![]() In this guest blog, Predera‘s Kiran Krishna Innamuri (Data Engineer), and Nazeer Hussain (Head of Platform Engineering and Services) focus on building a data pipeline to perform lookups or run queries on Hive tables with the Spark execution engine using StreamSets Data Collector and Predera’s custom Hive-JDBC lookup processor.
In this guest blog, Predera‘s Kiran Krishna Innamuri (Data Engineer), and Nazeer Hussain (Head of Platform Engineering and Services) focus on building a data pipeline to perform lookups or run queries on Hive tables with the Spark execution engine using StreamSets Data Collector and Predera’s custom Hive-JDBC lookup processor.
Introduction
Why run Hive on Spark?
Since the evolution of query language over big data, Hive has become a popular choice for enterprises to run SQL queries on big data. Hive internally converts the queries to scalable MapReduce jobs. Since Hive queries run on the MapReduce engine they are batch-oriented. To get better performance, Hive can be configured to run queries on the Spark engine instead of MapReduce. This is very valuable if you are already using Spark for other data processing and machine learning needs. Standardizing on one execution backend is convenient for operational management.
What is the problem with the existing solution?
StreamSets Data Collector (SDC) is a tool which allows you to build continuous data pipelines. StreamSets provides a JDBC Lookup Processor which can perform lookup on a database within the pipeline and pass the results to the rest of the pipeline. This JDBC Lookup Processor supports JDBC-compliant drivers such as Hive 2.x and later versions.
The JDBC processor that comes with StreamSets cannot be used when Hive is configured to use the Spark execution engine as Spark internally uses Hive 1.x. Many big data distributions such as Cloudera and HDP also use Hive version 1.x by default. The standard StreamSets JDBC Lookup Processor cannot be used to run queries on Hive in such cases since the Hive 1.x driver does not correctly implement JDBC’s setReadOnly() method – see HIVE-11501 for more detail.
One solution is to build a custom processor which supports Hive version 1.x so that it can be used with Hive on Spark.
Predera Custom Processor
At Predera, we have built a custom JDBC Hive stage lib to support Hive 1.x and Hive queries on Spark. The source code of the stage lib is available at https://github.com/predera/hive-jdbc-stage-lib.
Please follow the installation instructions from the above GitHub repository to setup the custom JDBC Hive stage library on your StreamSets Data Collector instance before trying out the example below.
Spark + Hive + StreamSets: a hands-on example
Configure Spark and Hive
To allow the spark-thrift server to discover Hive tables, you need to configure Spark to use Hive’s hive-site.xml configuration file, and let Spark use the same metastore that is used by Hive installation.
Note: Running Hive queries on top of Spark SQL engine using JDBC client works only when you configure the metastore for Hive in hive-site.xml. Otherwise Spark will create its own metastore in Derby.
To make Hive hive-site.xml accessible to Spark, you can create a symbolic link to the $SPARK_HOME/conf directory as
ln -s $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf/hive-site.xml
and provide the classpath of JDBC connector in Spark’s classpath.
Dataset Description
The MovieLens dataset is used for the examples provided in sections below. The dataset can be downloaded from here.
The dataset contains 1 million ratings from 6000 users on 4000 movies. The following two files will be used for our example:
movies.dat– MovieID::Title::Genresratings.dat– UserID::MovieID::Rating::Timestamp
movies.dat will be copied to HDFS and ratings.dat will be loaded into a Hive table. We will then build a pipeline in StreamSets Data Collector to read the Movie IDs from HDFS and query average ratings using the Hive JDBC lookup processor and finally store the results back to HDFS.
Starting the Thrift server
First let’s start the spark-thrift server from $SPARK_HOME/sbin/start-thriftserver.sh. Here are the different options you can use to start spark-thrift server.
start-thriftserver.sh --help
Usage: ./sbin/start-thriftserver [options] [thrift server options]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
on the PYTHONPATH for Python apps.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
The cluster manager you choose to start the spark-thrift server will be the cluster manager that runs Hive queries on Spark SQL engine. If you do not specify any cluster manager explicitly, the Spark standalone cluster will be chosen. Here we are using Spark standalone cluster to run Hive queries. Verify that JDBC/ODBC section shows up in the Spark UI once the spark-thrift server starts.
Connecting the Hive JDBC Processor to Thrift
On successful start of the spark-thrift server, you will get the port on which spark-thrift is running. Tail the log file and check for the port number
$ tail /path_to_log 17/12/12 13:06:23 INFO service.AbstractService: Service:ThriftBinaryCLIService is started. 17/12/12 13:06:23 INFO service.AbstractService: Service:HiveServer2 is started. 17/12/12 13:06:23 INFO thriftserver.HiveThriftServer2: HiveThriftServer2 started 17/12/12 13:06:23 INFO thrift.ThriftCLIService: Starting ThriftBinaryCLIService on port 10000 with 5...500 worker threads
Now you can use this port number to connect with JDBC client. You can also try connecting with Beeline using jdbc:hive2:hostname:10000/db_name
- Client connection using Binary transport mode:
jdbc:hive2:hostname:10000/db_name
- Client connection using HTTP transport mode:
jdbc:hive2:hostname:10000/db_name;transportMode=http;httpPath=cliservice;
For HTTP transport mode, you also have to add the hive.server2.transport.mode=http property in your hive-site config file.
