Learn how to load a serialized Spark ML model stored in MLeap bundle format on Databricks File System (DBFS), and use it for classification on new, streaming data flowing through the StreamSets DataOps Platform.
In my previous blogs, I illustrated how easily you can extend the capabilities of StreamSets Transformer using Scala and PySpark. If you have not perused blogs train Spark ML Random Forest Regressor model, serialize the trained model, train Logistic Regression NLP model, I highly recommend it before proceeding because this blog builds upon them.
Ok, let’s get right to it!
Watch It In Action
If you’d like to see everything in action, checkout this short demo video—there’s no audio though… please continue reading this blog if you’d like to know the technical details. :)
Streaming Data: Twitter to Kafka
I’ve designed this StreamSets Data Collector pipeline to ingest and transform tweets, and store them in Kafka. This pipeline is the main source of our streaming data that we will perform sentiment analysis on in the second pipeline.
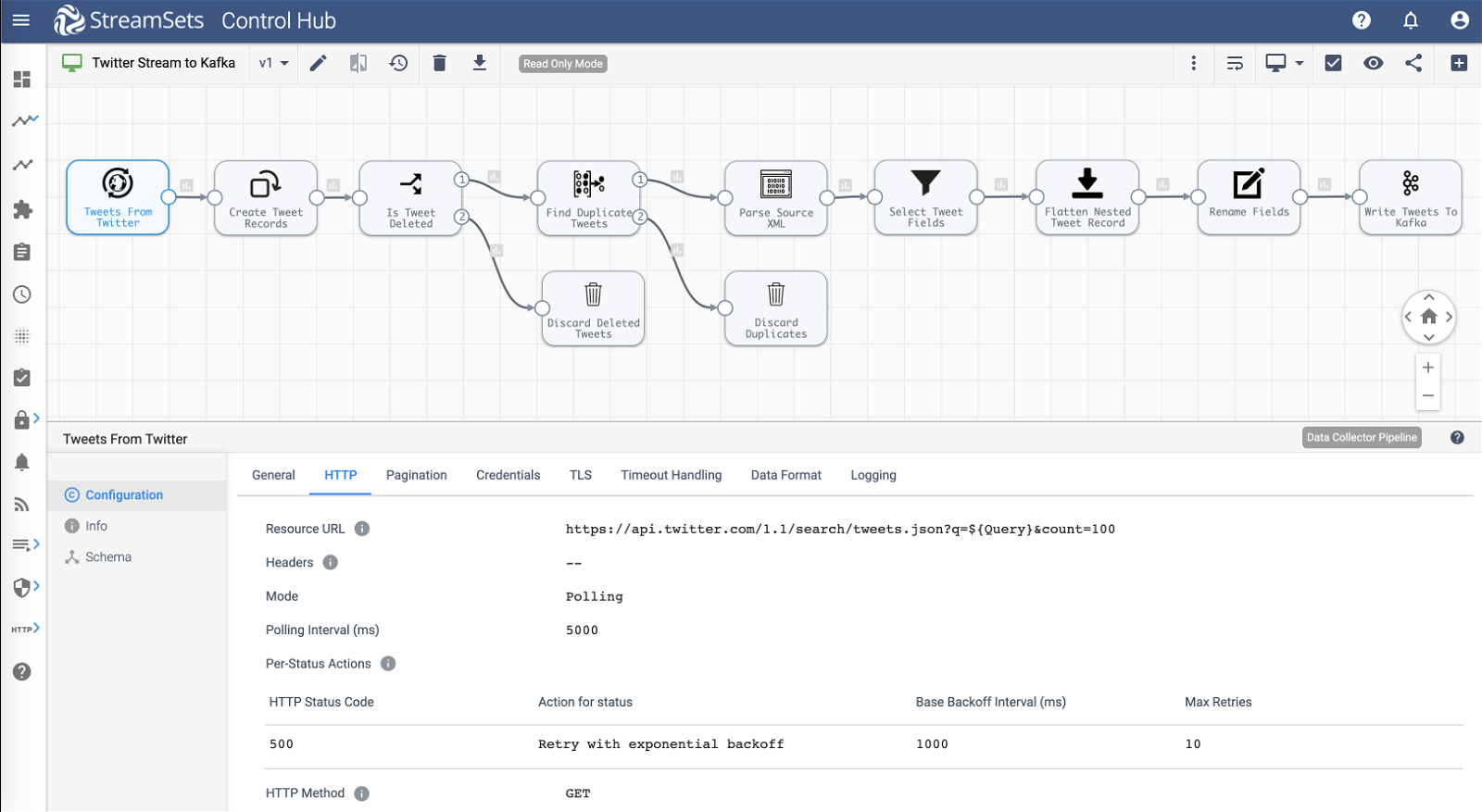
Pipeline overview:
- Ingest
- Query tweets from Twitter using its Search API for #quarantinelife using HTTP Client origin in polling mode.
