This is a guest post by Clark Bradley, Solutions Engineer, StreamSets
SNMP stands for simple network management protocol and allow for network devices to share information. SNMP is supported across a wide range of hardware such as conventional network equipment (routers, switches and wireless access points) to network endpoints like applications and internet of things (IoT) devices.
An SNMP managed network consists of managers, agents and MIB (management information base). Managers initiate communication with agents which send responses as PDU (protocol data unit) between them while the MIBs store the information about objects used by a device. The PDU contain information on user information and control data. By issuing queries from a manager to an agent, a user can trap agent alerts, send configuration commands and retrieve OID (object identifier) information from the MIB.
In this blog, we will be using StreamSets Data Collector to build a pipeline to retrieve the data from MIB and store it in Amazon S3. The MIB contains multiple OID that can be used to report on network activity access points, neighbor detection to list known vs rogue access points, uplink statistics to monitor and reduce downtime, interference or bad clients which could identify network slowdown. The OID is an address in the MIB hierarchy which is used to recognize the network devices and their statuses such as hardware temperature, IP address and location, timeticks (time between events) or system up time.
First, we build our pipeline using the Groovy Scripting origin which allows a data engineer/developer to write code for a Java based connector called SNMP4J to allow SNMP polling. SNMP4J is an enterprise class free open source SNMP implementation which supports both command generation (managers) as well as command responding (agents) communication.
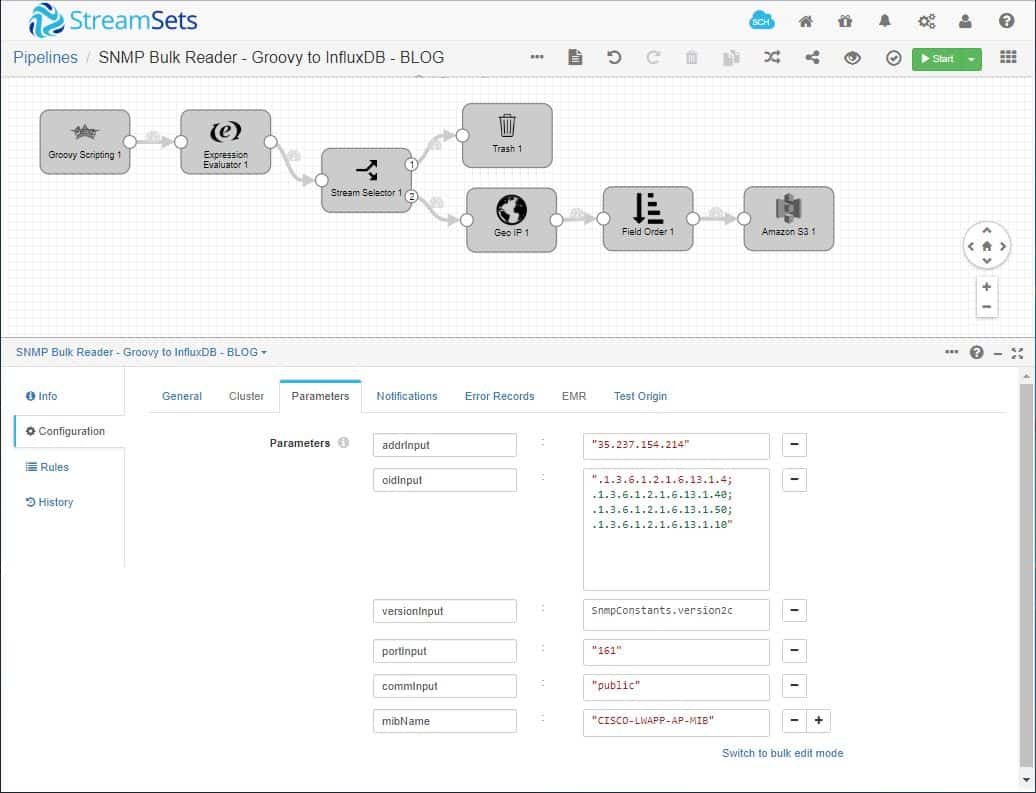
As shown above, we’ve created parameters for the Groovy Scripting origin to provide IP or hostname of the network controller, an OID (or list of OID) to traverse, the SNMP version (v1, v2 or v3), the community target which is an SNMP target properties for community based message processing used in v1 and v2 and lastly an MIB name to use for the target table. These runtime parameters are dynamic and can be changed at pipeline execution in order to reuse the pipeline for polling multiple MIBs.