Creating a Pipeline in StreamSets Data Collector (SDC)
Now we are all set to run Hive queries on top of the Spark SQL engine. Let’s create a pipeline in SDC to find the average ratings for each movie and visually view the stats of the records.
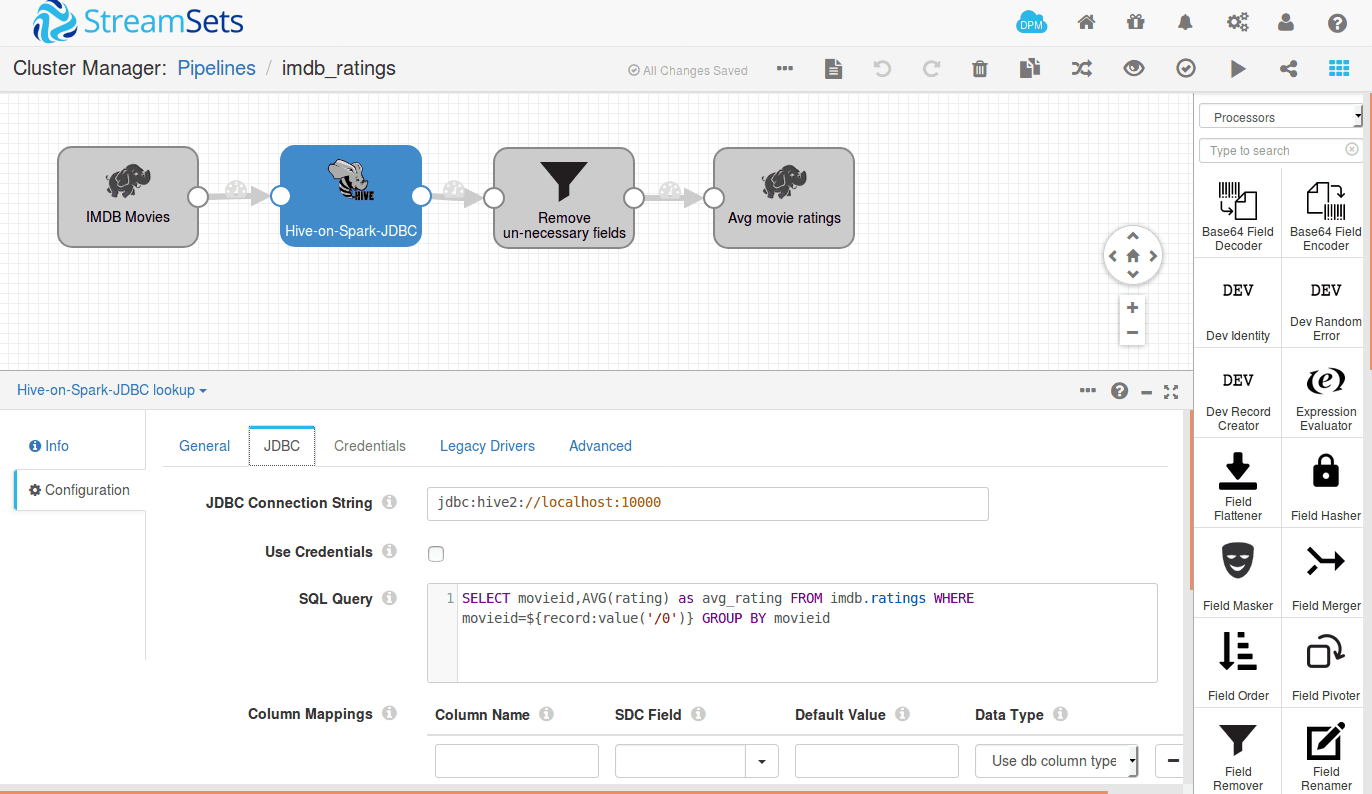
We have used HadoopFS for the pipeline origin since we have our data in HDFS, and JDBC-Hive Lookup as the processor. We’ll provide the required details to connect with the thrift server.
Note: as mentioned above, the StreamSets JDBC Lookup Processor does not support Hive/Spark JDBC clients, hence we have created our custom JDBC lookup processor to support Hive/Spark JDBC clients. Please refer to sections above to install the custom Hive JDBC processor before proceeding with the steps below.