- Transform
- Transformations include discarding deleted and duplicate tweets using Stream Selector, pivoting array of tweets returned by Twitter’s API into individual tweet records using Field Pivoter, flattening nested tweet structure using Field Flattener, and filtering and renaming fields using Field Remover and Field Renamer.
- Store
- The transformed tweet records are sent to Apache Kafka destination.
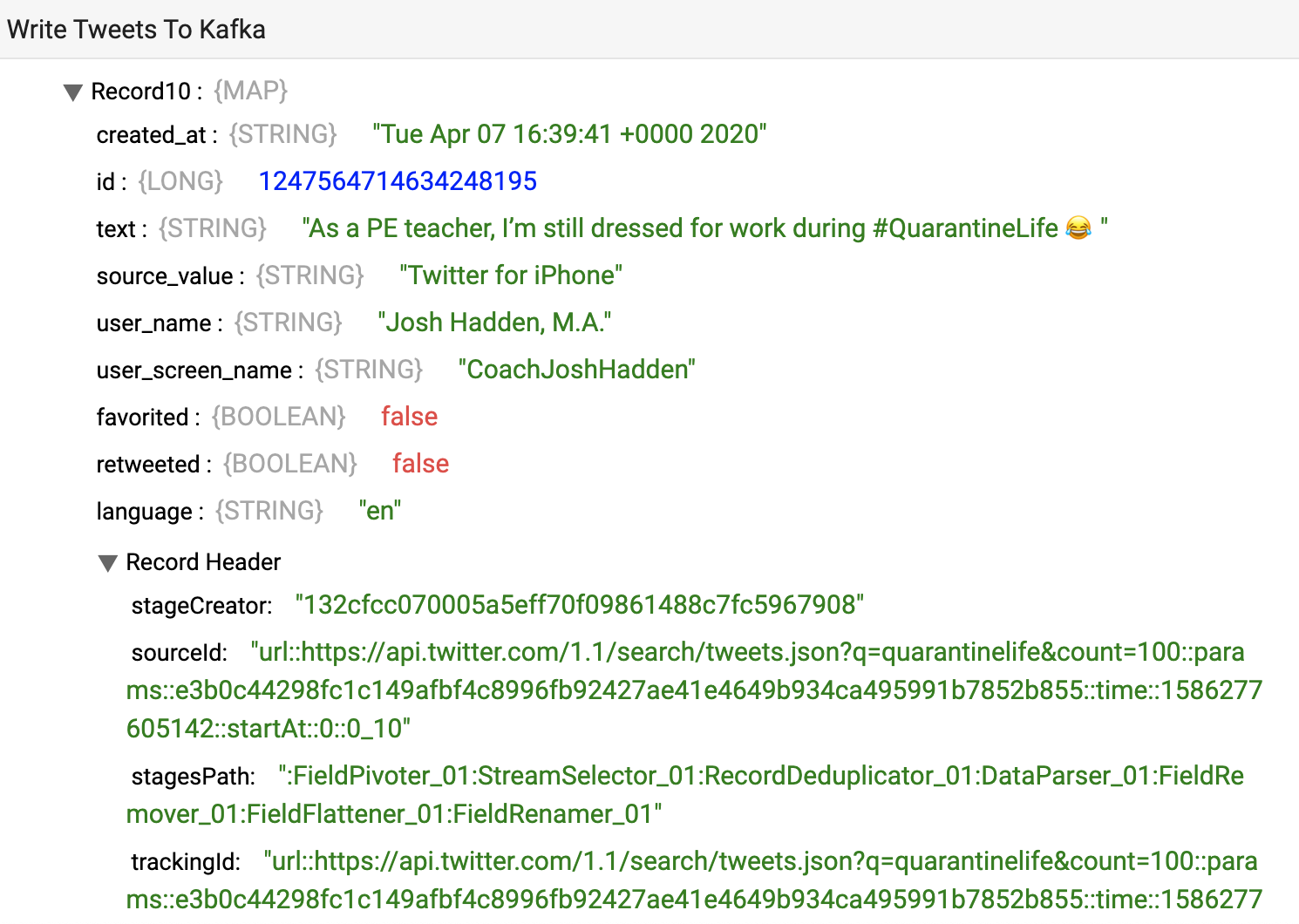
Here’s an example of the original Twitter Search API response as ingested by the HTTP Client origin.
