 Today’s guest blogger is Ian Downard, a Senior Developer Evangelist at MapR Technologies. Ian focuses on machine learning and data engineering, and recently documented how he brought together the MapR Persistent Application Client Container (PACC) with StreamSets Data Collector and Docker to build pipelines for ingesting data into the MapR Converged Data Platform. We’re reposting Ian’s article here, with his kind permission.
Today’s guest blogger is Ian Downard, a Senior Developer Evangelist at MapR Technologies. Ian focuses on machine learning and data engineering, and recently documented how he brought together the MapR Persistent Application Client Container (PACC) with StreamSets Data Collector and Docker to build pipelines for ingesting data into the MapR Converged Data Platform. We’re reposting Ian’s article here, with his kind permission.
In this post I demonstrate how to integrate StreamSets Data Collector with MapR in Docker. This is made possible by the MapR Persistent Application Client Container (PACC). The fact that any application can use MapR simply by mapping /opt/mapr through Docker volumes is really powerful! Installing the PACC is a piece of cake, too.
Introduction
I use StreamSets Data Collector a lot for creating and visualizing data pipelines. I recently discovered that I’ve been installing Data Collector the hard way, meaning I’ve been downloading the tar installer, but now I’m using the prebuilt Docker image and I’m liking the isolation and reproducibility it provides.