Following is the query to find average ratings based on a specific movieID coming from the origin:
SELECT movieid,AVG(rating) as avg_rating
FROM imdb.ratings
WHERE movieid=${record:value('/0')}
GROUP BY movieid
Here ${record:value(‘/0’)} contains the movieID field coming from the previous stage. We are using the same to lookup on the ratings table in Hive.
The results from the JDBC lookup processor contain the fields that are coming from the previous stage and the fields selected from the table in the select statement, so we have used StreamSets’ field remover processor to remove unnecessary fields. The pipeline writes the results back to HDFS using the HadoopFS destination.
Live Run on StreamSets
The completed data pipeline in SDC looks like this:
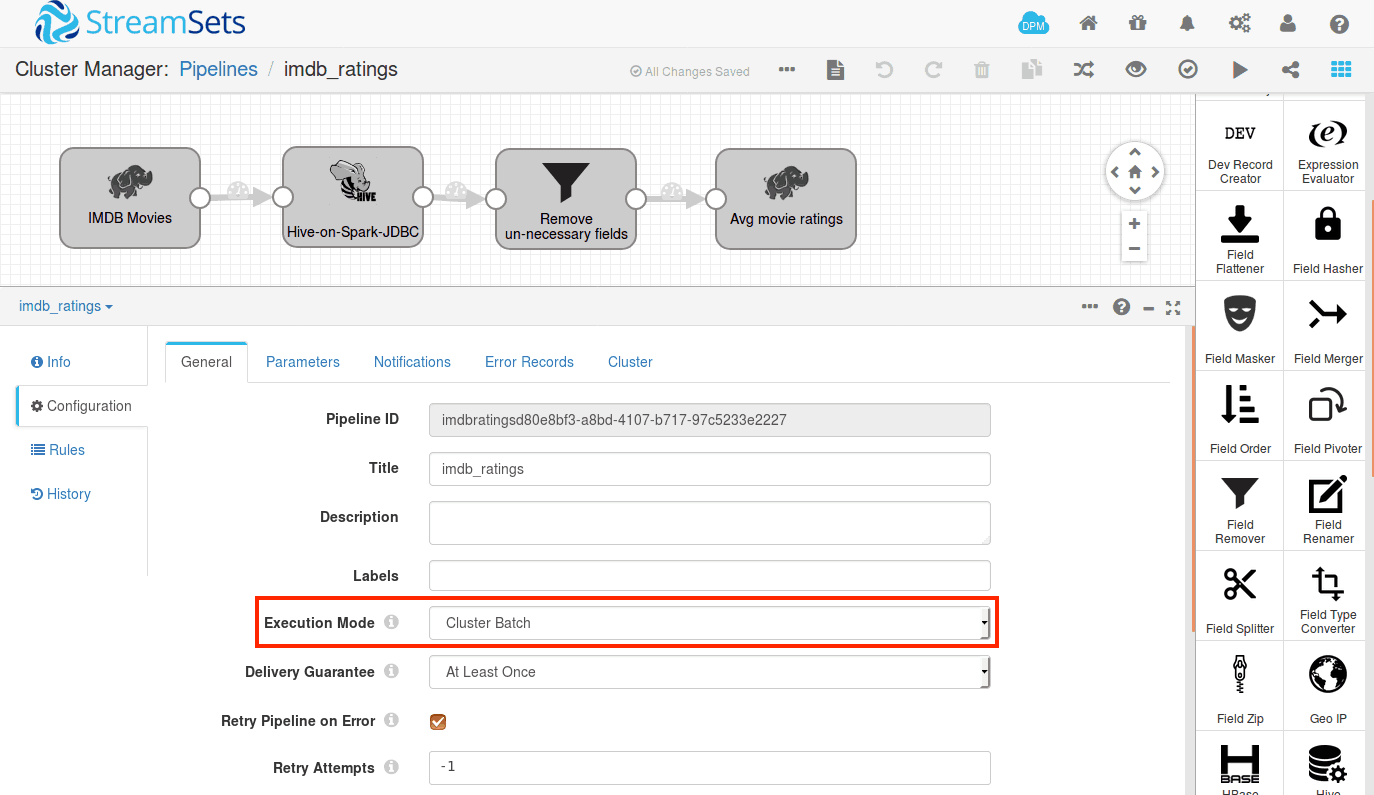
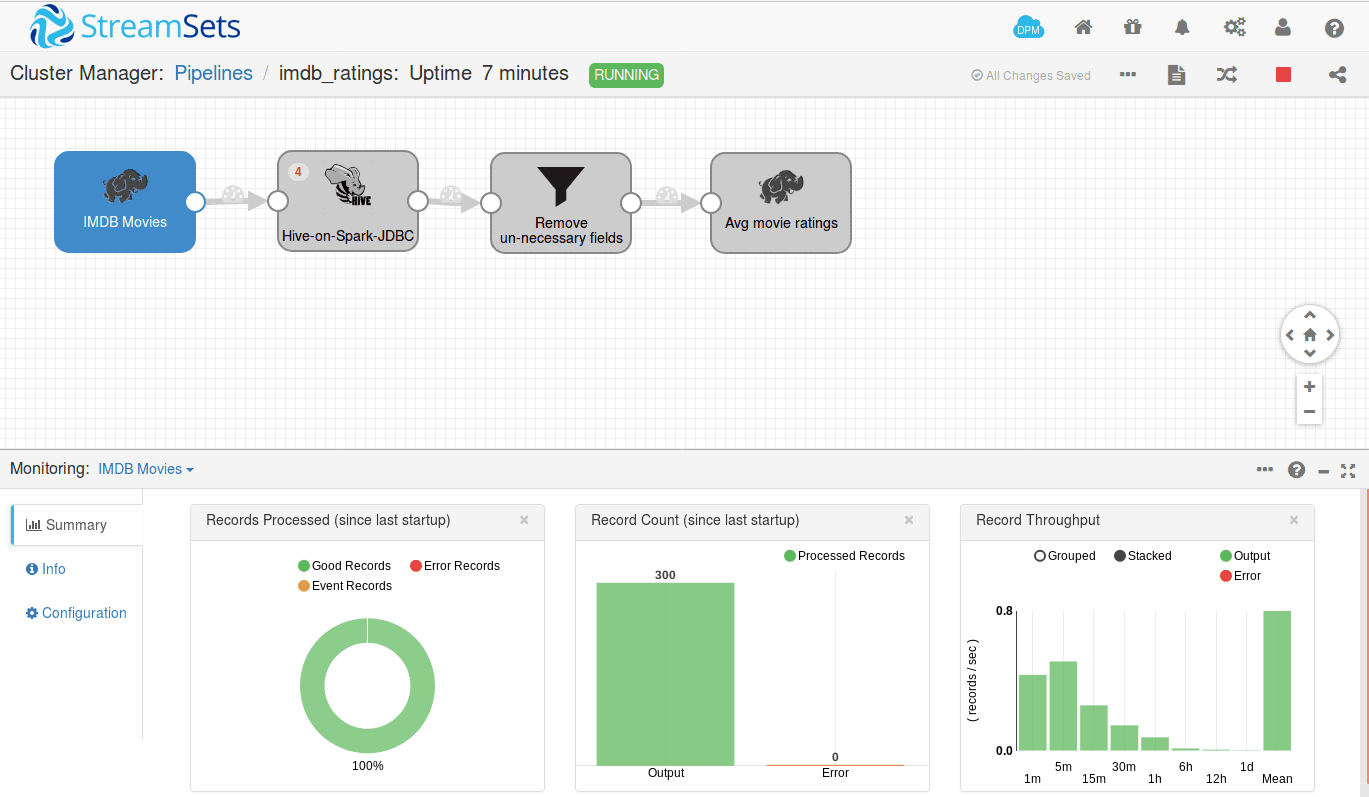
We can run this pipeline in cluster mode. StreamSets deploys a MapReduce application on YARN, and you can track