Messaging Oriented Middleware (MOM) applications have been around for a very long time and Kafka is just one of the latest and, as of late, one of the most popular. With Snowflake also having mass popularity, it’s no surprise streaming Kafka to Snowflake is a hot topic.
It used to be that messaging applications like Kafka would mostly be used in front office applications for trading platforms or when your application used an asynchronous architecture. However, today with IoT, Distributed Applications, etc. messaging applications are playing a much larger role than ever before. We’re no longer facing the issue of connectivity between applications and enterprise messaging platforms. The issue has now become… What do we do with all of that data? It might not have huge payloads but it makes up for that with volume.
Why Kafka?
So, why do data teams implement this type of architecture? There are a number of reasons for implementing a MOM but I will just discuss what I feel are the most common.
- Asynchronous: The producer (or sender) application can continue to do other work or take more requests from users after it has sent the message.
- Routing: Either through the Messaging Broker itself or client code a message can be moved around until it is in the correct Queue/Topic for processing.
- Transformation: The message can be modified in transit to reflect what the destination system needs.
- Loose Coupling: The Producer and Consumer application can be of different languages and even operating systems.
Why StreamSets for Streaming Kafka to Snowflake?
In my most recent article on Kafka (Manage File Updates with Automated Drift Detection in Your Kafka Topics) I discussed loading your data into a Kafka Broker.
Now, let’s discuss what to do with all of this data. Usually, the two frameworks on this are:
- Read the message and then perform your transformation, enrichment, etc. at this time. Then, perform the write into the target. This is an option, however, only if you do not have to worry about the volume of the data (i.e. load on the topic/queue) outperforming your processing and writing to the destination.
- Read the message, then load it into the target system. If you have a huge volume this is the best option because then you can have many processes running to handle the ingestion of data from your Kafka Broker and another that will handle the final backend. I’ll discuss this in my next article.
StreamSets is unique in that its architecture can handle either of these scenarios and easily scale with your Kafka environment.
Connection Properties
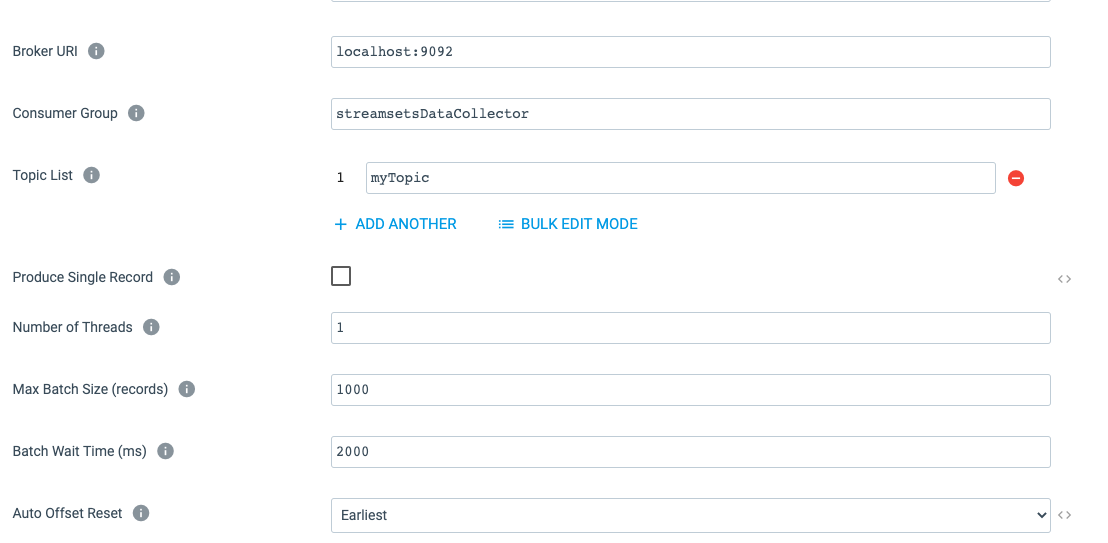
The image above is the base configuration parameters for setting up a Kafka Origin. The link will take you to the official documentation; however, I do want to touch on a few of the most important settings.
- Broker URL: This is a comma separated list of brokers
- Topic List: Functionality that allows this Origin listen to many different Topics
- Number of Threads: Number of instances StreamSets will instantiate at runtime
- Max Batch Size (records) / Batch Wait Time (ms): These two settings are an either/or config. Whichever one of these reaches its limit first will cause the pipeline to send that batch of records to the destination.
