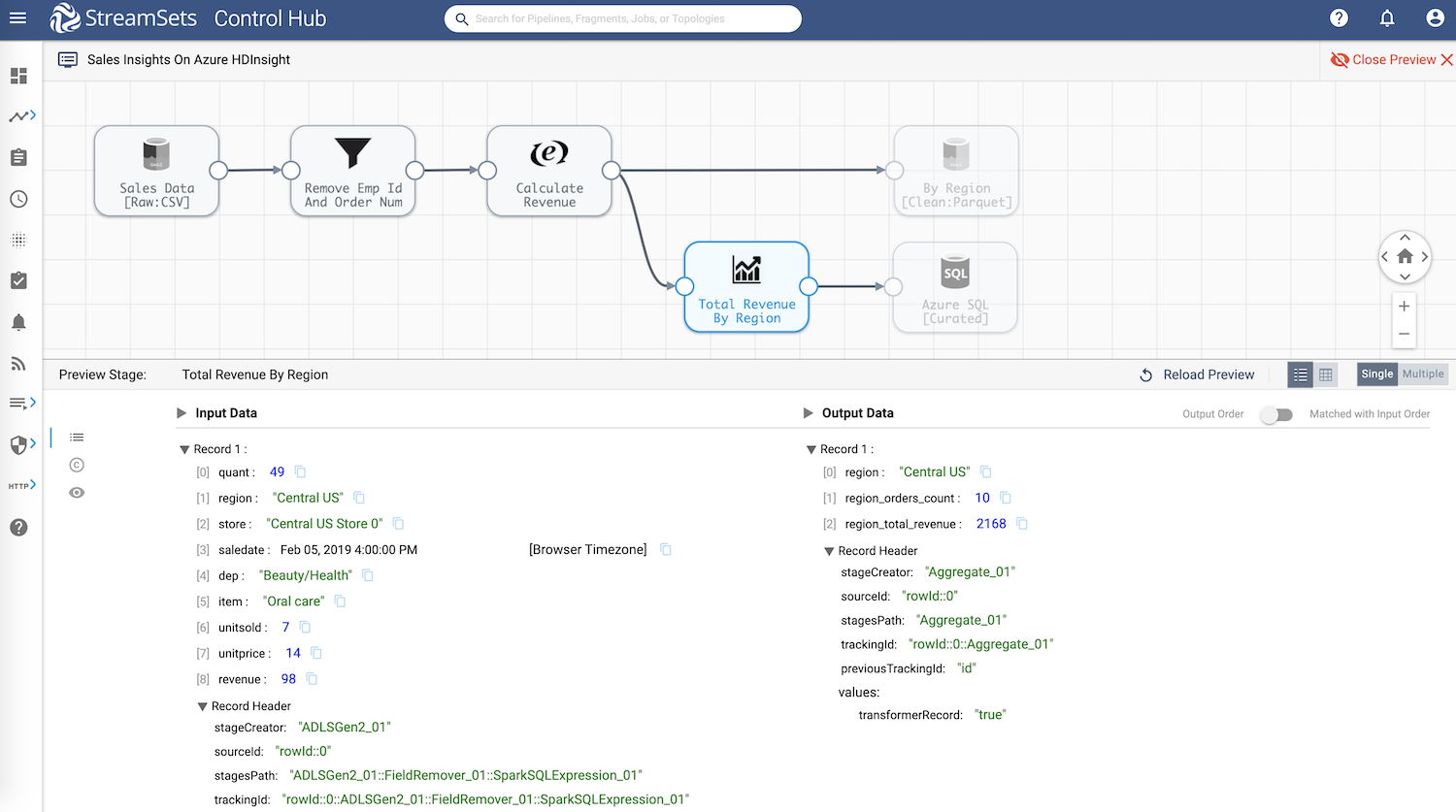
Aggregator
Aggregate total orders count and total revenue by region.
Pipeline Run
A pipeline is run as a Job. Jobs enable scaling and running multiple instances of the same pipeline and the job metrics can be viewed in the bottom pane.
