No one can argue the value streaming data provides for an organization. From analyzing data while in motion, it’s no surprise that data-driven organizations are incorporating it into their overall data processes to help identify business strategies that work and those that don’t. As a result, the streaming analytics market has a projected growth of USD 191.72 billion and a compound annual growth rate (CAGR) of 18.74% from 2019 to 2025.
However, handling this type of data becomes very challenging, even for experienced developers, because of its diverse sources and complex streaming architecture. Data engineers must build the streaming architecture to ingest, consume, and analyze data in constant motion.
This article provides an overview of streaming data, its challenges, and how reusable (and customizable) connectors, such as the StreamSets SQL Synapse connector, help you get the most out of your data.
About the author: Maryann Agofure is a Cloud engineer and technical writer who loves fried plantains. She’s currently on a cloud data engineering journey to gain a deeper understanding of data pipelines for better analysis and seeking ways to grow her knowledge with big data tools. Her job as a Technical writer also helps her research and build on her already existing knowledge and skills.
What is Streaming Data?
Streaming data, or event streaming, refers to the continuous data generated from multiple sources to storage locations. Sources include website applications, Internet of Things (IoT) devices, log files, and servers.
Unlike traditional data solutions that involve consuming and storing data before analysis, streaming data architecture exists to consume, persist to storage, enrich, and analyze data in motion. Here are some critical use cases:
- Boosts customer experience and interaction. Through continuous analysis of consumer behavior and actions on e-commerce websites and other applications, businesses understand consumer needs and make suggestions that improve the overall consumer experience. For example, movie streaming sites like Netflix use past user behavior to predict new movies users may like.
- Fraud detection. For most applications, ensuring protection against suspected fraudulent transactions is essential. Because stream processing data undergoes processing and analysis in real-time, certain transaction anomalies can be detected and prevented before they occur.
- IoT devices. Most IoT devices run on performance-sensitive applications. The simultaneous ingestion and analysis of IoT data ensures fast performance and, in some cases, prevents losses. For example, industrial operations rely on data from stream processing to detect machine health and predict failures before they occur, as a sudden breakdown could cost millions.
- Stock market trading. Financial applications like stock markets trading need event streams to track, evaluate risks, update stock market prices, and automatically balance stock portfolios.
Limitations of Streaming Data
Data streams usually comes in high volumes and at high velocities, so designing a scalable and resilient data pipeline architecture to handle the continuous stream can be challenging.
- Scalability issues. Due to the continuous stream of data, datasets become increasingly more extensive, which may lead to slower operations and an increased need for resources. For example, running streaming operations, backups, and data reorganization consume additional resources and may affect operations in the long run.
- Complex data structure. Data streams usually arrive in unstructured and structured formats, making immediate querying more challenging. Data must first undergo parsing and structuring before querying.
- Heavy reliance on centralized storage and compute resources. Event streaming technologies, like Apache Kafka, allow for minimized coupling between producers and consumers, which can constrain data consumption. For instance, a traditional Hadoop stack has its deployment too closely tied to a central stack, constraining streaming adoption. A solution would be to adopt containerization, allowing more flexibility and domain independence.
- Business Integration issues. Most organizations with various groups have individual goals and challenges. Having each group try to integrate streaming analysis creates integration pain points along the line.
