There are a couple of different approaches to SQL Server replication. I’ve always taken the common approach, one you’re likely very familiar with, Change Data Capture (CDC). In fact, I’ve written guides on CDC replication of other databases using StreamSets and how we do it with Microsoft SQL Server is very similar.
However, about a year ago I heard about Change Tracking. The typical, curious data engineer in me started doing research. I just had to know what it did and how it was different from CDC. Turns out, when SQL Server 2008 was released it contained both CDC and Change Tracking (CT) capabilities. Wild!
This was my perfect opportunity to dive in, learn something new, and share my findings with you.
In this post, I am going to cover the Change Tracking framework in Microsoft SQL Server, review the differences between CDC and Change Tracking, and show you how to use Change Tracking by replicating Microsoft SQL Server data into Snowflake.
SQL Server Replication: Change Tracking (CT) vs Change Data Capture (CDC)
Change Tracking is a feature that will return the net changes made to the data by a query. The ability to set up and configure Change Tracking is literally just a few queries and you are ready.
Change tracking does not:
- Tell you how many times the data has changed
- Provide a historical view of field values
- Return all of the changes that were committed for a given record
You will, however, receive an update that a record has changed and what operation was performed (i.e. INSERT, UPDATE, DELETE). For example, in the image below you can see what the query returns that shows us a change in my table Sales.
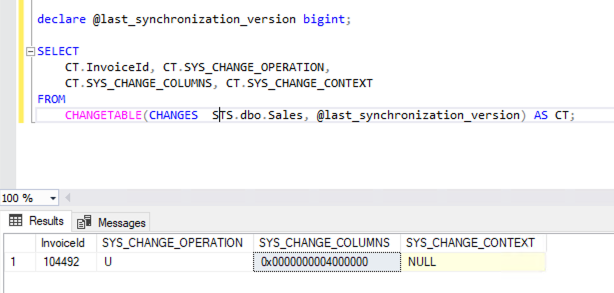
- SYS_CHANGE_OPERATION: This is what DML was performed on the record.
- SYS_CHANGE_COLUMNS: If the operation is of type UPDATE (U) this column will contain the similar value you see. It is a masked column that states which column(s) were updated.
This response will need to be joined back to the source table so that the data can be extracted and passed downstream. However, in the event of a DELETE operation, no data will be passed just the operation and primary key value for your downstream warehouse to act accordingly.
Change Data Capture is a much more involved setup and configuration and captures every single change that happens on a given record. It also creates a duplicate of your table with a few additional fields added to capture the CDC metadata.
For records that have an UPDATE DML operation, two records are inserted in the CDC table. One record will contain the before snapshot of the data and then an after snapshot of the same record with the changed data. This can drastically increase the amount of storage required by your database, especially in a very busy environment. However, if you need to process every change in detail then CDC is the best option for you.
Using Change Tracking (when CDC functionalities are not required) provides the following advantages:
- Reduced Complexity
- Reduced Storage
- Reduced Implementation
- Reduced Maintenance
- Faster Go Live
Yes, you still have to query the source table to get the data; however, you are doing so in a very prescriptive manner instead of blindly querying the entire table looking for all records that a single column changed. We can now say give me all records that have their Primary Key in this bucket.
SQL Server Replication: Environment Configuration and Setup
My environment consists of the following:
- Server: 8 CPU and 32 GB Ram
- Storage: 128 GB SSD
- OS: Windows Server 2019 Datacenter
- Database: SQL Server 2017 Enterprise
Let’s dive into the fun part – let’s get your environment setup and configured for SQL Server replication with the following steps. You can find the example dataset, StreamSets pipelines, and DDL scripts I use here.
- Execute the sqlserver.sql script in your SQL Server database to create the Sales table
- Import the Sales_202205251127.sql that will create 400 +/- records
- In your Snowflake environment (if you do not have one, use their 30-day trial) execute the snowflake.sql to create the Sales table
- Import both of the zip files into your StreamSets account
- Set up the SQL Server database and table(s) for Change Tracking
- Use the following code to enable Change Tracking at the database level, set the retention time (in our case 2 days), and enable auto_cleanup. You will need to determine the proper retention frequency based on your needs.

- Use the following code to enable Change Tracking at the database level, set the retention time (in our case 2 days), and enable auto_cleanup. You will need to determine the proper retention frequency based on your needs.
- Enable change tracking for each table.
- The track_columns_updated = on the statement will cause the database engine to store which columns were updated. (See SYS_CHANGE_COLUMNS in the image above)

- The track_columns_updated = on the statement will cause the database engine to store which columns were updated. (See SYS_CHANGE_COLUMNS in the image above)
- Grant view change tracking on each table to our user that will be executing the queries from our StreamSets Change Tracking pipeline.