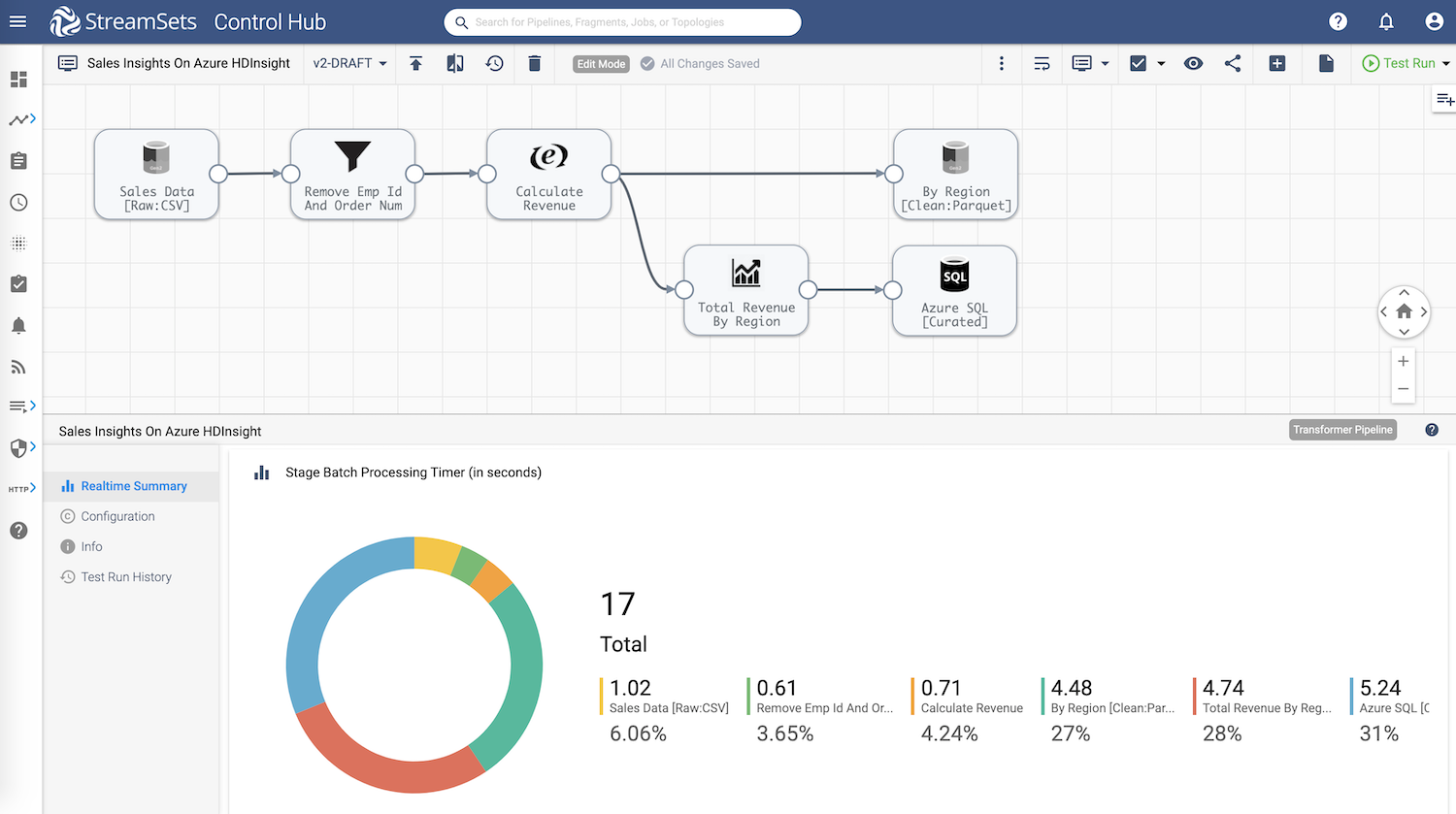
Once the job runs successfully, the cleansed and curated data is available in ADLS Gen2 and Azure SQL destinations respectively as shown below.