Streaming Data Architecture
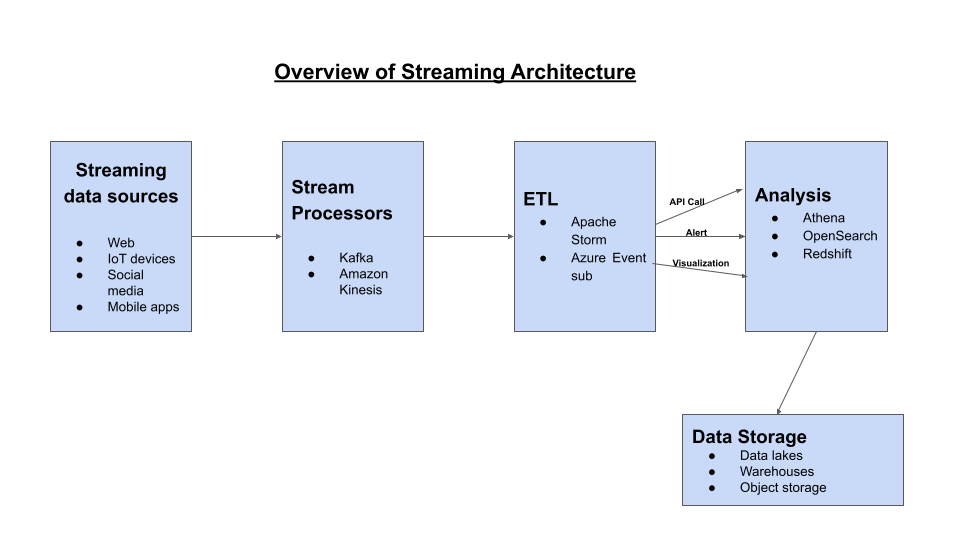
A well-built architecture enables effective and fast-performing data streams and is capable of ingesting and processing continuous, massive streams of data. There are four components of an effective streaming architecture:
- Stream Processor. Popular stream processing tools include Apache Kafka and Amazon Kinesis. Also called the message broker, the stream processor collects data from a producer, which undergoes processing. The processed data is then streamed for continuous consumption by other components.
- Real-time ETL (Extract, Transform, Load) Tools. These tools help move real-time data between locations. ETL tools include Amazon Kinesis Data Streams, Azure Event Sub, and Apache Storm. Data from streams usually arrive in unstructured formats and need some form of processing like aggregation and transformation before querying by SQL tools. The result may be an API call, an action, a visualization, or an alert.
- Data Analysis tool. After transformation by ETL tools, the processed data undergoes analysis to provide actionable insights for organizations. Most data analysis tools also help with visualization to better understand insights.
- Storage. Cloud-storage options are the most popular options for storing event streams. Data lakes, warehouses, and object storage provide their pros and cons. The storage unit needs to be able to store large amounts of data, support record ordering, and enable consistency to allow fast read-write of data. Some options include Amazon S3 and Amazon Redshift.
Principles of an Effective Streaming Architecture
- Consistency. An effective streaming design needs the ability to present the same read results when requested, and if any modification occurs, the read results should reflect it.
- Fault tolerance and availability. System failures could result in low throughput and high latency for most performance-sensitive applications, resulting in inferior performance. Streaming architecture designs should design and provide system failures to ensure continuous availability.
- Scalability. Streaming architecture design must be able to deploy compute resources to handle the sizable incoming data streams. When system failures occur and resources fail to deploy automatically, it stalls the ingestion rate and causes issues.
- Record Ordering. The architecture design should note the data sequence from streams, as an unordered data sequence may lead to discrepancies in logs and time stamps.
Streaming Data Using Reusable Connectors
With connectors and native integrations in StreamSets, such as their reusable connectors, businesses can get the most out of their data by making data accessible between systems.
- Connectors help reduce the complex workflows involved in making data communication easier between two systems.
- Connectors help different systems exchange data seamlessly without barriers.
- Connectors help automate critical workflows in the data pipeline process.
- Connectors help with reusability as engineers can reuse a single connection in multiple pipelines to reduce the risk of errors.
It becomes easier to perform fast-performing real-time analytics on event streams by employing such connectors. For example, in this example below, we’ve created a cloud storage connector.