the status of the application from your resource manager, and will get the stats of number of records processed in your pipeline itself.
Once we run the application, a MapReduce application will be launched with the name of your pipeline as shown below.
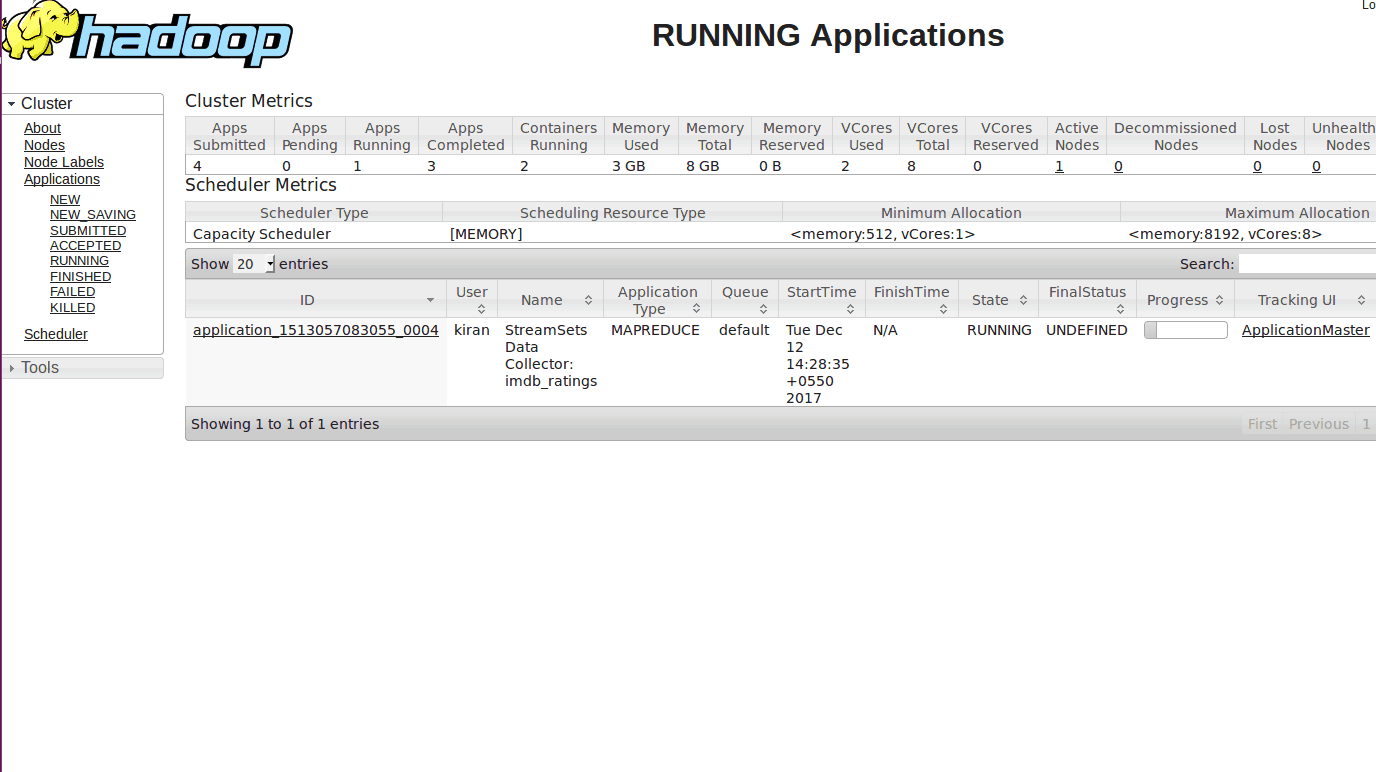
Once the job starts, several Map and Reduce tasks will run on behalf of your pipeline. You can see the live stats of the number of records processed in your pipeline summary as shown below.