To use Data Collector with MapR, the mapr-client package needs to be installed on the Data Collector host. Alternatively (emphasized because this is important) you can run a separate CentOS Docker container which has the mapr-client package installed, then you can share /opt/mapr as a Docker volume with the Data Collector container. I like this approach because the MapR installer (which you can download here) can configure a mapr-client container for me! MapR calls this container the Persistent Application Client Container (PACC).
Here is the procedure I used to create and configure the PACC and Data Collector in Docker:
Start the MapR Client in Docker
Here’s a short video showing how to create, configure, and run the PACC:
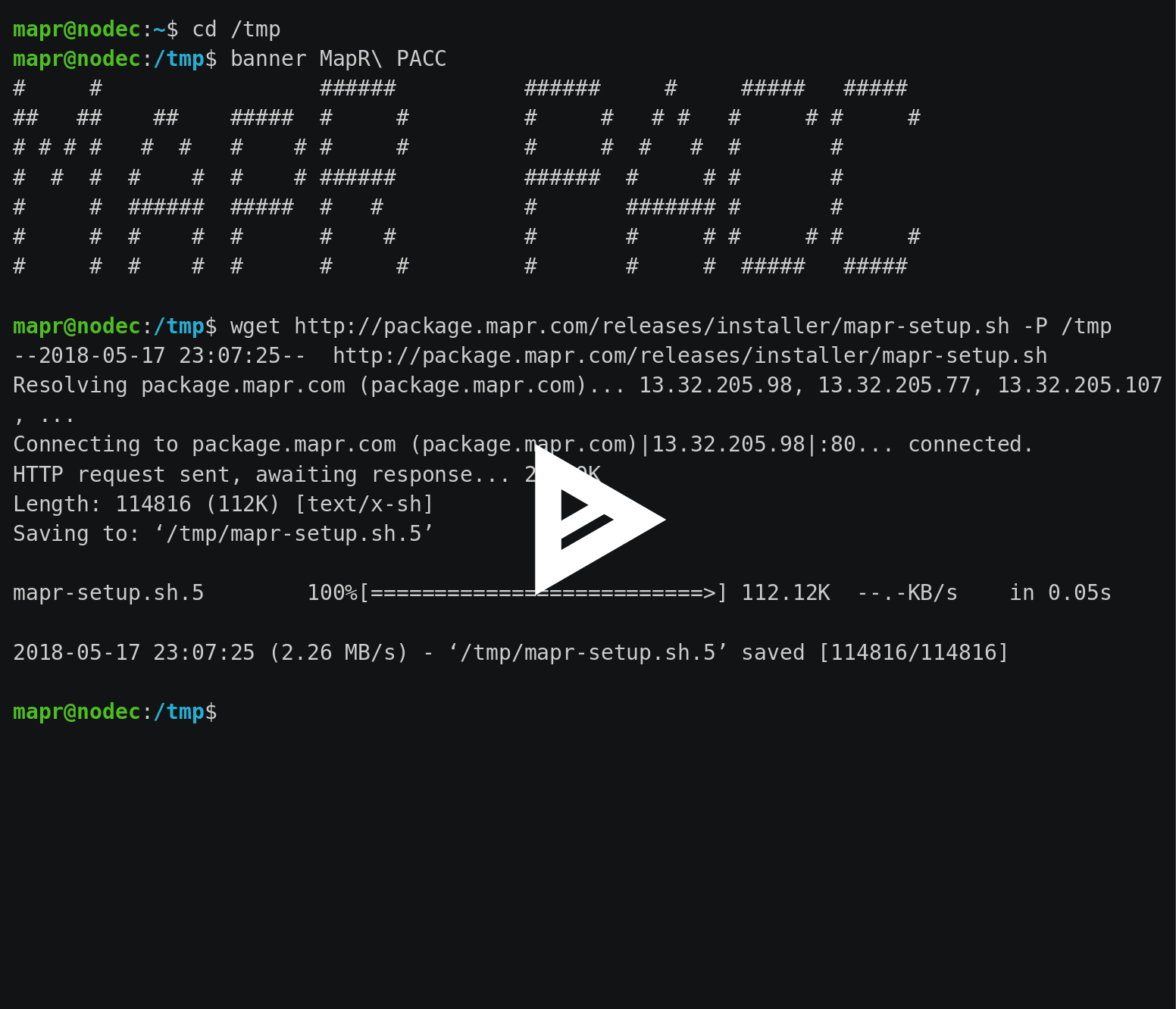
For more information about creating the PACC image, see https://docs.datafabric.hpe.com/62/AdvancedInstallation/CreatingPACCImage.html.
Here are the steps I used for creating the PACC:
wget http://package.mapr.com/releases/installer/mapr-setup.sh -P /tmp /tmp/mapr-setup.sh docker client vi /tmp/docker_images/client/mapr-docker-client.sh # Set these properties: # MAPR_CLUSTER=nuc.cluster.com # MAPR_CLDB_HOSTS=10.0.0.10 # MAPR_MOUNT_PATH=/mapr # MAPR_DOCKER_ARGS="-v /opt/mapr --name mapr-client" /tmp/docker_images/client/mapr-docker-client.sh
Start Data Collector in Docker
Start the Data Collector Docker container with the following command.
docker run --restart on-failure -it -p 18630:18630 -d --volumes-from mapr-client \ --name sdc streamsets/datacollector
Normally we would need to install the MapR client on the Data Collector host, but since we’ve mapped /opt/mapr from the PACC via Docker volumes, the Data Collector host already has it!