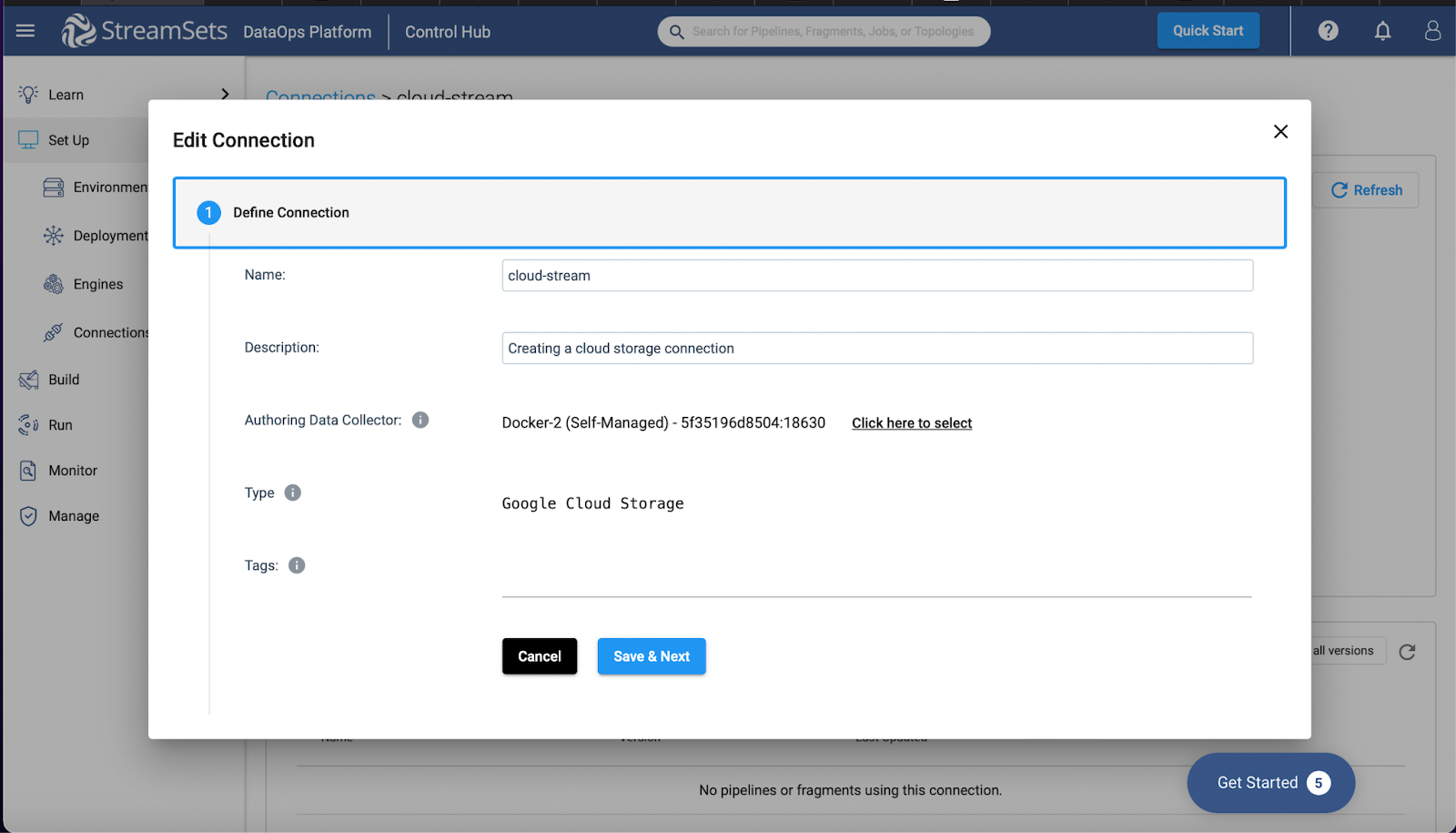
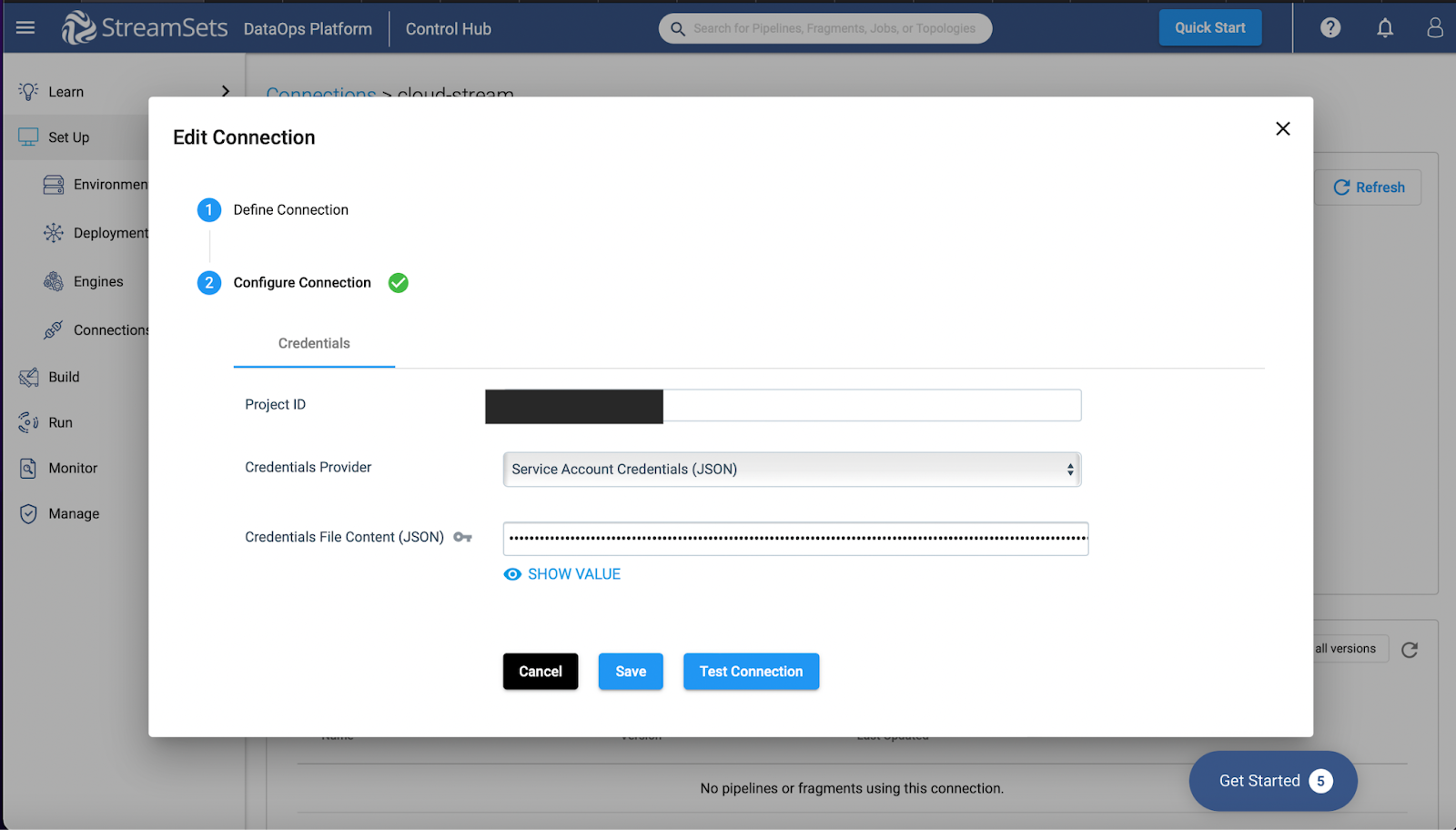
Next, I used this connection in my sample pipeline to act as the pipeline destination.