- Auto Offset Reset: The strategy of the position to start consuming messages when no offset has been saved.
Security Properties
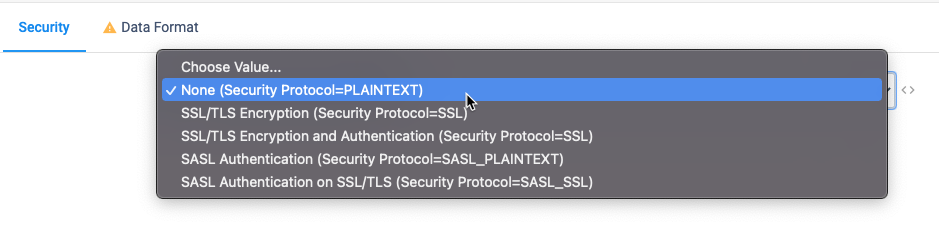
By default security is set to None. However, StreamSets provides a very complete set of security configurations to choose from out of the box.
Data Format
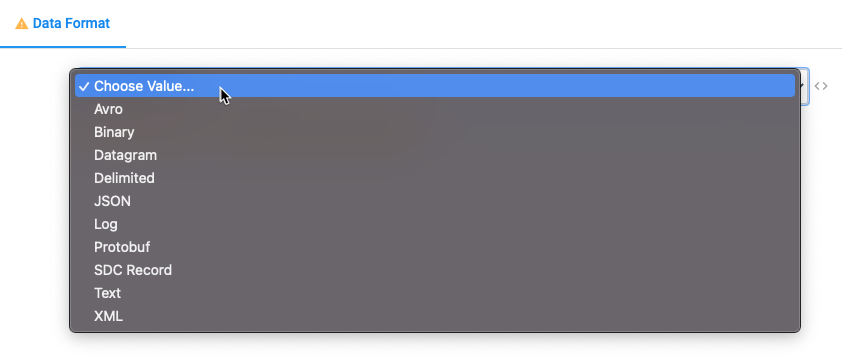
Another great feature when using StreamSets whether on the Origin or Destination is its ability to handle with little to zero configuration of many different data types.
Origin to Destination: Streaming Kafka to Snowflake
As stated earlier in my most recent article around Kafka we loaded “drifty” data from some files into our Kafka Topic.
This is another wonderful area where StreamSets really shines with patented data drift technology. That drifty data is now being consumed by our new pipeline that is wanting to load data from Kafka to Snowflake. We know what data we should be getting; however, we have learned that at any time we could get more data, less data or data where the columns are mixed around, etc.
Let’s look at how we would handle this with our Snowflake Destination.
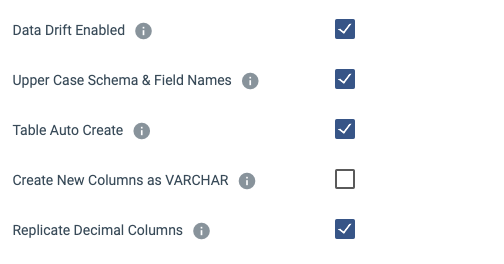
- Data Drift Enabled: Enabled by Default. When new fields appear in our records it will issue the ALTER TABLE statement on Snowflake.
- Table Auto Create: Disabled by Default. Will create a table in Snowflake if it does not exist on initial execution.
Advanced
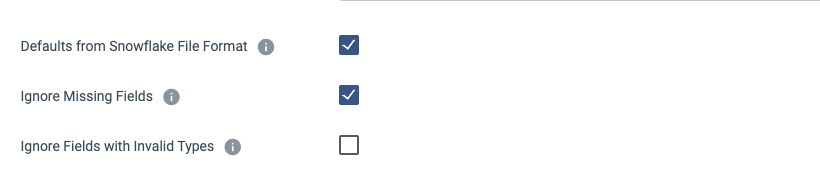
Ignore Missing Fields: Disabled by Default. If enabled, it will create a default value for those columns. If disabled, it will create error records if any fields are missing.
Streaming from Kafka to Snowflake with StreamSets
StreamSets allows for very simplistic and always-running pipelines especially when working with Messaging Architectures like Kafka. Continuous data operations allow your enterprise to process more and enable near real-time analytics. That’s a job well done as your team can now make better business decisions on-the-go.
If you’re ready to build your Kafka to Snowflake pipeline, I’d encourage you to give our easy-to-use GUI interface a try. Get started for free here.