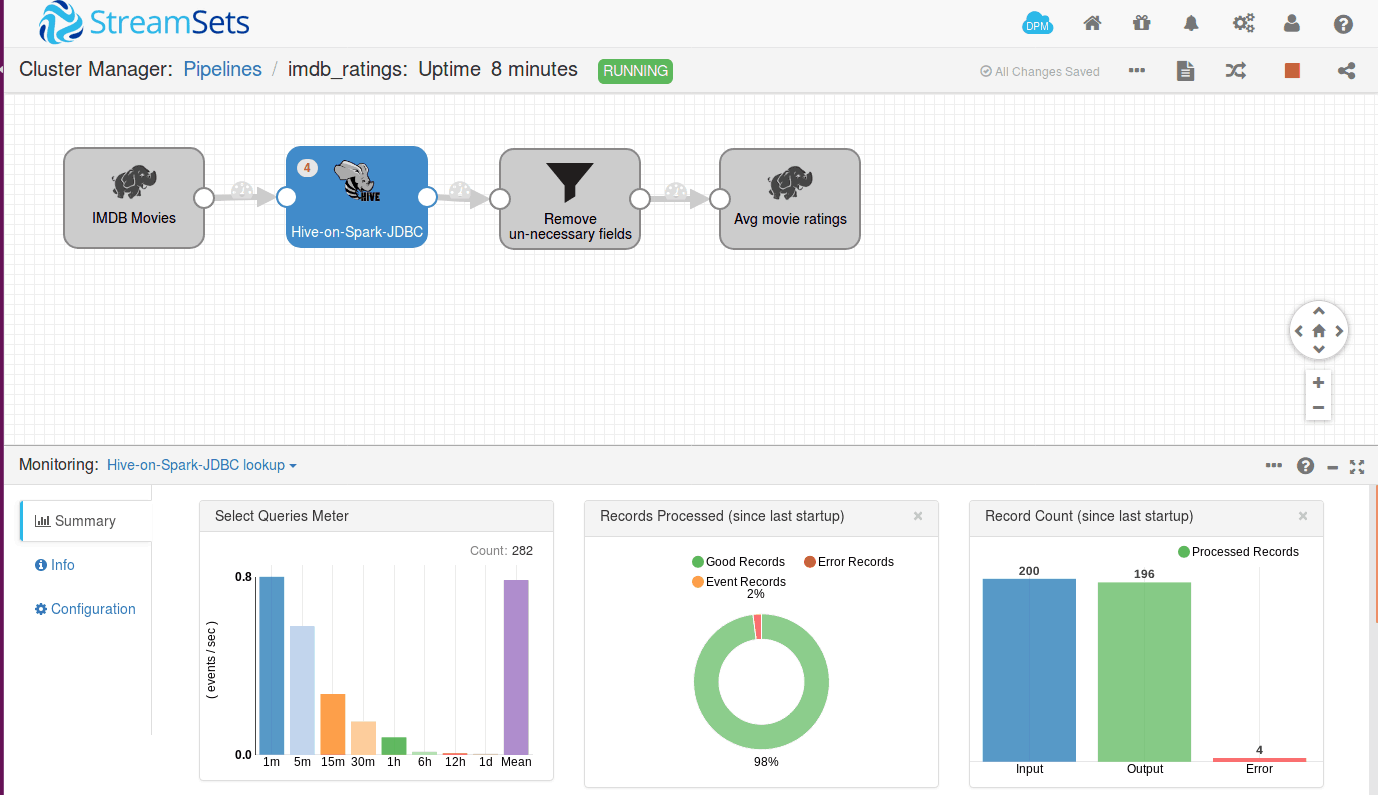
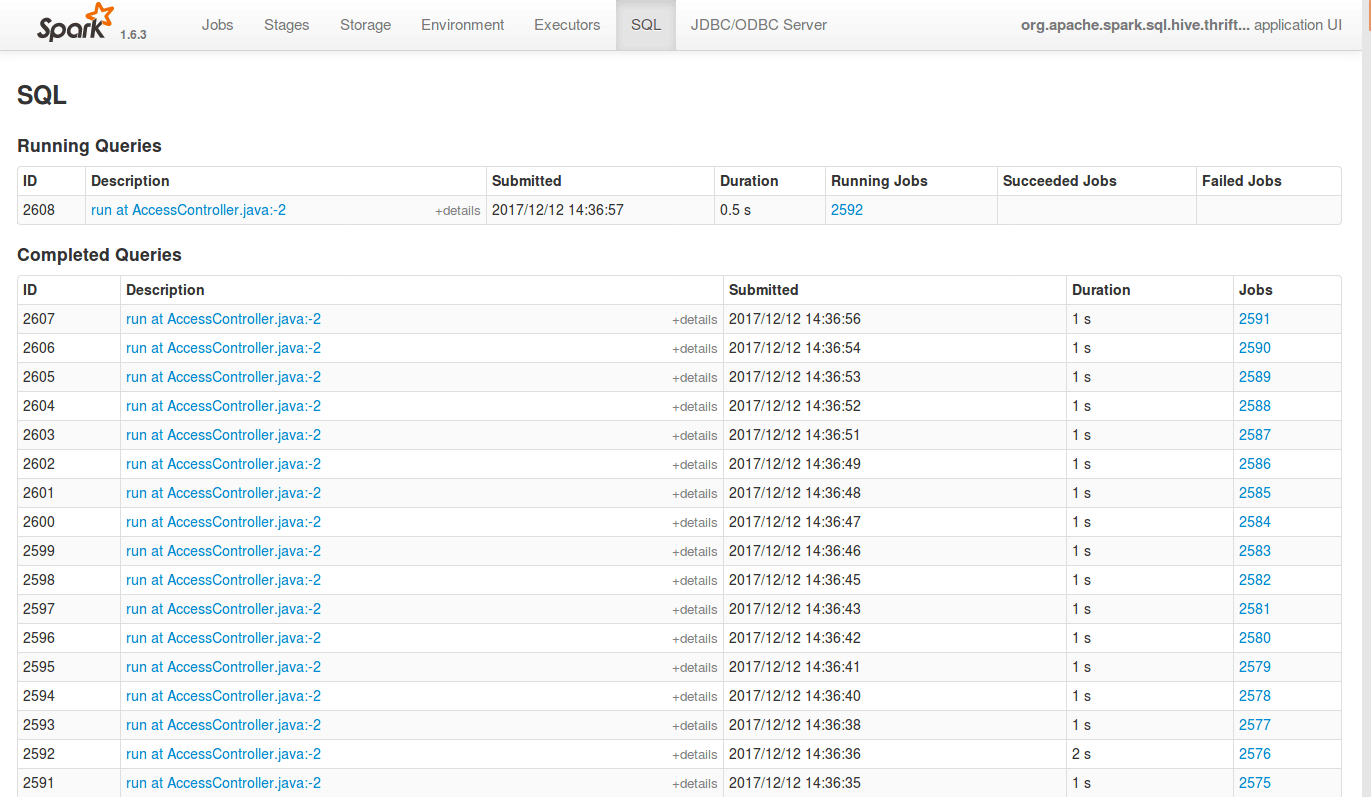
For each movieID, a Hive query will be launched and run using Spark SQL query engine; you can even track number of jobs launched from the Spark master URL as shown below.
The number of records to process at once depends on the size of each batch. You have to configure your batch size appropriately based on your cluster resource else your StreamSets application container will get killed.