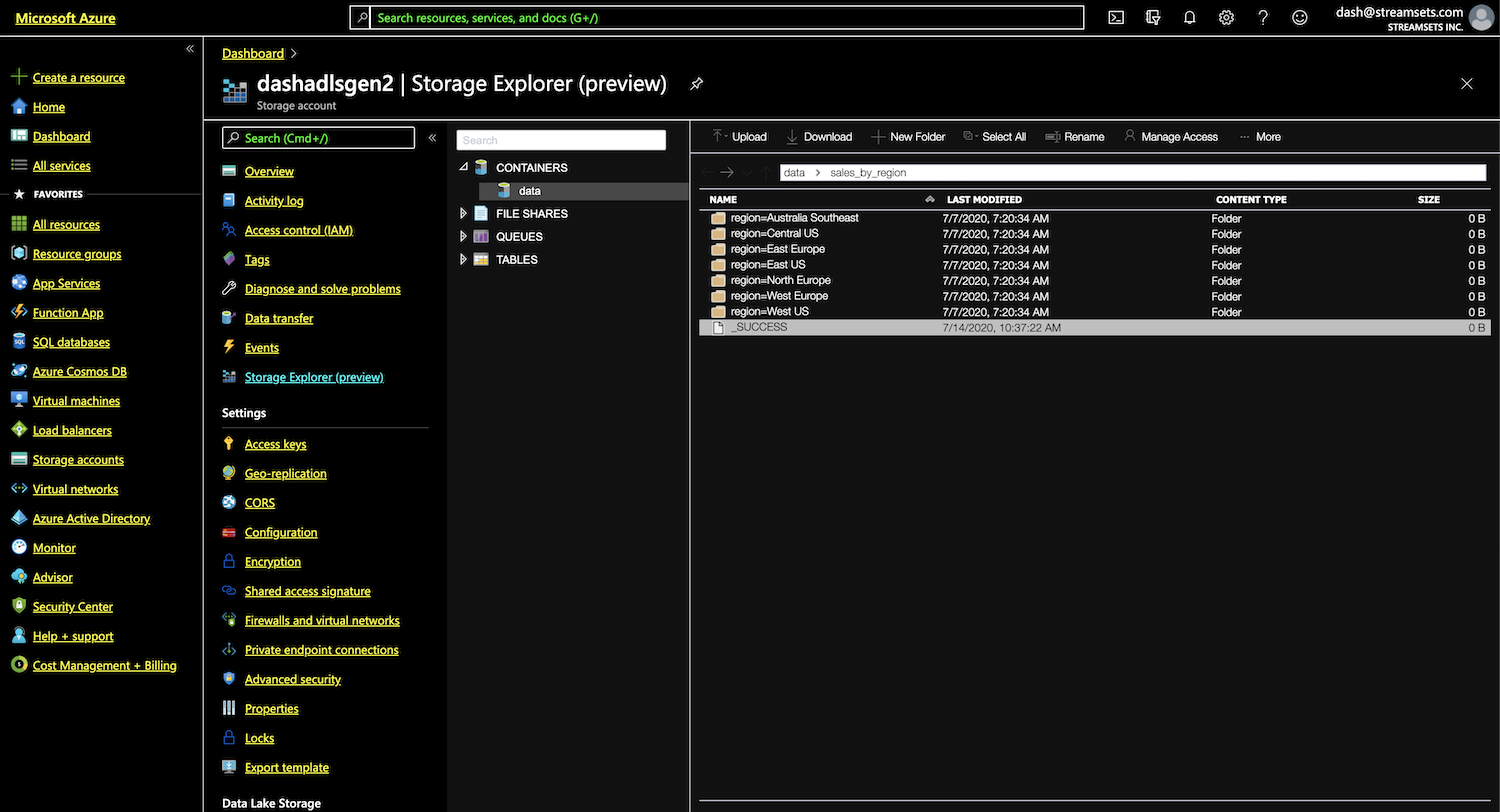
Azure Data Lake Storage Gen2
Here we see that as per the configuration in ADLS Gen2 destination, the data has been partitioned by region. (Not shown are the parquet files in each folder.) This data can then be analyzed or used for further processing using ADLS Gen2 origin in StreamSets Transformer or accessed directly from Azure Databricks or Jupyter notebook in HDInsight.