You can read more about these steps from the Microsoft documentation here.
Executing Change Tracking with StreamSets
Initial Sync
Typically in replication projects, you first want to move all the data you have from your source database to your target.
Let’s take a quick look at the MSFT_SALES_STS_INIT pipeline that we imported. It is a very simple and straightforward pipeline. All we want it to do is extract and load the data. The Executor stage is used to detect when the result set from our query has been completed and, upon detection, shut down the pipeline.
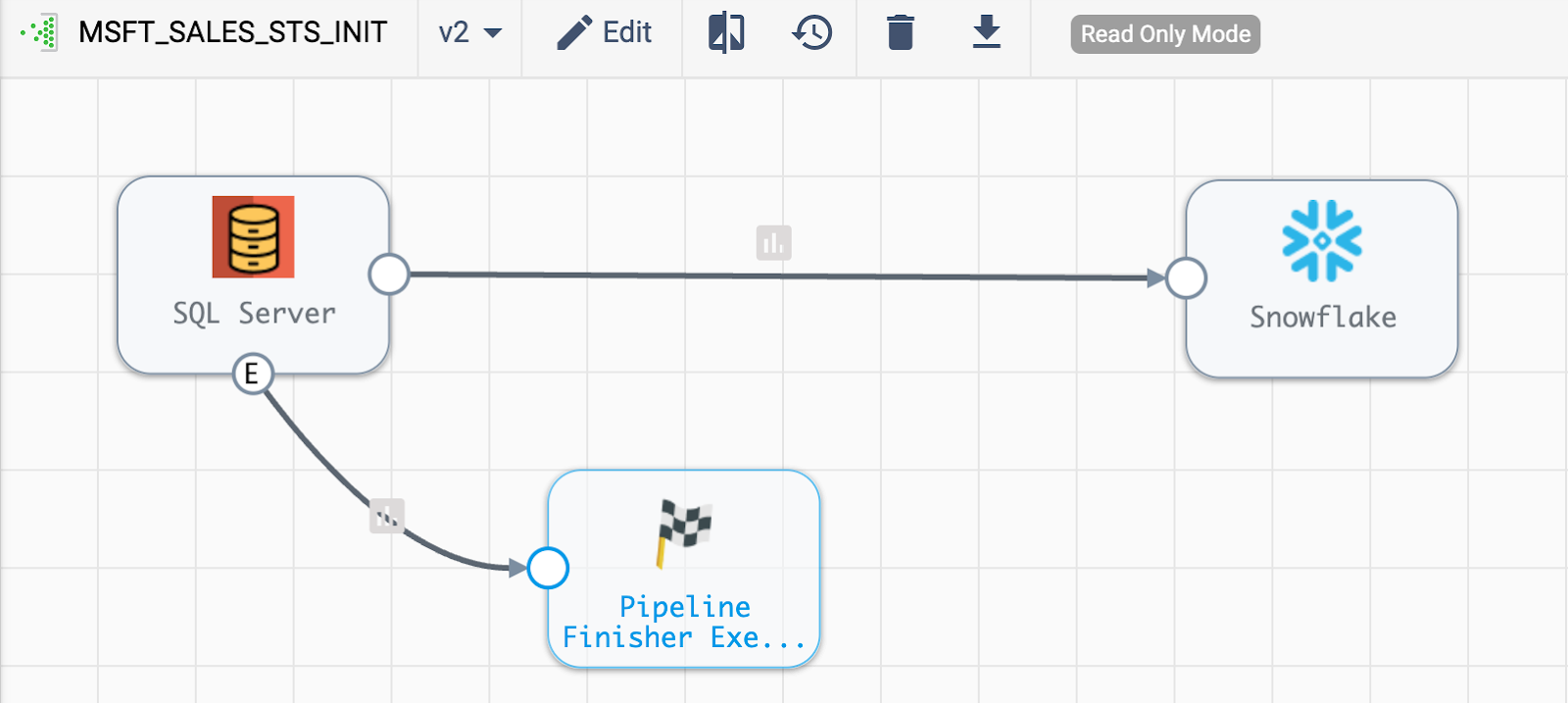
Produce Events: Make sure this is selected (set to true)
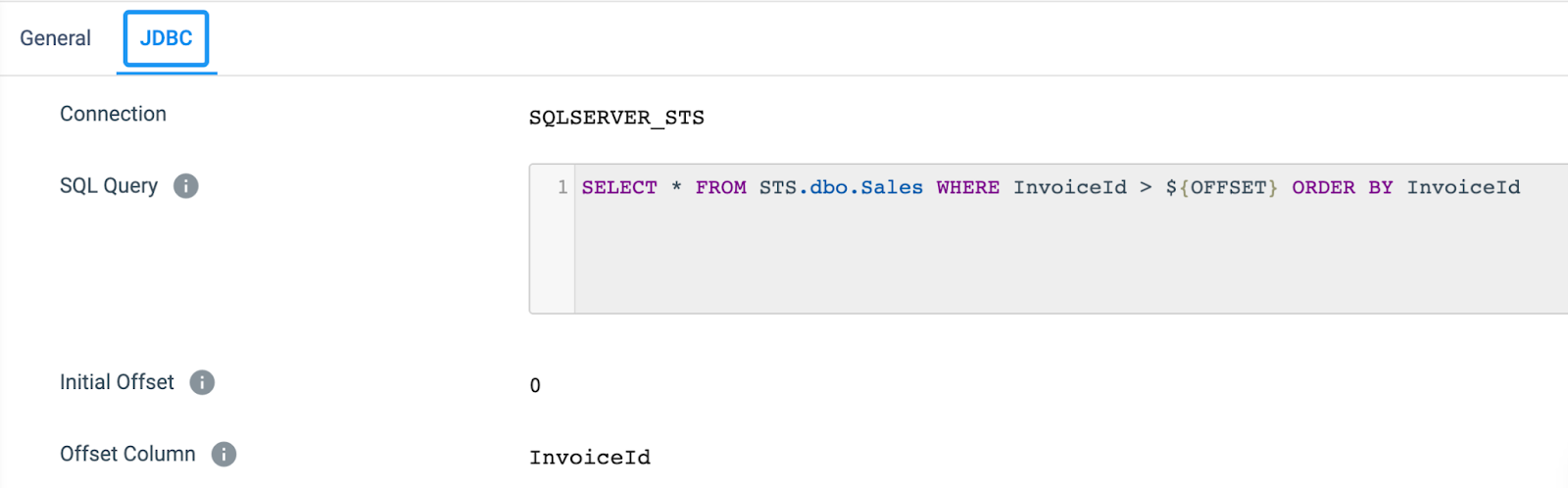