And here’s an example of the transformed tweet written to Kafka.
Classification on Streaming Data: Kafka to Spark ML Model to Databricks
As detailed in my previous blogs, let’s assume that you have trained and serialized a model in MLeap bundle format, and it’s stored on DBFS as shown below.

Next up… I’ve designed this StreamSets Transformer pipeline running on Databricks cluster.
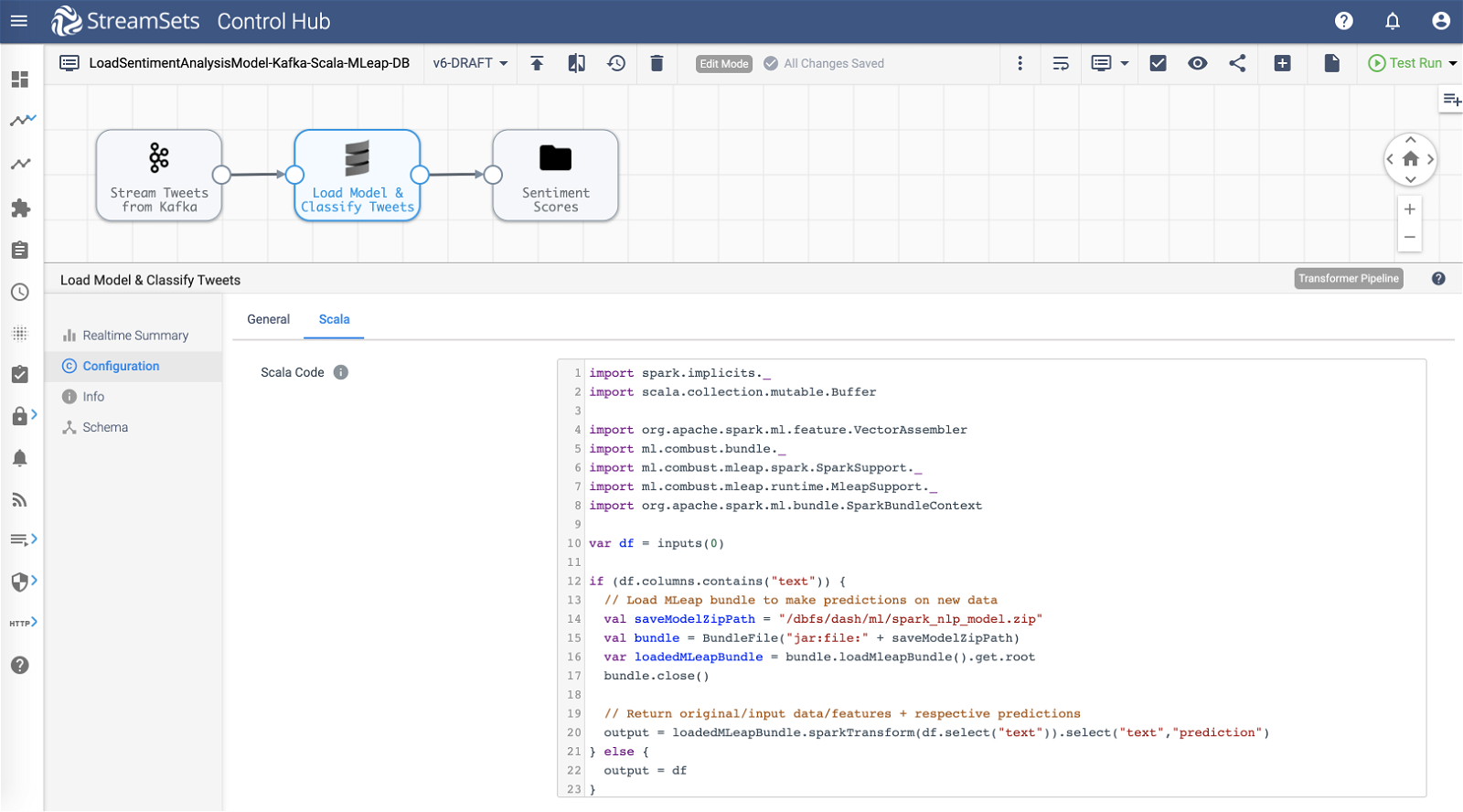
Pipeline overview:
- Ingest
- Transformed tweet records are read from Apache Kafka–from the same topic as written to by the first pipeline.
- Transform
- Scala processor loads the Spark ML model (/dbfs/dash/ml/spark_nlp_model.zip) and classifies each tweet. A value of 1 indicates positive sentiment and 0 indicates negative sentiment. (*See code snippet below.)
- Store
- Each tweet record along with its classification is stored on DBFS in Parquet format for querying and further analysis. The DBFS location in this case is /dash/nlp/.
*Below is the Scala code inserted into Scala processor >> Scala tab >> Scala Code section.
import spark.implicits._
import scala.collection.mutable.Buffer
import org.apache.spark.ml.feature.VectorAssembler
import ml.combust.bundle._
import ml.combust.mleap.spark.SparkSupport._
import ml.combust.mleap.runtime.MleapSupport._
import org.apache.spark.ml.bundle.SparkBundleContext
var df = inputs(0)
if (df.columns.contains("text")) {
// Load MLeap bundle to make predictions on new data
val saveModelZipPath = "/dbfs/dash/ml/spark_nlp_model.zip"
val bundle = BundleFile("jar:file:" + saveModelZipPath)
var loadedMLeapBundle = bundle.loadMleapBundle().get.root
bundle.close()
// Return original/input data/features + respective predictions
output = loadedMLeapBundle.sparkTransform(df.select("text")).select("text","prediction")
} else {
output = df
}
It basically takes the input data(frame) and if it contains column “text” (tweet), it loads the NLP model (“spark_nlp_model.zip”) and classifies each tweet. Then it creates a new dataframe with just the tweet and its classification stored in “prediction” column. (Note that you could also pass along/include all columns present in the input dataframe instead of just the two–“text” and “prediction”.)
Analysis on Databricks
Once the tweets, along with their classification, are stored on the Databricks File System, they’re ready for querying in Databricks Notebook.