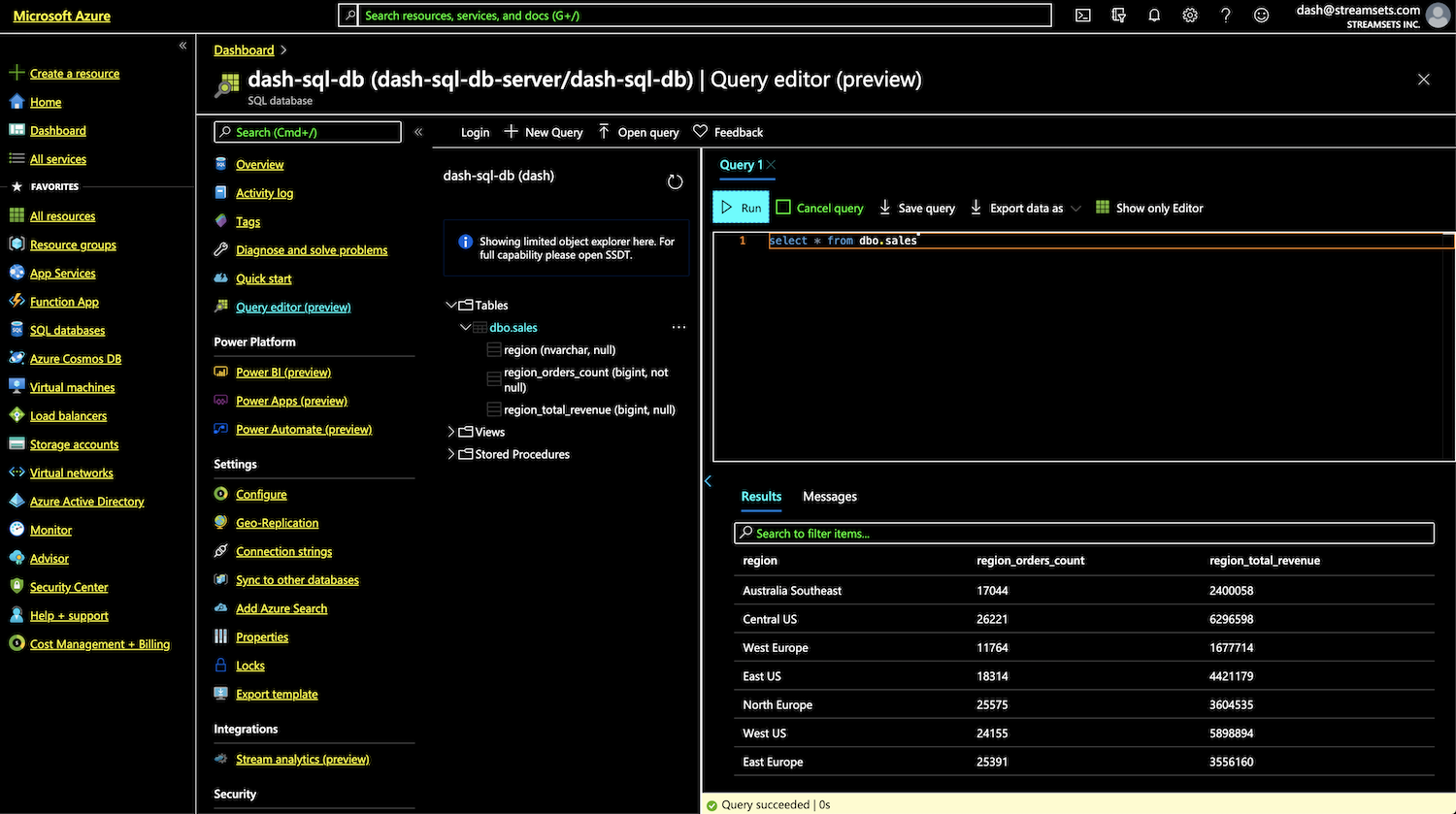
Azure SQL database
Shown below is the database table dbo.sales that was auto-created from StreamSets Transformer pipeline. This table contains the aggregated summary of total orders and revenue by region.