Here’s the pipeline in preview mode.
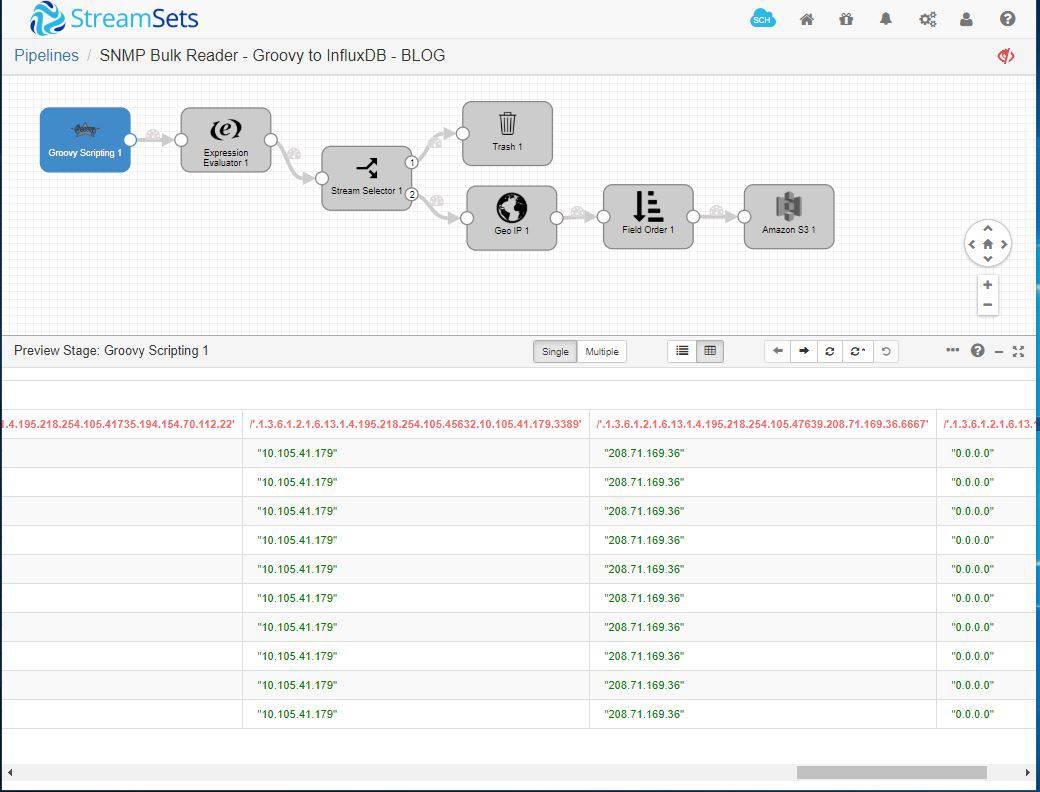
Note that the pipeline can be set to refresh every second or every few minutes to look for patterns in the data. As the session begins, the pipeline will poll the router with a SNMP bulk walk process. The pipeline uses SNMP GETBULK requests to query a network entity efficiently for a tree of information. We’ve also added sleep cycle that can be customized to the network size and traffic to retrieve updated and relevant data to be provided to visualization for security analysis.
Here’s the sample Groovy Scripting origin code.
