Data movement forms a crucial aspect of data management and occurs via different methods, depending on the reasons for the move. One common method is data migration from a source to a target destination. Migration destinations may include database systems, data warehouses, or data lakes and involve the help of migration tools.
Data lakes have become a popular destination for businesses to store their data because of their flexibility, low storage cost, and ability to store different data types and formats. One popular way to build a data lake is using AWS Simple Storage Service (S3). Amazon S3 is an object storage service that stores massive amounts of data as objects and scales with demand at an economical cost. S3 can also easily connect to multiple database systems, like SQL servers and Oracle, offering the flexibility most data-driven organizations require today.
Let’s explore a simple data migration from an SQL server to Amazon S3 using the AWS Database Migration Service (DMS)
Why Move Data from SQL Server to S3
A business may decide to move its data residing on its SQL servers to an Amazon S3 bucket for any of the following reasons:
- To create a robust data lake: Amazon’s S3 bucket storage is an excellent solution because of its scalability, flexibility, availability, security, and cost-saving features. Building a data lake on S3 enables organizations to maximize their data in machine learning (ML), Artificial Intelligence (AI), and analytics.
- Backups for disaster recovery: Data loss from natural disasters or breaches can ruin businesses. S3 buckets have redundant architectures through cross-region replication, which are excellent for backups in data recovery cases.
- Data archives: S3 bucket storage has various levels for storing data, depending on the use case. For example, S3 Glacier is optimal for long-term storage, enabling organizations to store business data for extended periods.
- System modernization: Organizations may take advantage of the cloud’s cost-savings, security, and easy scalability benefits and migrate their database services from an on-premise system to an Amazon S3 bucket.
In all of these cases, the reason for migration determines the steps to follow. For example, you can load raw data without transformation for data lake migration. However, some cases may need data transformation before loading.
Sending Data With AWS Database Migration Service (DMS)
The AWS DMS is a migration tool for data migrations. It helps businesses replicate and migrate their database workloads to AWS services with minimal downtime and no data loss. However, this migration requires prior knowledge of AWS services. For example, migrating from a SQL server to an S3 bucket follows an 8-step process:
- Connecting to an EC2 instance
- Configuring the source database for replication
- Creating a DMS replication instance. The replication instance sits between the source and target destination, helps read the data from the source data store, and formats it for loading into the S3 bucket.
- Configuring the target S3 bucket. This configuration may involve creating an S3 bucket and setting policies for access and security.
- Creating DMS source and target endpoints
- Creating a DMS migration task. This step moves the data from the source to the target destination.
- Inspect the content in the S3 bucket.
- Replicate the data changes. In this step, you can view how the AWS DMS automatically replicates data changes made to the source database on the target S3 bucket.
As seen above, sending/replicating your SQL server data using AWS DMS involves multiple steps. It also requires prior technical knowledge of AWS services like EC2, IAM policies, and buckets, which may be difficult for individuals with limited technical knowledge.
Connecting SQL Server to S3 With StreamSets
StreamSets helps shorten the number of steps and technical steps required to migrate data from your SQL server to the AWS S3 bucket. StreamSets enables this migration with its reusable connectors in four simple steps. First, you need your login credentials and configuration details for your source and destination data store to start.
- Create a source and target database using the SQL server connector. The SQL server becomes the source in this case, and the AWS S3 bucket is our target database.
- Enter your login details.
- Configure your data fields.
- Configuring your origin: Configuring your source involves specifying connection information to connect the origin to the SQL Server 2019 BDC Multitable Consumer origin. Here you also define your tables and schema and construct your SQL query.
- Configuring your destination: Configuring your AWS S3 destination involves specifying the region, bucket, and the common prefix that helps define where to write objects. You also need to configure the authentication method. Connecting to public buckets requires no authentication, but authentication using an instance profile or AWS access keys is necessary for private buckets.
