 A couple of weeks ago, as May the 4th approached, a lively Star Wars debate brewed at StreamSets:
A couple of weeks ago, as May the 4th approached, a lively Star Wars debate brewed at StreamSets:
- “Do new school characters get as much play as old favorites like Darth Vader, Yoda and Han Solo?”
- “Does the Dark Side of the Force dominate the Light?”
- “Does Yoda prevail over Darth Vader?”
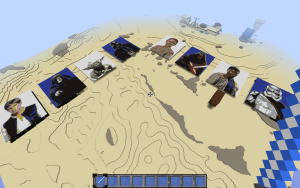
It occurred to us that, with the Twitter Streaming API and StreamSets Data Collector, we didn’t have to guess or debate. We built a data flow that ingested and analyzed tweets and then displayed them in… Minecraft!
Watch this video to see characters grow out of the sands of Tatooine as they are mentioned:
How We Built a Data Flow for Analyzing Star Wars Twitter
Since the on-demand Twitter REST API is fairly limited in terms of the volume and completeness of data it provides, the first order of business was to deploy SDC to a ‘t2.small’ AWS EC2 instance and create a pipeline to collect tweets from the Twitter Streaming API. This API provides the full text and metadata of every tweet matching a given filter; around a tweet every second or two for the #starwars hashtag at peak times.
The HTTP Client origin in stream mode is a perfect match for streaming APIs such as Twitter’s. It took about five minutes to create a Twitter application ID and secret, issue an auth token and secret, and configure the origin to start collecting JSON tweet data, Since SDC was running on EC2, S3 seemed a natural store for raw tweet data, so we just hooked the HTTP Client origin directly to an Amazon S3 destination.
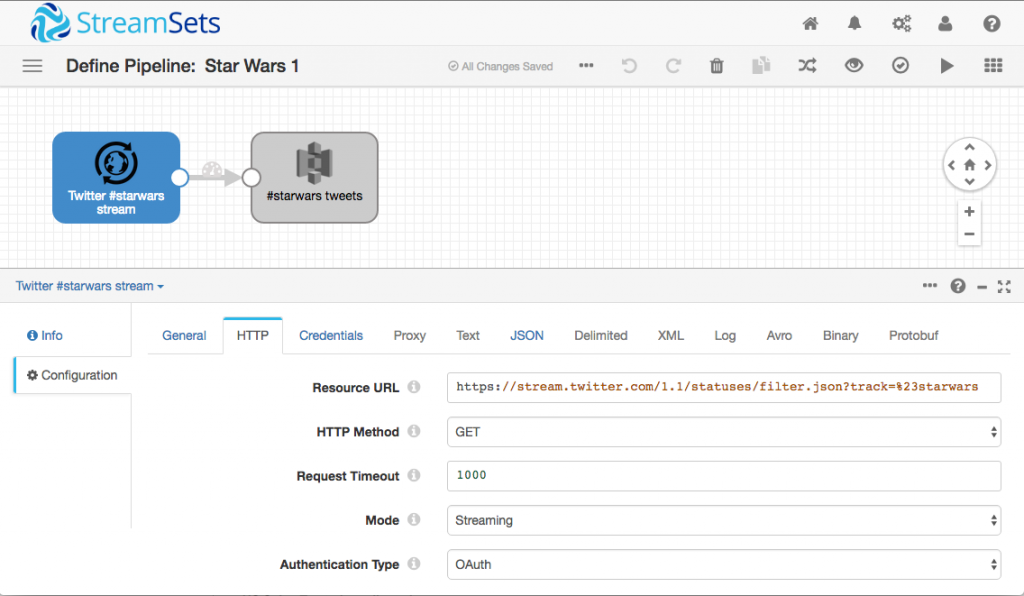
Over the course of about 12 days, we collected 250,000 tweets, writing 1.2GB of raw JSON data to S3.
With tweet collection taken care of, we turned our attention to processing the tweet data. As tweets arrived, we could see that many were fairly generic, and didn’t mention a particular character. What we needed was a way to reliably extract mentions of specific characters. For instance, we wanted mentions of ‘Han’, ‘Solo’ and ‘HanSolo’ to all show up in Han’s count, but not tweets containing words such as merchandise or changes. As is so often the case in computer science, regular expressions held the answer.