import java.util.Map;
import java.util.TreeMap;
import java.io.IOException;
import java.util.List;
import org.snmp4j.CommunityTarget;
import org.snmp4j.PDU;
import org.snmp4j.Snmp;
import org.snmp4j.smi.*;
import org.snmp4j.mp.*;
import org.snmp4j.transport.DefaultUdpTransportMapping;
import org.snmp4j.util.*;
// single threaded - no entityName because we need only one offset
entityName = ''
// get the previously committed offset or start at 0
if (sdc.lastOffsets.containsKey(entityName)) {
offset = sdc.lastOffsets.get(entityName) as int
} else {
offset = 0
}
if (sdc.userParams.containsKey('recordPrefix')) {
prefix = sdc.userParams.get('recordPrefix')
} else {
prefix = ''
}
cur_batch = sdc.createBatch()
record = sdc.createRecord('generated data')
public static Map doSNMPBulkWalk(String ipAddr, String commStr, String bulkOID, String port) throws IOException {
Snmp snmp = new Snmp(new DefaultUdpTransportMapping());
CommunityTarget targetV2 = null;
PDU request = null;
snmp.listen();
Address add = new UdpAddress(ipAddr + "/" + port);
targetV2 = new CommunityTarget();
targetV2.setCommunity(new OctetString(commStr));
targetV2.setAddress(add);
targetV2.setTimeout(1500);
targetV2.setRetries(2);
targetV2.setVersion(${versionInput});
targetV2.setMaxSizeRequestPDU(65535);
request = new PDU();
request.setMaxRepetitions(1);
request.setNonRepeaters(0);
request.setType(PDU.GETBULK);
OID oID = new OID(bulkOID);
request.add(new VariableBinding(oID));
OID rootOID = request.get(0).getOid();
List l = null;
TreeUtils treeUtils = new TreeUtils(snmp, new DefaultPDUFactory());
targetV2.setCommunity(new OctetString(commStr));
OID[] rootOIDs = new OID[1];
rootOIDs[0] = rootOID;
l = treeUtils.walk(targetV2, rootOIDs);
Map result = new TreeMap<>();
for(TreeEvent t : l) {
VariableBinding[] vbs = t.getVariableBindings();
for (VariableBinding varBinding : vbs) {
Variable val = varBinding.getVariable();
if (val instanceof Integer32) {
Integer valMod = new Integer(val.toInt());
result.put("." + varBinding.getOid(), valMod);
} else {
result.put("." + varBinding.getOid(), val);
}
if (sdc.isStopped()) { break;}
}
if (sdc.isStopped()) { break;}
}
snmp.close();
return result;
}
hasNext = true
while(hasNext) {
record = sdc.createRecord('generated data')
try {
String[] oidList = ${oidInput}.split(";");
for (String oidSingle : oidList) {
Map result = doSNMPBulkWalk(${addrInput}, ${commInput}, oidSingle, ${portInput}, sdc);
result.each { key, val ->
offset = offset + 1
record = sdc.createRecord('generate records')
//List the OID in the record
record.value = [:]
col = "OID"
record.value[col] = key
//List Object Description in the record
col = "OID_VALUE"
record.value[col] = val
//Add the record to the current batch
cur_batch.add(record)
// if the batch is full, process it and start a new one
if (cur_batch.size() >= sdc.batchSize) {
// blocks until all records are written to all destinations
// (or failure) and updates offset
// in accordance with delivery guarantee
cur_batch.process(entityName, offset.toString())
cur_batch = sdc.createBatch()
sleep(300000)
if (sdc.isStopped()) {
hasNext = false
}
}
}
}
} catch (Exception e) {
sdc.error.write(record, e.toString())
hasNext = false
}
}
We’ve also added processors in the pipeline to remove unwanted or missing IP data with a Stream Selector and a Geo IP processor to enrich validated data with latitude, longitude, city and country.
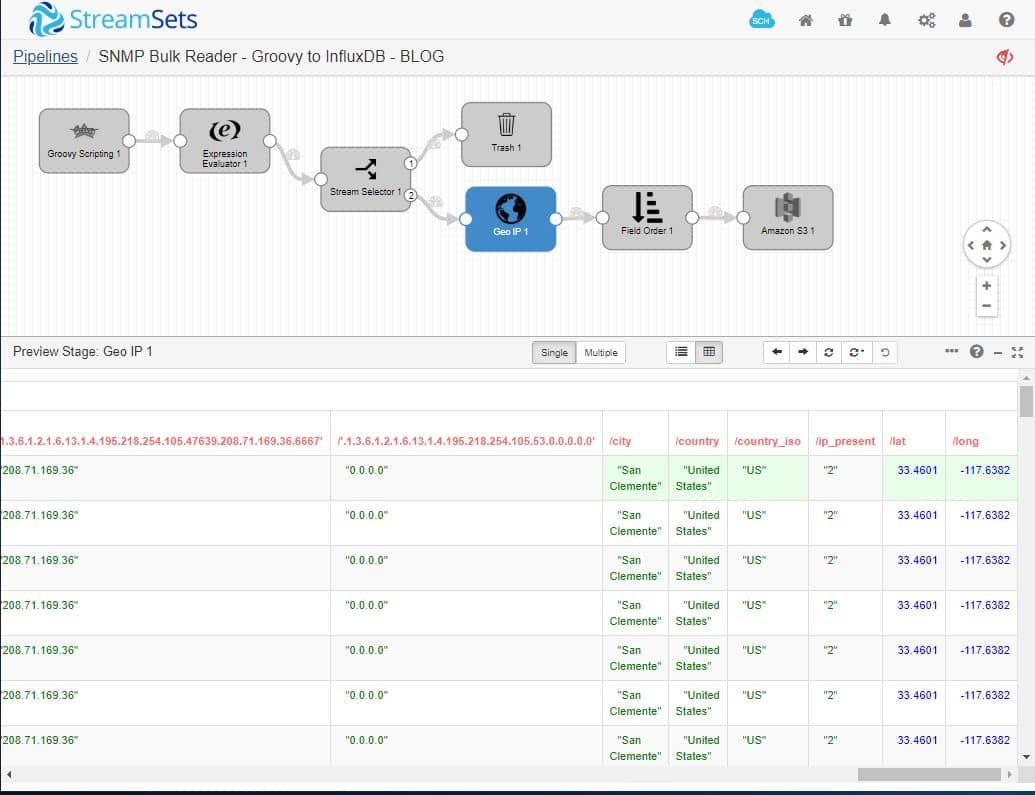
Finally, the data is stored in Amazon S3 for further aggregation, visualization and/or security analysis.