After configuration, your pipeline will look like this: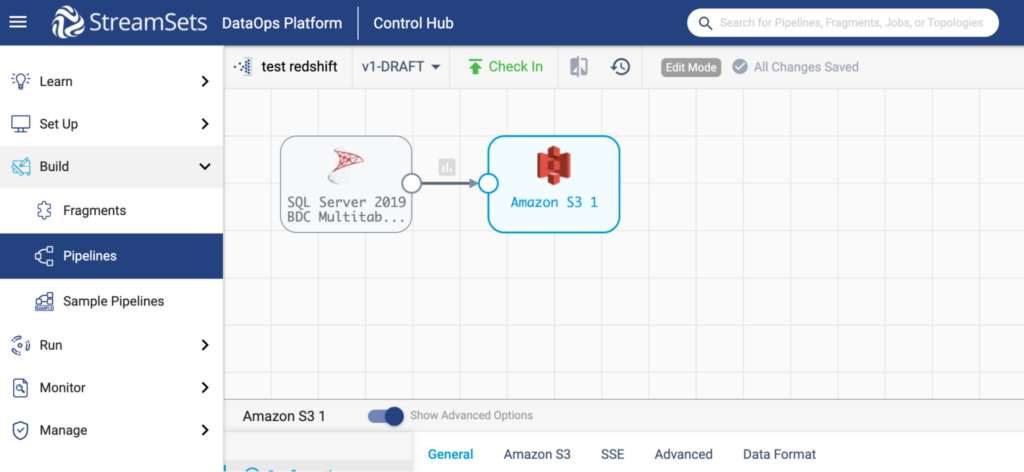
Depending on the goal of moving your data, you can configure some processors to help transform/modify your data before loading it into S3. Two popular processors are the expression evaluator and the field masker.
The expression evaluator uses StreamSets expression language to perform calculations on defined data fields and writes the results to the new or existing data fields.
Another processor, the field masker, helps mask string values depending on the selected mask type. Mask types include variable-length, fixed-length, or regular expressions. The field masker can help hide sensitive data like Personal Identifiable Information(PII), like some digits of social security numbers or phone numbers.
A sample migration from an SQL server to S3 with the expression evaluator and field masker looks like this: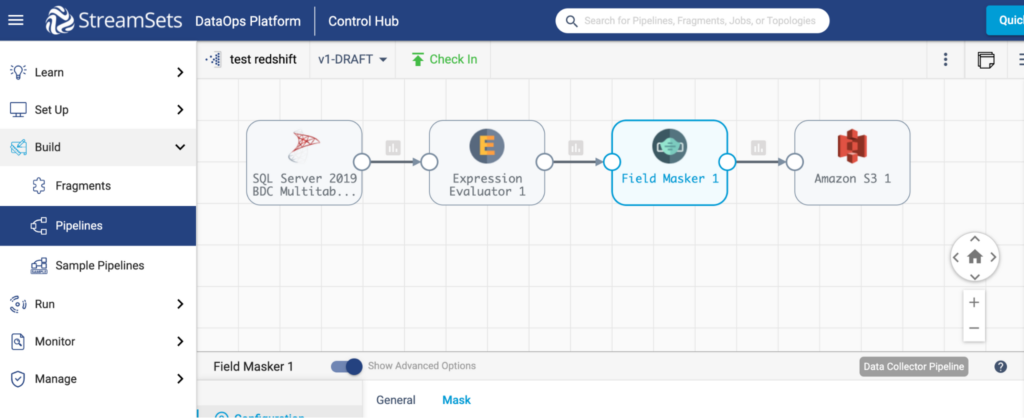
- Start migrating your database. After configuring your resource and destination database, you can start migrating your database.
Simplifying Data in Motion
Data movement between systems or databases is crucial to data management. However, this migration process can sometimes be time-consuming, involving multiple-step processes requiring proficient technical knowledge.
Thanks to StreamSets, migrating your data becomes more manageable. By using StreamSets connectors, you can create reusable pipelines to easily connect and migrate your data. Additionally, the reusable pipeline components can feed data into other analytical processes, improving the scalability and accessibility of data processes. Easier access to data empowers more users to utilize the data for making better-informed business decisions.