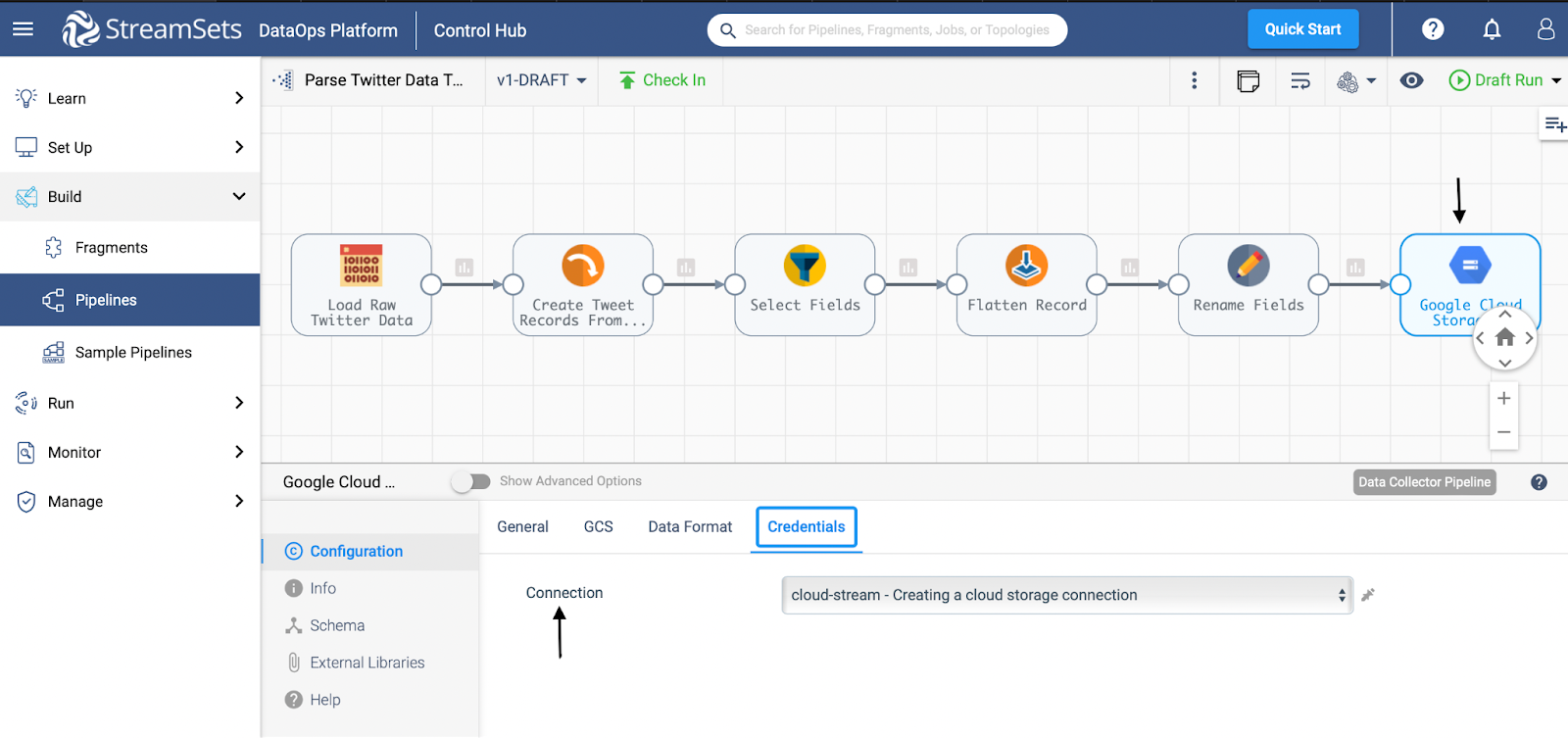
The Google Cloud Storage connection used above can be reused in other pipelines. StreamSets offers over 18 out-of-the-box connectors for you to use.
Summary
Today, most organizations utilize streaming data to enable real-time analytics to make faster business decisions. However, handling streaming data can be tricky as it comes from various sources and formats.
Hence, building a fault-tolerant and scalable streaming architecture can be challenging for data engineers. Your architecture needs to be consistent and scalable with the ability to store massive amounts of data while performing low-latency operations.
By employing reusable connectors like StreamSets’ reusable connectors, businesses can now make data easily accessible between sources and perform fast queries on event streams for applications to draw insights that help inform business strategies.