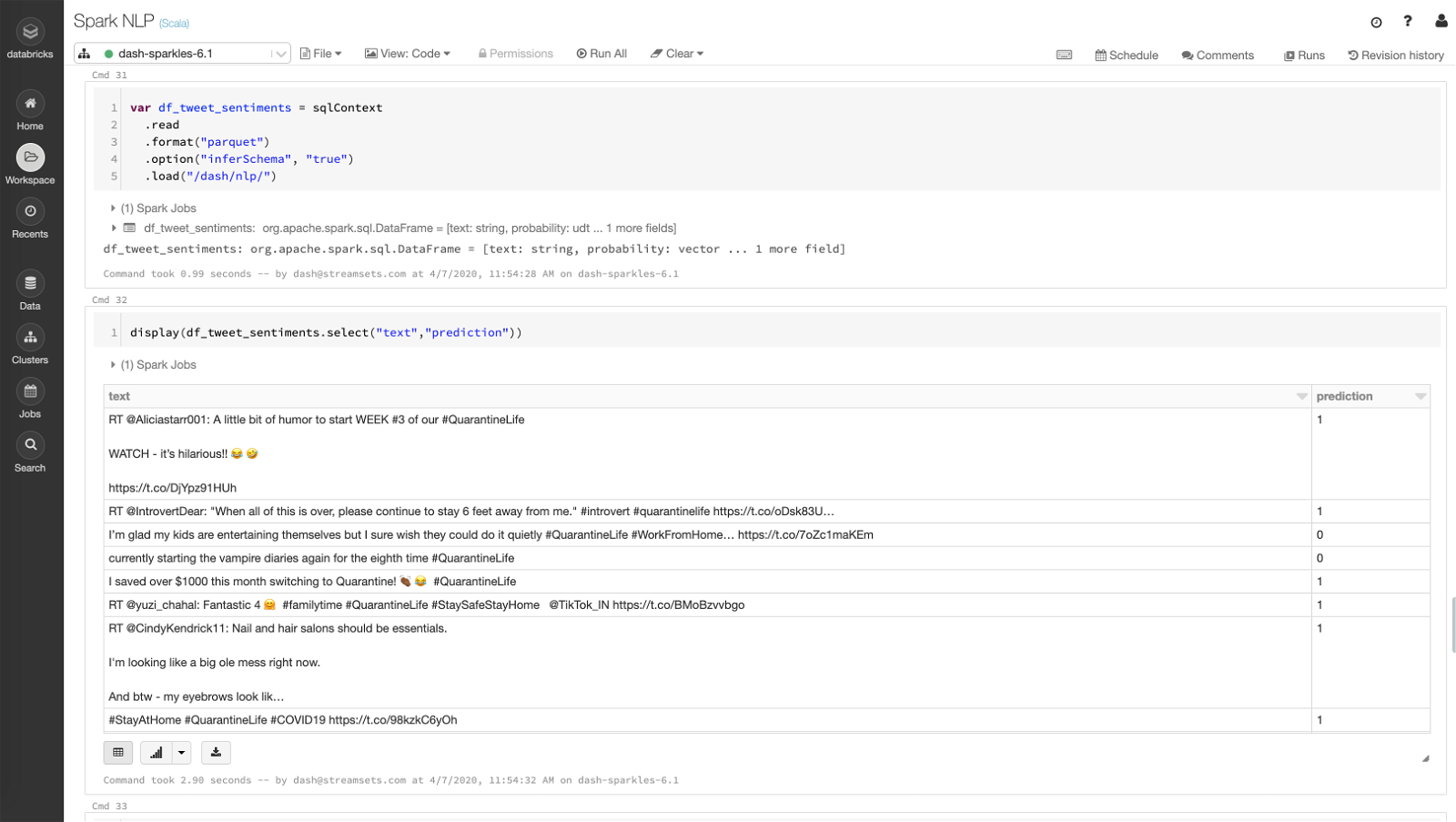
Query the tweets and their classification
Here I’ve created a dataframe that reads all the Parquet files output by the second pipeline in DBFS location /dash/nlp/ and shows what the data looks like.