Now you need to go to the Data Collector Package Manager and install the MapR libraries:
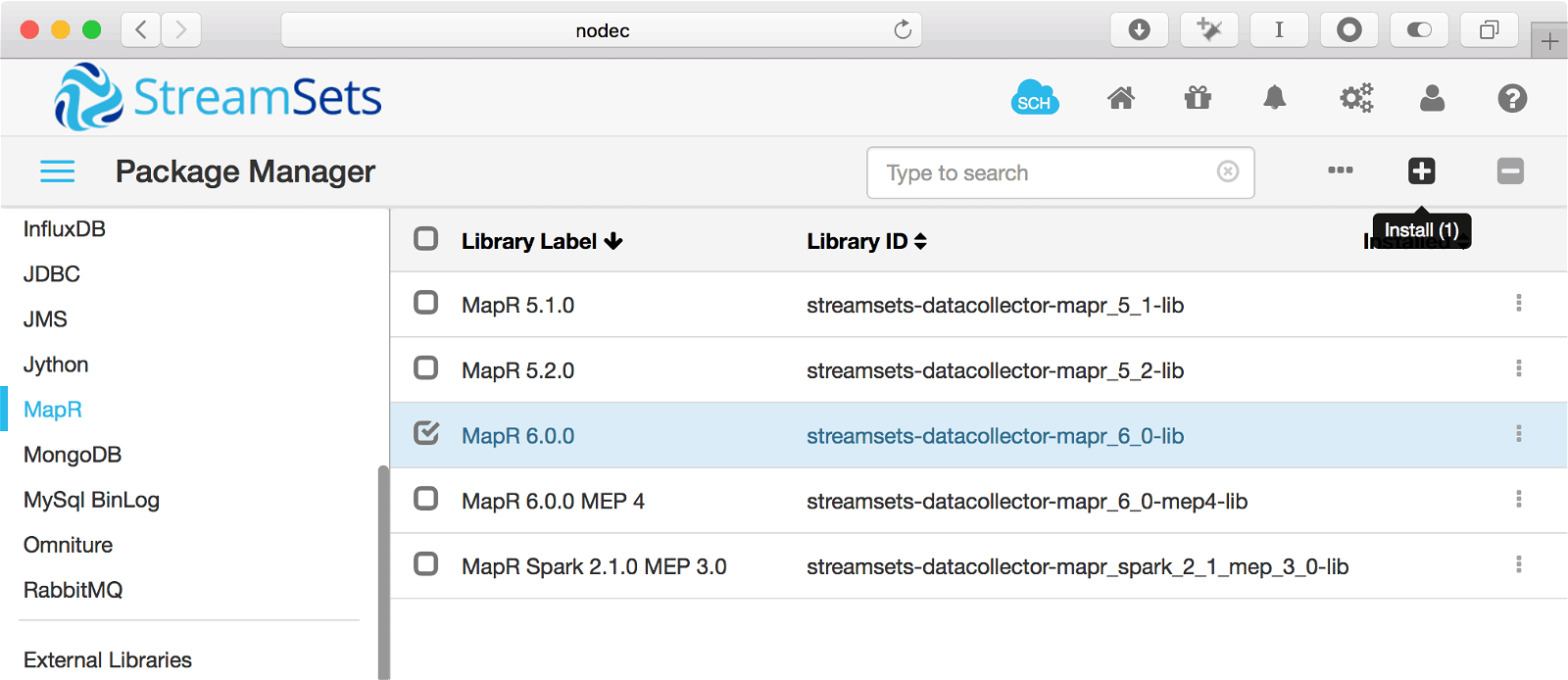
You’ll see several MapR packages in Data Collector:
- MapR 6.0.0
- MapR 6.0.0 MEP 4
- MapR Spark 2.1.0 MEP 3
You’ll want to install the first one, “MapR 6.0.0”. That package lets you use MapR filesystem, MapR-DB, and MapR Streams. If you want Hive and cluster mode execution, then install “MapR 6.0.0 MEP 4” as well as “MapR 6.0.0”. If you want Spark, then also install “MapR Spark 2.1.0 MEP 3”.
For more details on why the MapR package was split up like this, see this particular Github commit
After you install the package, don’t forget to run the setup-mapr script and all that jazz as described in the setup guide.
You’ll be prompted to restart Data Collector. After it’s restarted, run these commands to finish the MapR setup:
docker exec -u 0 -it sdc /bin/bash export SDC_HOME=/opt/streamsets-datacollector-3.2.0.0/ export SDC_CONF=/etc/sdc echo "export CLASSPATH=\`/opt/mapr/bin/mapr classpath\`" >> /opt/streamsets-datacollector-3.2.0.0/libexec/sdc-env.sh /opt/streamsets-datacollector-3.2.0.0/bin/streamsets setup-mapr
Restart Data Collector again from the gear menu.