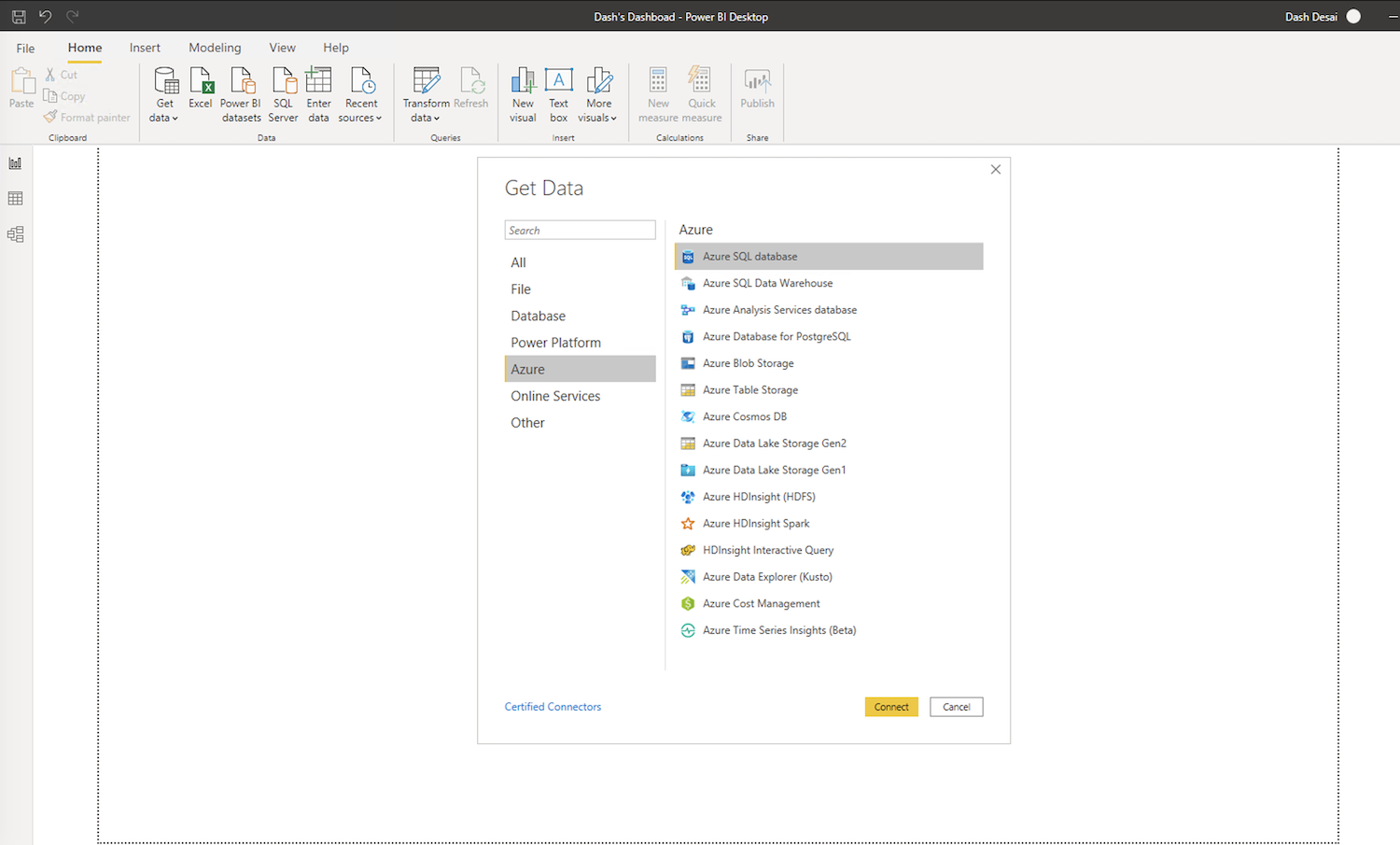
Power BI
Once the curated data is available in Azure SQL database as shown above, it can be queried and visualized in Microsoft’s Power BI.
To get started, open Power BI and click on Get data on the top navigation and then select More… >> Azure >> Azure SQL database. Then clicking on Connect will present a connection dialog to provide credentials to connect to the Azure SQL database.
Once connected to the database, navigate to the table(s) (dbo.sales in our case as shown below) and load the data.