We created a second pipeline to read from S3, and categorize tweets according to mentions of characters representing old and new school, and the dark and light sides of The Force:
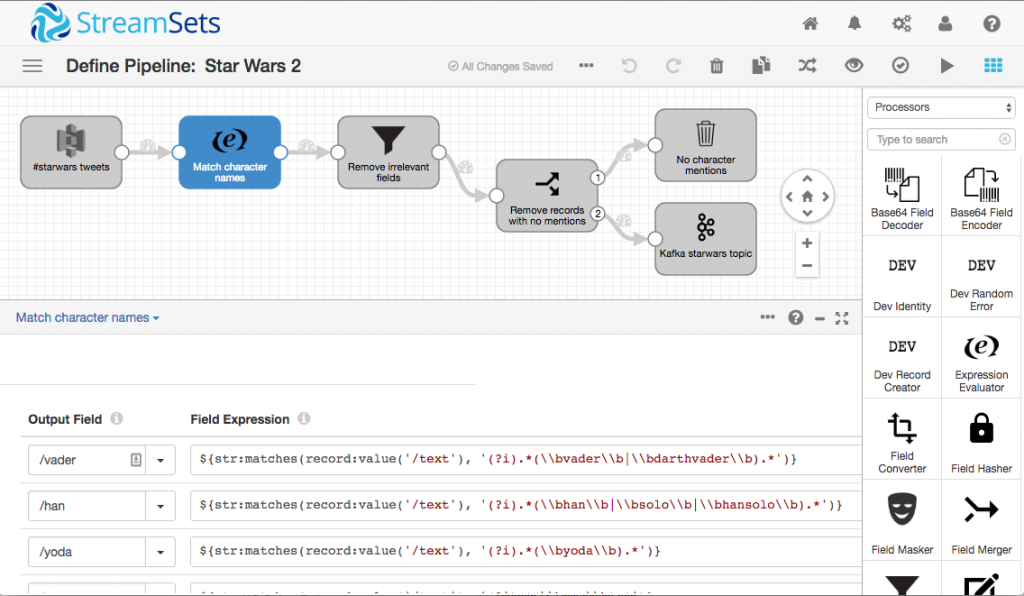
That pipeline is a little more complex, but we can break it down, stage by stage:
- An Amazon S3 origin reads and parses the stored JSON-encoded tweets
- Next, the Expression Evaluator looks for matches on a set of configured regular expressions. Looking at the second field expression:
${str:matches(record:value('/text'),'(?i).*(\\bhan\\b|\\bsolo\\b|\\bhansolo\\b).*')}This will perform a case-independent match on any occurrences of
han,soloorhansoloas whole words. It’s important to specify the word boundaries with\\b, so that you don’t match substrings in longer words such as merchandise. The expression evaluator creates a boolean field for each character we’re looking for. - Now we’ve found character mentions, we can remove unneeded data (i.e. tweets not mentioning any character). First, we remove all but the boolean character match fields, then we filter out records where all of our boolean fields are false. This results in a stream of records of the form:
{ "finn": false, "han": true, "kylo": false, "palpatine": false, "phasma": false, "rey": false, "vader": false, "yoda": false } - Finally, we write the processed records to an Apache Kafka queue.
This video walks through the two pipelines in a little more detail:
With StreamSets Data Collector writing the processed records to Kafka, we moved to the final step: creating a 3D visualization of the data in Minecraft!
We took a Minecraft image rendering plugin and added a Kafka Consumer, so that it could render images of the different characters as blocks in the Minecraft world as it received mentions of them. At this point, it’s much easier to show you the result, rather than explain in text…
So, without further ado, ladies and gentlemen, we are proud to present, the 2016 StreamSets May the 4th TweetOff!
While analyzing Star Wars Twitter is a fun example of data integration, it does illustrate many interesting features of StreamSets Data Collector and pipeline design. Buffering the raw JSON tweet data in S3 allowed us to experiment with the processing without missing any incoming data. The second pipeline filtered 250,000 incoming records, or 1.2GB, of raw JSON data to 33,620 outgoing records, writing just 3.6MB to Kafka.
Here are the results in a more conventional form:
By character:
| Darth Vader | 12967 |
| Yoda | 9736 |
| Han Solo | 5616 |
| Kylo Ren | 5456 |
| Rey | 5009 |
| Finn | 1771 |
| Captain Phasma | 855 |
| Emperor Palpatine | 721 |
By Allegiance:
| Light: | 22,132 (52%) |
| Dark: | 19,999 (48%) |
By Vintage:
| Old school: | 29,040 (69%) |
| New School: | 13,091 (31%) |
We can see that Vader easily wins, followed by Yoda and Han, but, looking at the sides of The Force, the Light Side prevails, though just barely. Finally, Star Wars fans still tweet about the original characters much more than the new faces introduced in The Force Awakens, by a margin of more than two to one!
What questions can StreamSets Data Collector answer for you? Download it today and get to work!
Credits
- Minecraft by Notch
- Art Generator Minecraft plugin by Sakura Onishi
- Tatooine map by Derentis
- Mine Wars texture pack by yokoolio