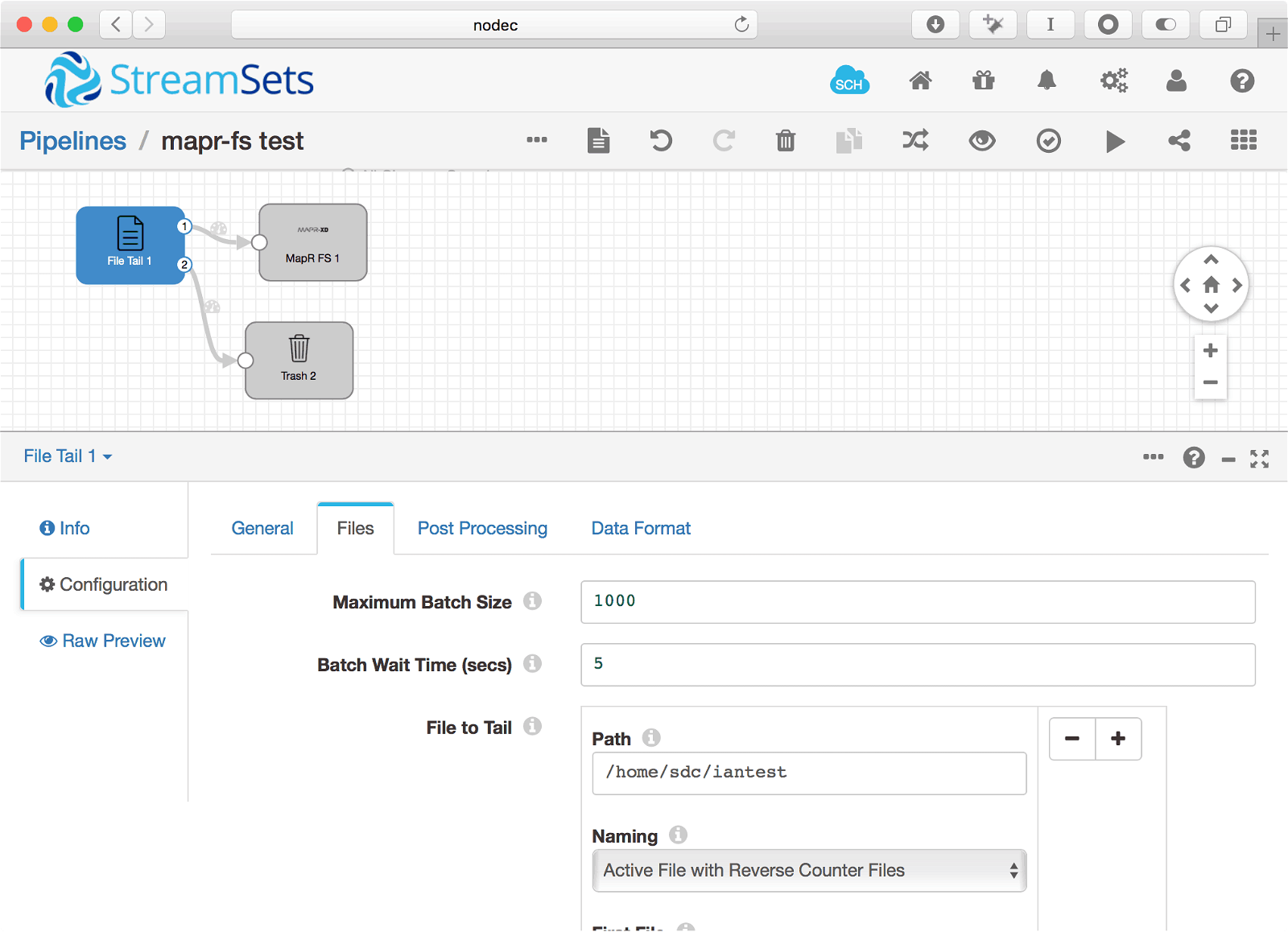
When it comes up you will be able to use MapR in data pipelines. Here’s a basic pipeline example that saves the output of tailing a file to a file on MapR-FS:
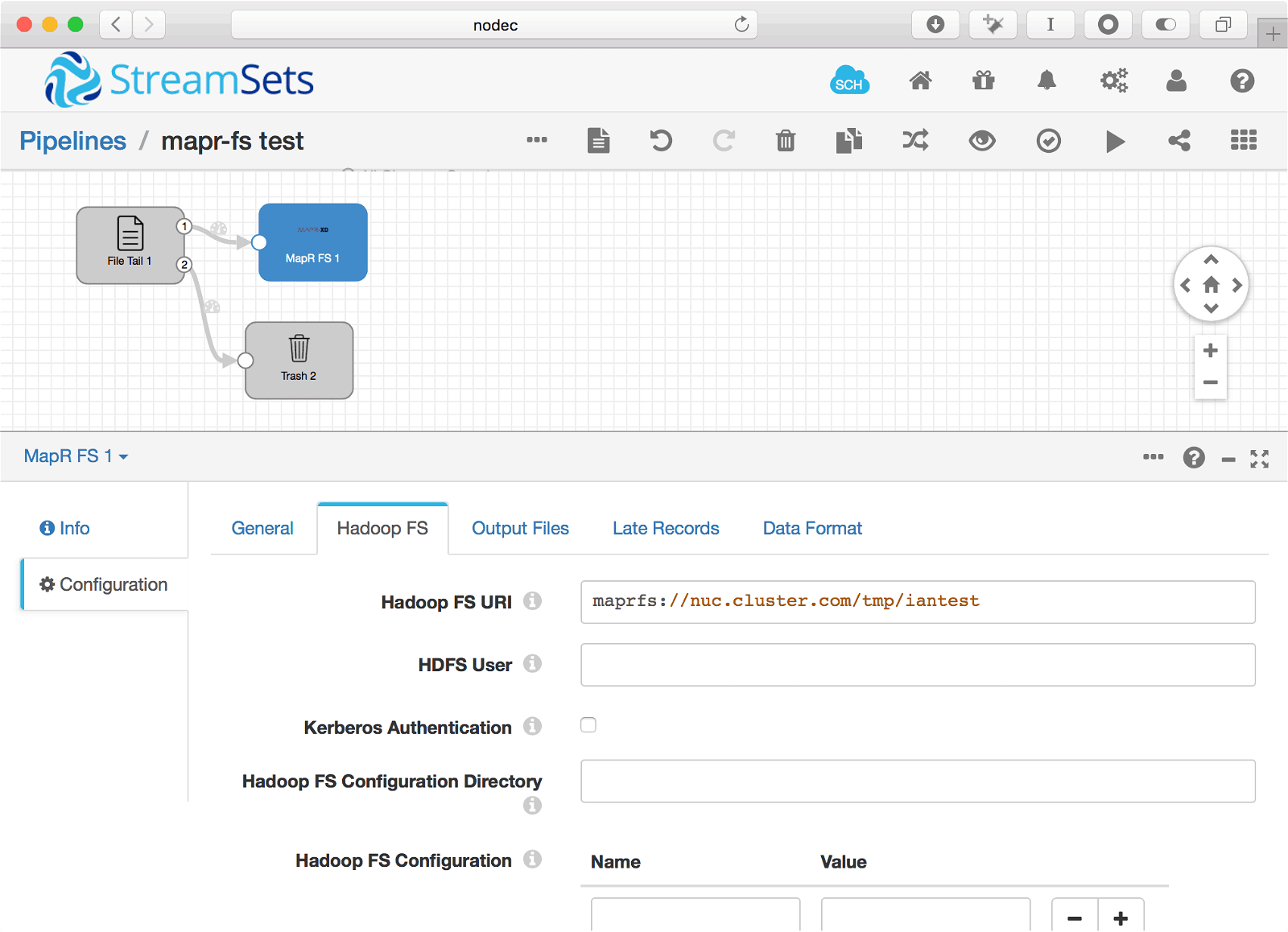
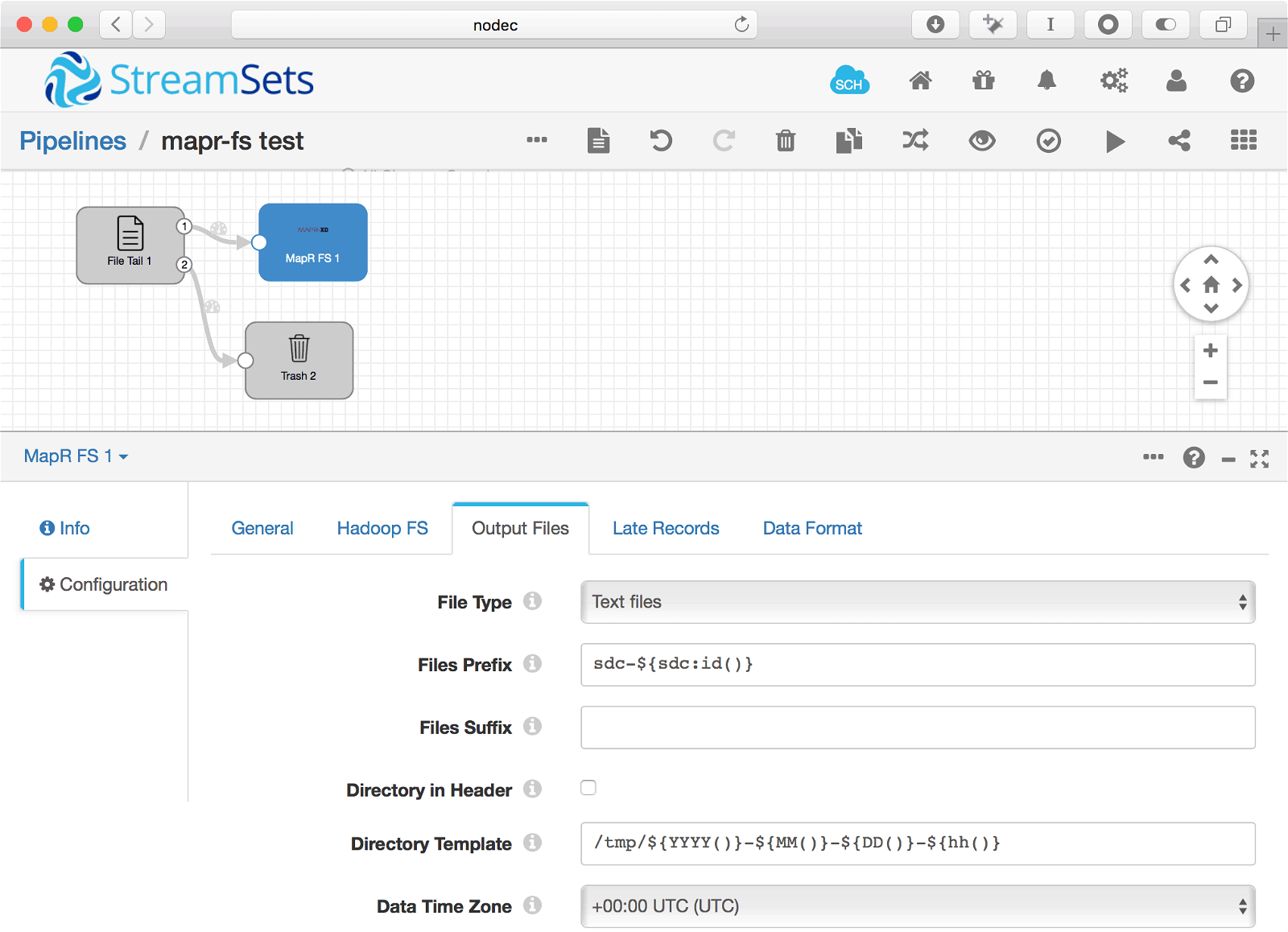
Please provide your feedback to this article by adding a comment to https://github.com/iandow/iandow.github.io/issues/11.
Thanks, Ian, for a great explanation! If you’d like to contribute a guest post on anything StreamSets-related, please get in touch.