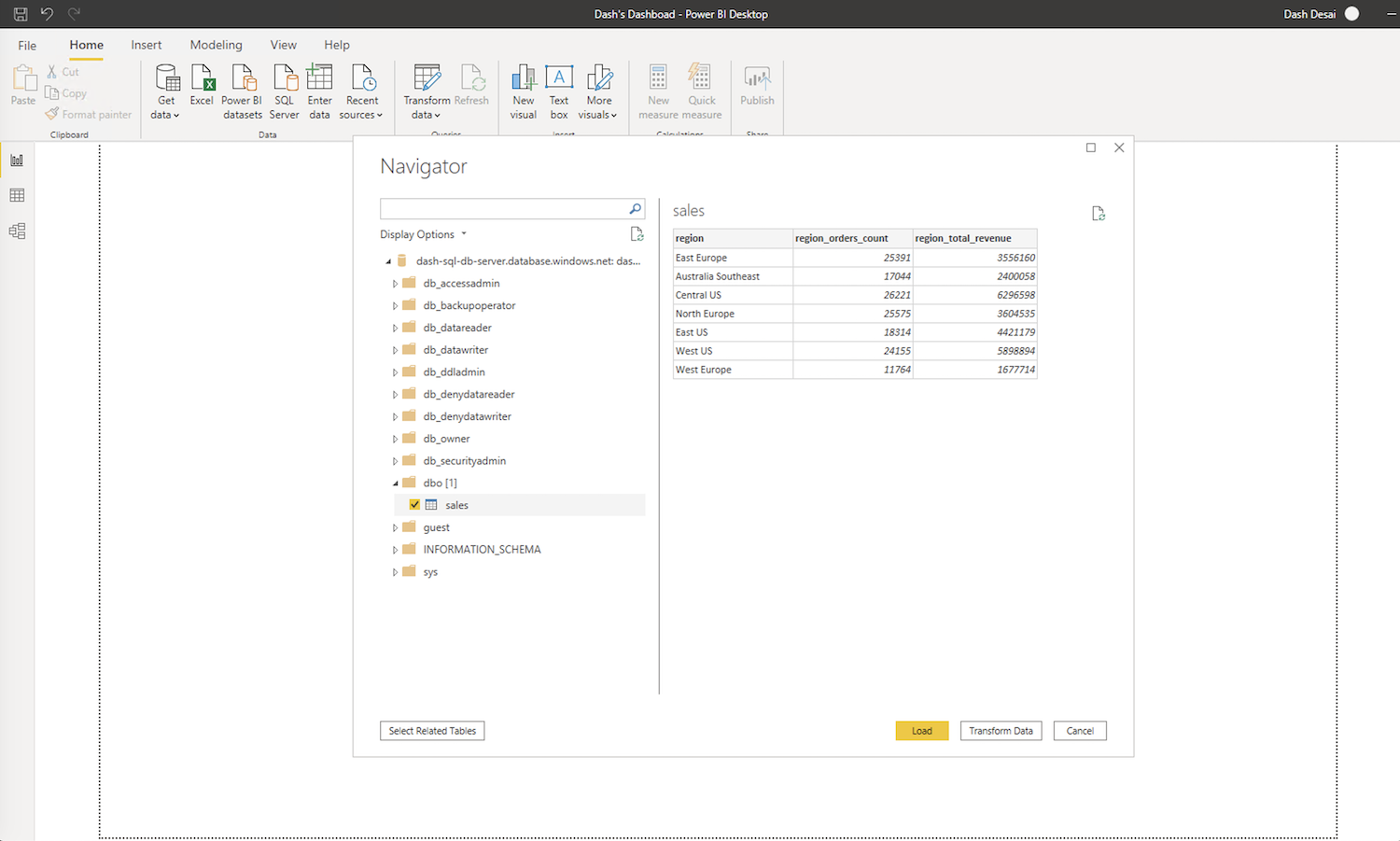
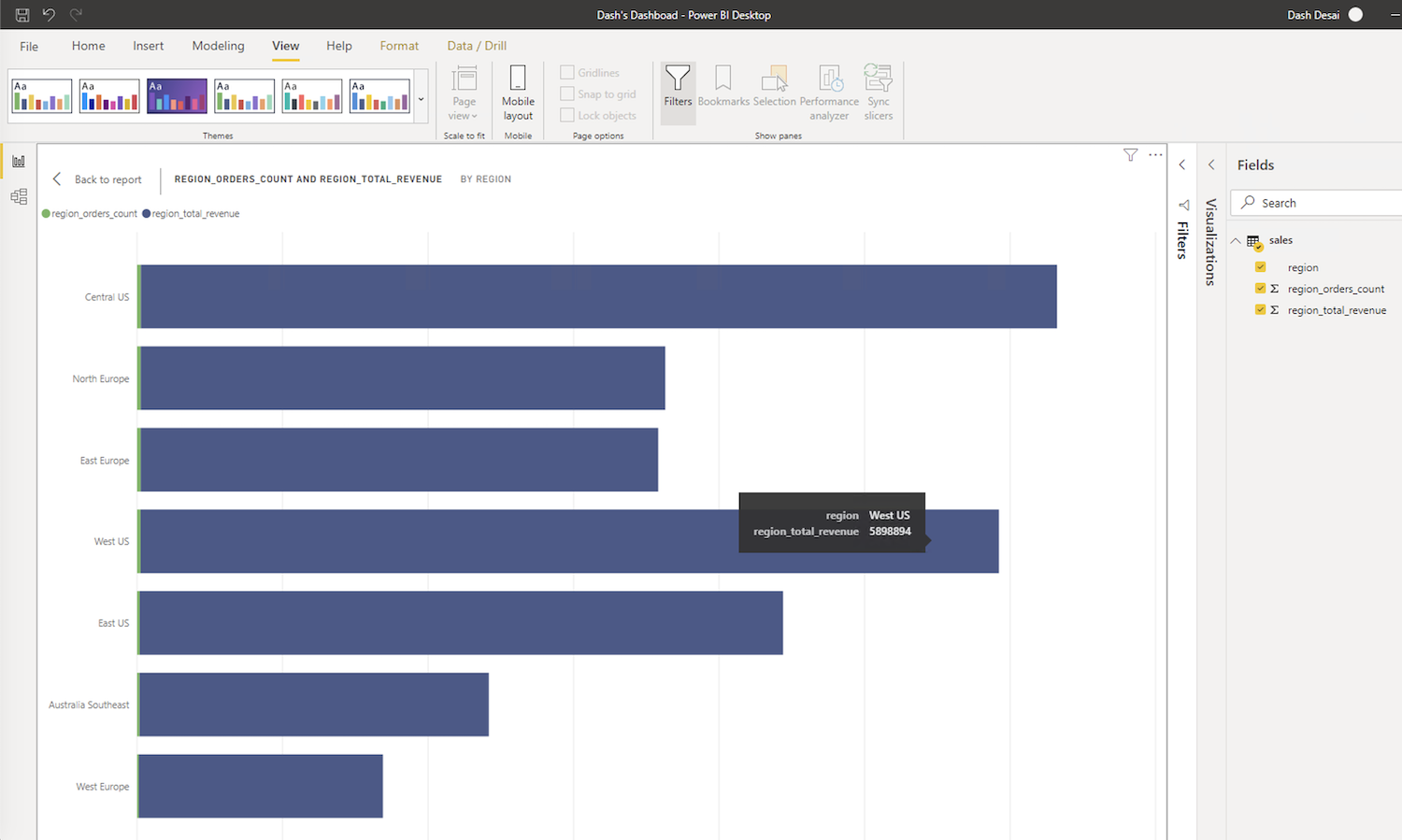
Once the data is loaded and a is model created, Power BI makes it really easy to visualize and analyze the data. As shown below, the chart displays total orders count and total revenue by region. Note that the sales model was created in DirectQuery mode in Power BI so reports and dashboards like this one can deliver “near real-time” / latest data without having to refresh the model. For details and other modes, refer to the documentation.
Sample Pipeline and Dataset on GitHub
If you’d like to get a head start and/or build upon this pipeline, download sample pipeline and sample dataset from GitHub.
After importing the sample pipeline, update pipeline parameters such as, HDInsight cluster details, ADLS Gen2 information for loading raw/source data and also to store clean data, Azure SQL database and credentials for storing curated data, etc. before running the pipeline.
Enjoy!
Summary
While there are different ways to dissect and analyze data, hopefully this blog gives you ideas on how to use some of these tools you might have at your disposal in order to make better, data-driven decisions, faster.
Learn more about StreamSets For Azure Marketplace and StreamSets Transformer.