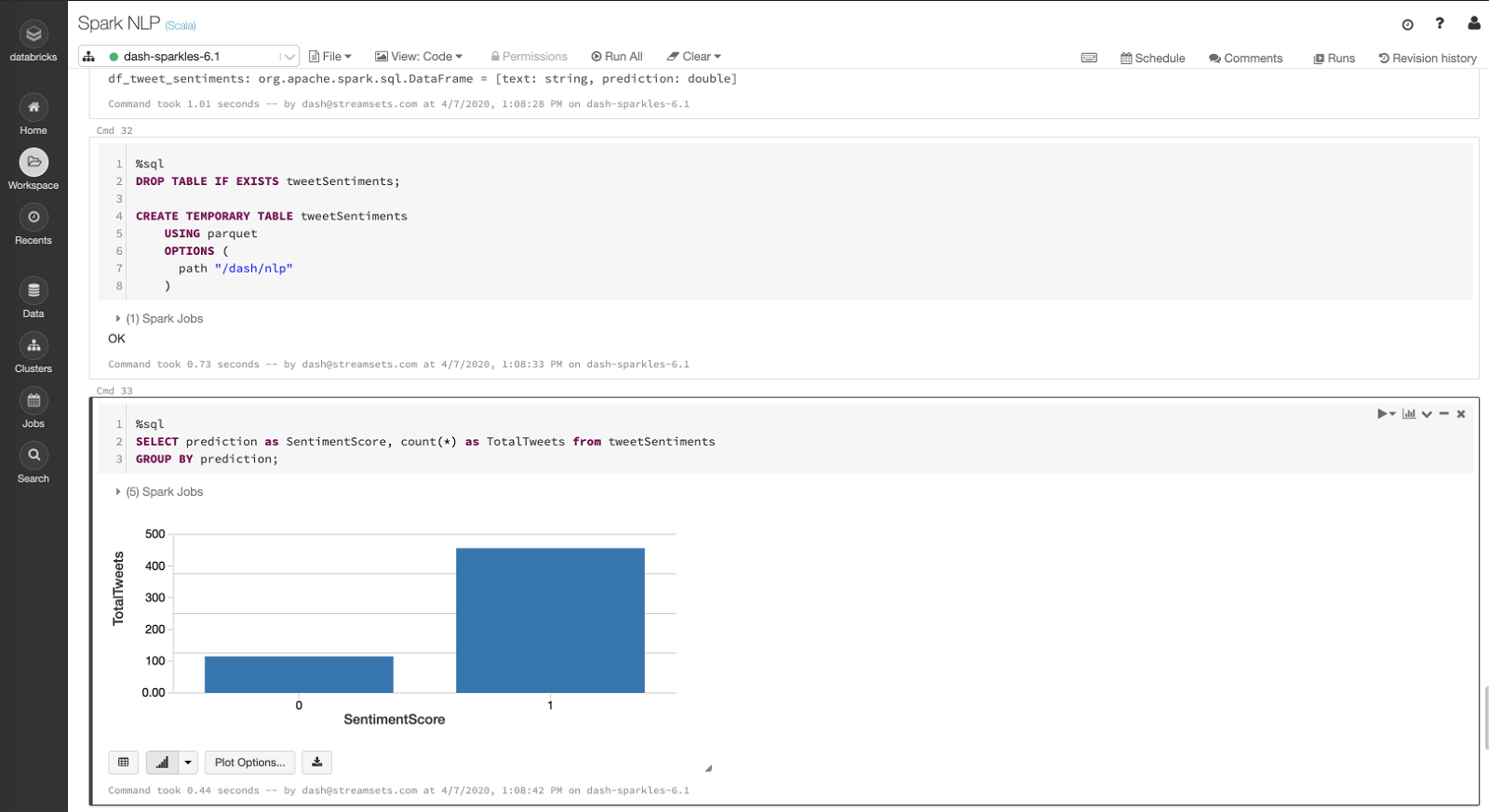
Create temp table and aggregate data
Here I’ve created a temp table that reads the same data stored in /dash/nlp/ DBFS location and an aggregate query showing total number of positive tweets vs negative tweets.
Structured Streaming
In the demo video, I’ve also shown how to create and run structured streaming query in Databricks to auto-update the counts–total number of positive and negative sentiment tweets–without having to manually refresh the source dataframe as new data is flowing in from the second pipeline.
Good News!
Based on my model and the data I’ve collected, there appears to be more positive sentiments than negative sentiments when it comes to #quarantinelife hashtag. That is something to feel good about! :)
In all honesty and fairness though, it goes without saying that the model accuracy depends on the size and quality of the training and test datasets as well as feature engineering and hyperparameter tuning–which isn’t exactly the point of this blog; rather to showcase how StreamSets DataOps Platform can be used and extended for variety of use cases.
Learn more about StreamSets for Databricks and StreamSets DataOps Platform which is available on Microsoft Azure Marketplace and AWS Marketplace.

![]()