SQL Query: Since we are only going to run this once for the initial load, we don’t need the Offset Column set or in the Query. I put it here just in case you would like to see how this works or to use if you do have a use case that requires the use of Offset.
Offset Column: InvoiceId is our PK from the source so that is what I am using. However, you may want to use something like a timestamp column if you have one.
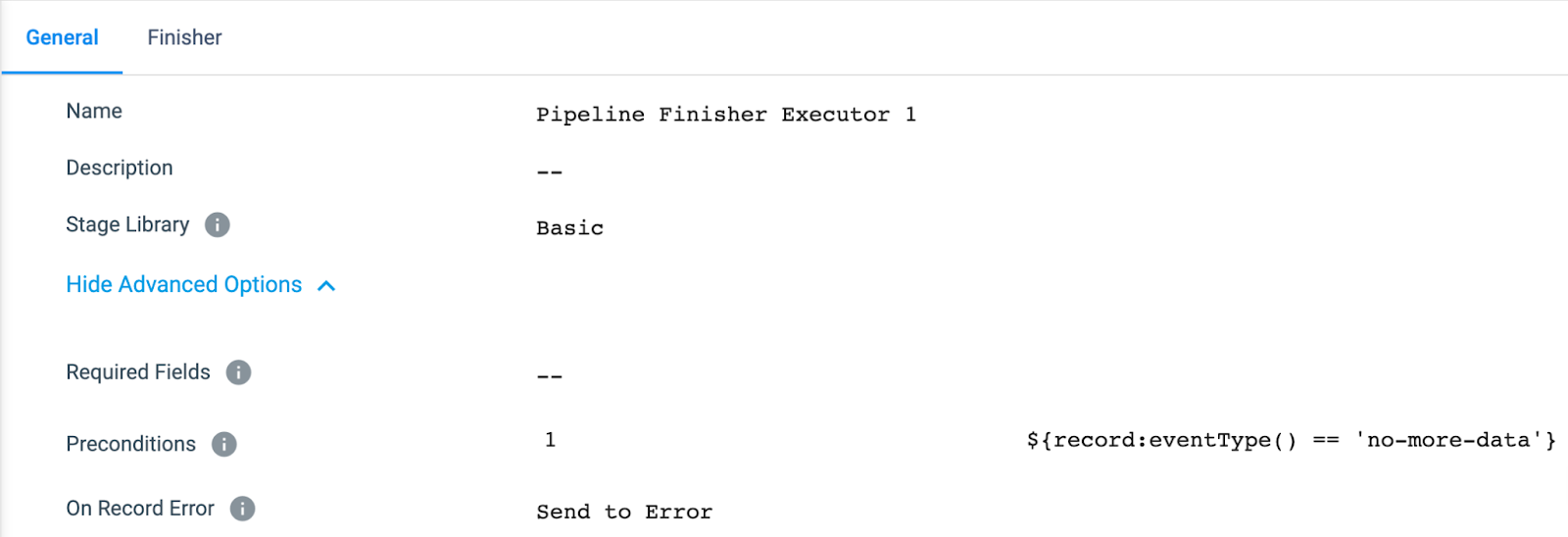
To set up our Finisher Executor stage, we only need to set up a Precondition of the following:
Precondition: ${record:eventType() == ‘no-more-data’}
This will make sure that our pipeline shuts down properly after processing all the data from the source.