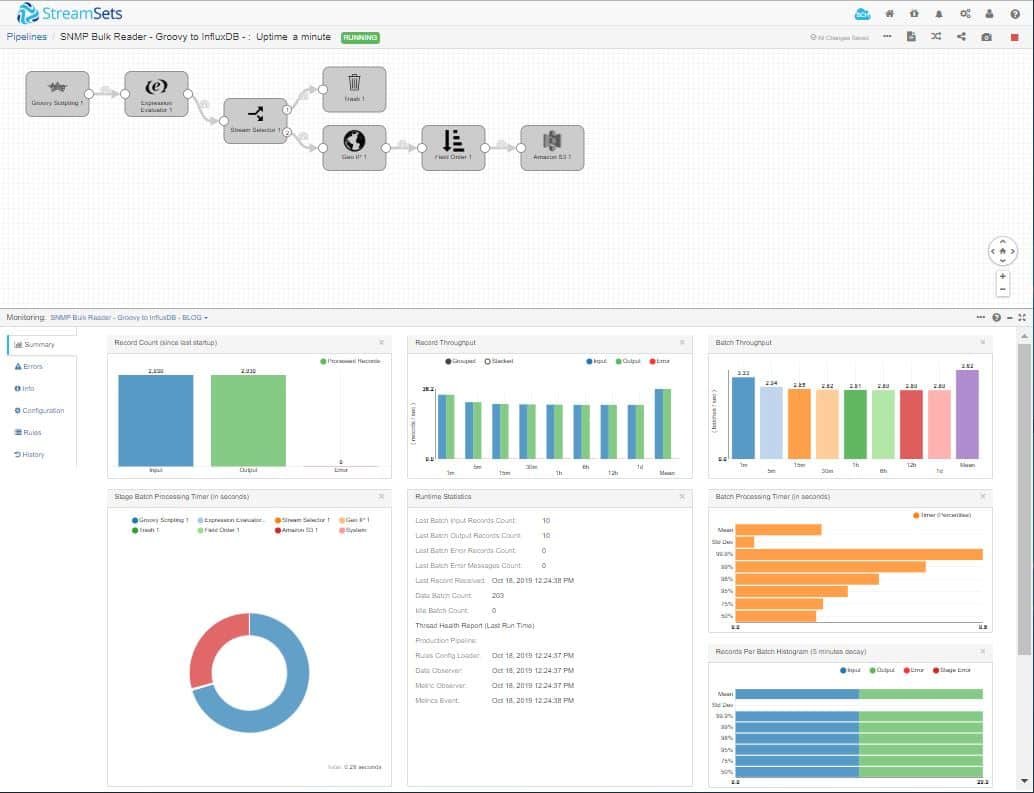
Summary
In this post, we learned that data engineers can quickly and easily build pipelines to offload data origins, such as MIB data from SNMP networks, for integration with other sources or long-term storage for security and network health analysis.
If you are interested in learning more about StreamSets, visit our Resource Finder.
StreamSets Data Collector is open source, under the Apache 2.0 license. To download for free and start developing your data pipelines, visit Download page.