Once the batch is processed, the records are sent to next stage. You can also see the number of records getting processed to the next stage visually, get the number of error records and can route them to another pipeline for debugging.
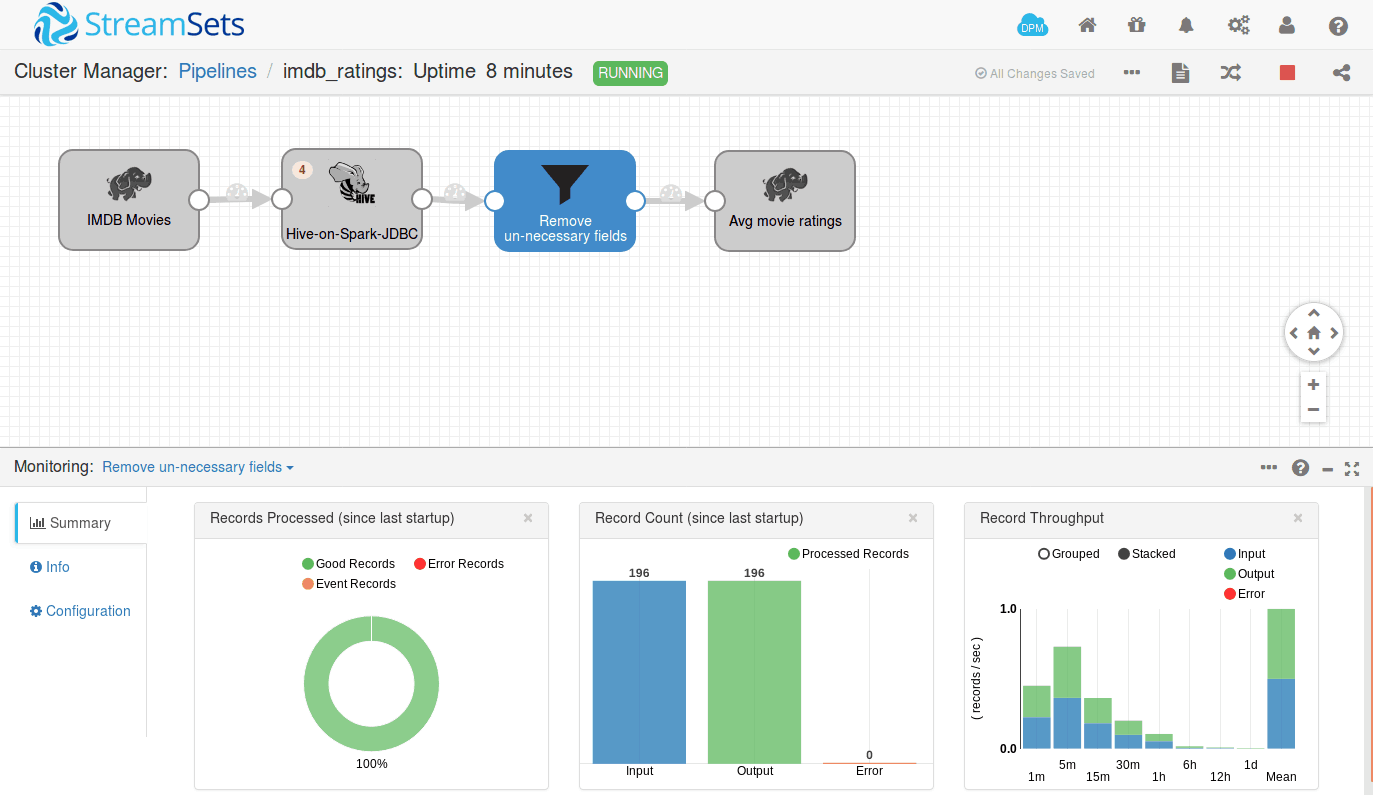
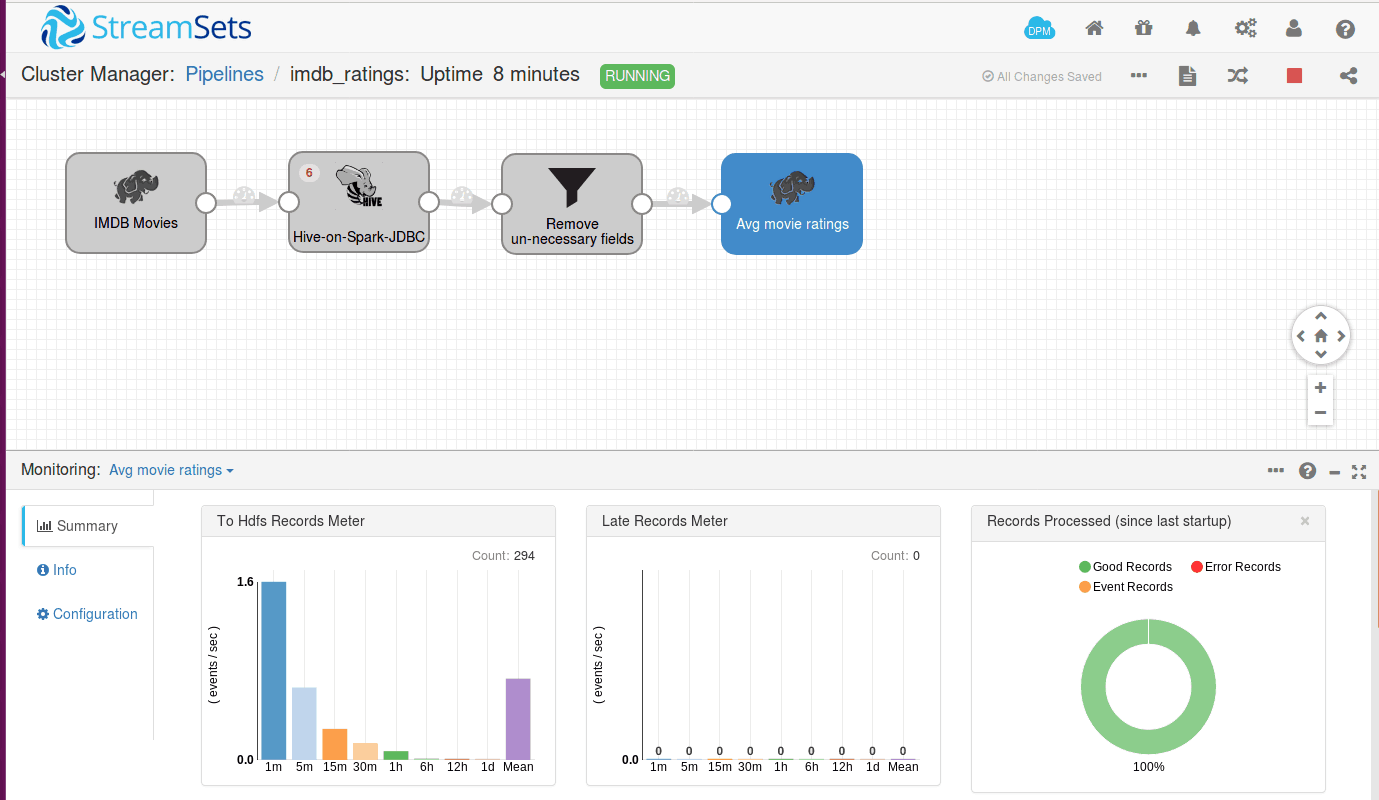
Once the records reach the destination, results are dumped either into filesystem or database or can be routed to some other place. Here we have used the HadoopFS destination. So we can have a look at the target directory for the results.
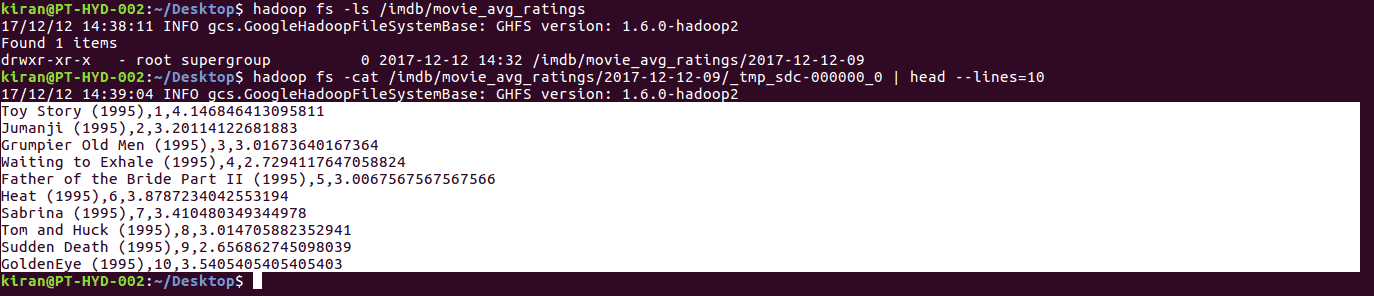
In the pipeline above, we have removed the extra fields and selected 3 fields as movieName, movieID, and avg_rating.
About Predera
Predera is building the industry’s first automation framework for monitoring and auto-managing cognitive apps. We enable continuous deployment, human-in-loop feedback, performance monitoring and autonomous management capabilities required to reduce the cost of maintenance of Artificial Intelligence models, which today requires teams of data scientists.
We partner with Data platforms (StreamSets is a partner) and ML platforms (Google cloud ML, H2O, Azure etc) and provide monitoring and insights for live machine learning models. We alert enterprises when their data, AI models and output need human intervention, tap into human expertise, and in some cases provide autonomous course-correction capabilities to reduce cost-effective maintenance of AI.