Processing Change Data
Now we are ready to stream our change records over to our Data Warehouse. In this example, we are using Snowflake. Let’s do a quick walk through our Change Tracking pipeline.
SQL Server Change Tracking (Origin)
![]()
I am leaving everything as default in the Origin for this exercise. However, I did want to point out a few properties in the configuration settings.
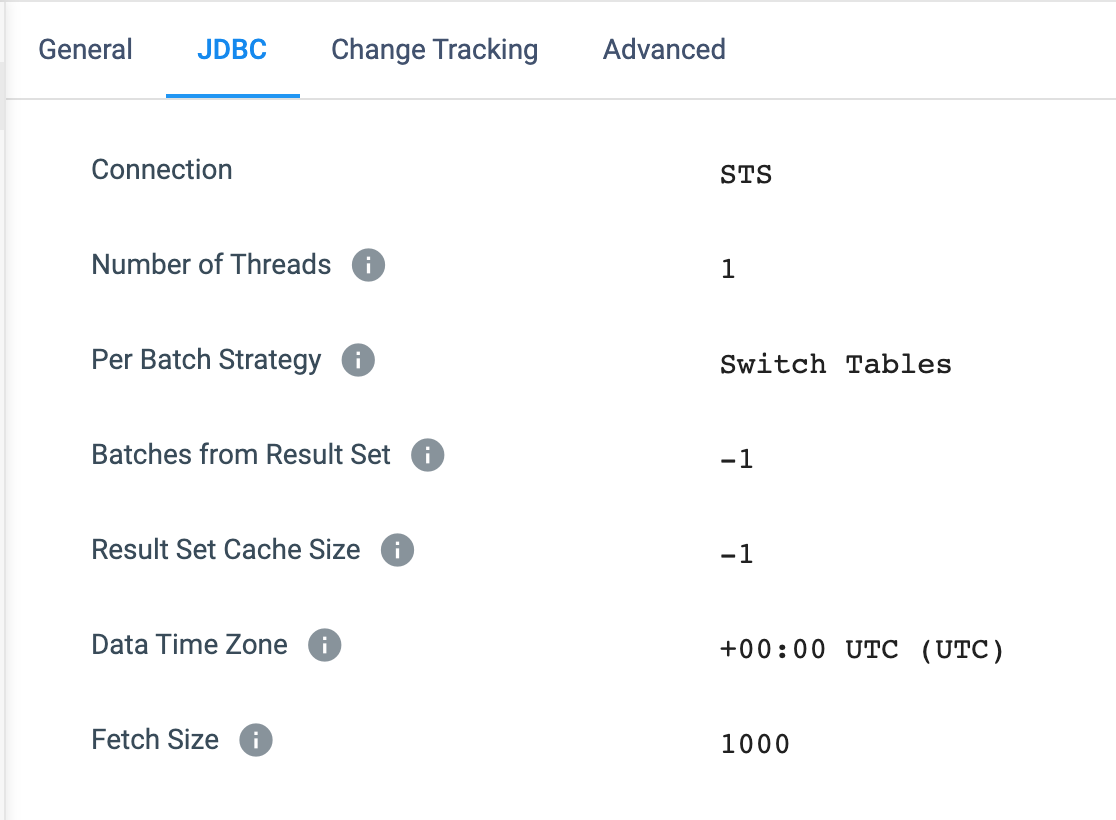
- Number of Threads: The value that you place here must be equal to or less than the Maximum Pool Size property in the Advanced Tab.
- Per Batch Strategy: There are two options to choose from.
- Switch Tables (Default): When multithreaded threads will process a batch of data then switch to the next available table. The driver caches the remaining records until the same thread comes back around.
- Process all available rows from the table: Each thread will process all the data for a given table before moving on to the next available table.
![]()
The Change Tracking tab allows you to add multiple schemas from the database you used in the connection. By default, dbo is set for you.
- Schema: The name of the schema for the Origin to look in for tables
- Table Name Pattern: (% – Default is everything)
- Table Exclusion Pattern: Very beneficial as you can determine if it is better to exclude everything and only include a few or include everything and exclude a few. Otherwise, you would have to enter each table separately and that would not scale as your database grew nor would it be very fun to maintain
- Initial Offset: (-1) Default value turns this off and you will only process with new incoming changes.
Snowflake (Destination)
For our Snowflake destination, I wanted to touch on a couple of the configurations.
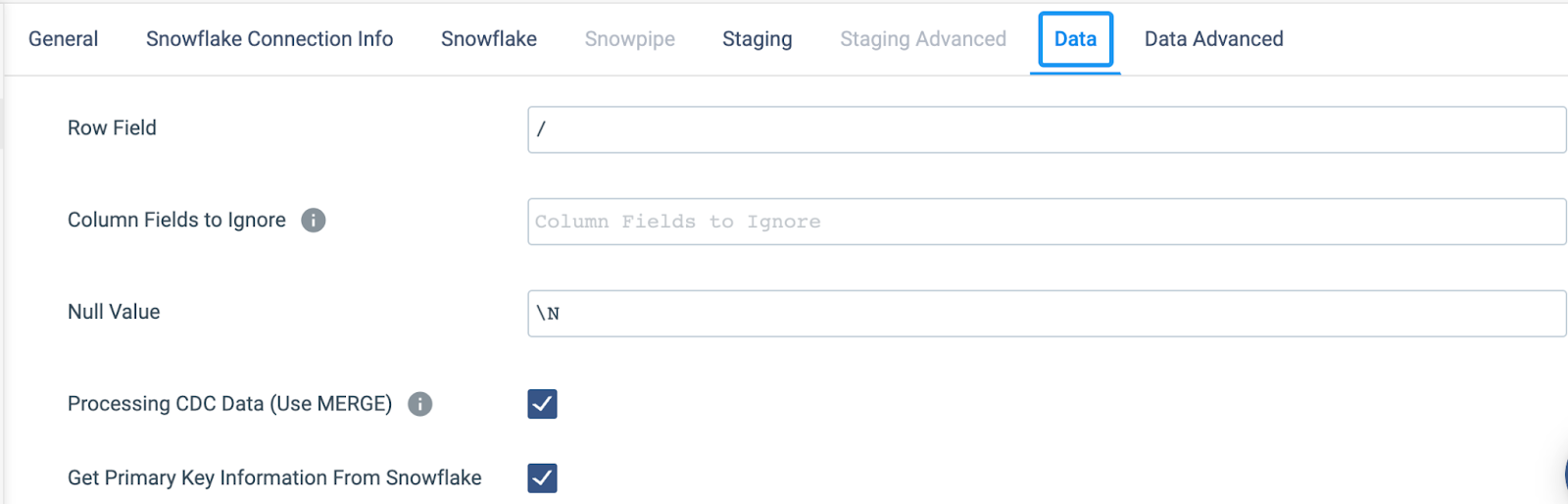
- Processing CDC Data (Use MERGE): This tells the destination to look at the incoming data for the metadata fields that contain the DML operations.
- Get Primary Key Information From Snowflake: Since our DDL for the Snowflake, the table has a primary key set we can have the destination pull this dynamically from the database. However, if your destination table does not have a primary key setup there is an option to enter them in manually.
You may be wondering why the Change Tracking pipeline is simply pushing data over to Snowflake and not really doing anything with the data prior to SQL Server replication. That is a very solid question.
If you do need to enrich the data before landing it, consider the following approach.
Streaming raw data into Snowflake allows you to utilize your Snowflake environment to autoscale the processing of your data. With StreamSets’ Transformer for Snowflake, you can build complex pipelines that run at scale on your Warehouse without any of the data ever leaving your Snowflake environment, creating a highly performant and secure framework for your enterprise. Get a StreamSets demo to give Transformer for Snowflake a try.
Conclusion
Although I had used CDC in the past, thinking back to almost all of the projects I was involved with utilizing CDC for SQL Server, only one or two actually required it.
The remainder would have benefited from simple Change Tracking. In these projects, we only cared that a given record was changed and either 1) did not have a timestamp on the table that was updated for every operation or 2) did not want to put that kind of load on the database by always querying the timestamp column.
Needless to say, I’m really excited about what I’ve learned throughout my research and will consider Change Tracking when thinking of CDC in the future. I encourage you to do the same.
