In this blog, we will look at a few design patterns for Slowly Changing Dimensions (SCD) Type 2 and see how StreamSets Transformer, the newest addition to the StreamSets DataOps Platform, makes it easy to implement them.
While relatively static data like locations and addresses of entities, such as customers, change rarely (if at all) over time, in most cases it is critical that the history of all changes is maintained. This refers to the concept of dimensions and Slowly Changing Dimensions which are important components of DataOps by way of management and automation of such datasets.
“Dimensions in data management and data warehousing contain relatively static data about such entities as geographical locations, customers, or products. Data captured by Slowly Changing Dimensions (SCDs) change slowly but unpredictably, rather than according to a regular schedule” — Wikipedia.
There are six types (Type 1 thru Type 6) of SCD operations and StreamSets Transformer enables you to handle and implement two common ones–Type 1 and Type 2.
Type 1 SCD — Doesn’t require history of dimension changes to be maintained and the old dimension value is simply overwritten with the new one. This type of operation is easy to implement (similar to a normal SQL update) and is often used for things like removing special characters, correcting typos and spelling mistakes in record field values.
Type 2 SCD — Requires maintaining history of all changes made to each key in a dimensional table. Here are some challenges involved when manually dealing with Type 2 SCD:
- Every process that updates these tables has to honor the Type 2 SCD pattern of expiring old records and replacing them with new ones
- There might not be a built-in constraint to prevent overlapping start and end dates for a given dimension key
- When converting an existing table to a Type 2 SCD, it will most likely require you to update every single query that reads from or writes to that table
- Every query against that table will need to account for the historical Type 2 SCD pattern by filtering only for current data or for a specific point in time
As you can imagine, Type 2 SCD operations can become complex and hand-written code, SQL queries, etc. may not scale and can be difficult to maintain.
Meet Slowly Changing Dimension processor. This processor makes it easy to implement Type 2 SCD operations by enabling data engineers to centralize all the “logic” (via configuration; not SQL queries or code!) in one place.
Let’s take a look at a few common design patterns.
Pattern 1: One-time Migration — File Based (Batch mode)
Let’s first take a very simple yet concrete example of managing customer records (with updates to addresses) for existing and new customers. In this case, the assumption is that the destination is empty so it’s more of a one-time migration scenario for ingesting “master” and “change” records from respective origins to a new file destination.
This scenario involves:
- Creating one record for every row in “master” origin
- Creating one record for every row in “change” origin
- New customers: Version set to 1 where customer id doesn’t exist in “master” origin
- Existing customers: Version set to current value in “master” origin + 1 where customer id exists in “master” origin
Sample Pipeline
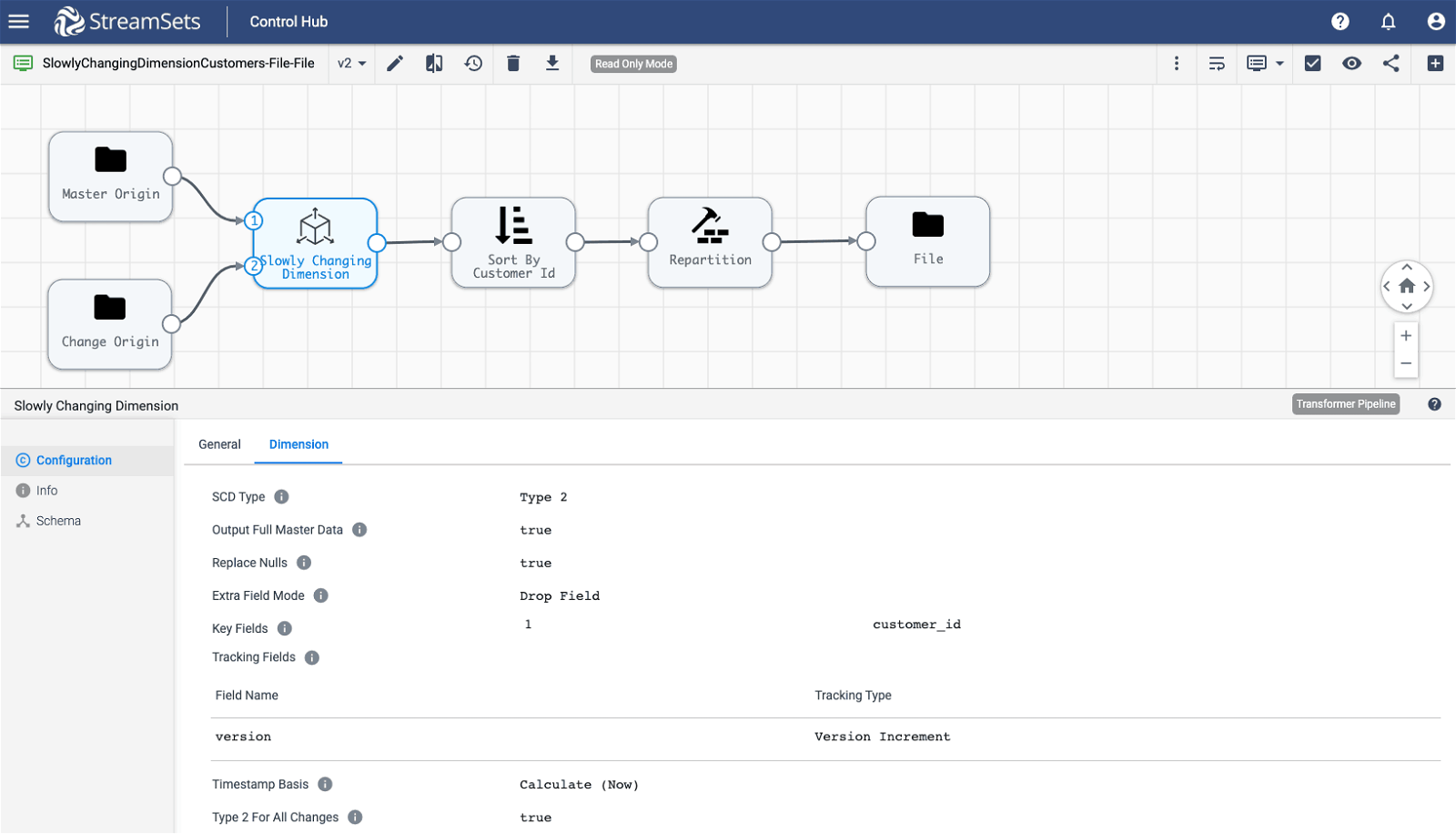
Note: For details on configuration attributes, click here.
Master Origin Input: Sample master records for existing customers
customer_id,customer_fname,customer_lname,customer_email,customer_password,customer_street,customer_city,customer_state,customer_zipcode,version 1,Richard,Hernandez,XXXXXXXXX,XXXXXXXXX,6303 Heather Plaza,Brownsville,TX,78521,1 2,Mary,Barrett,XXXXXXXXX,XXXXXXXXX,9526 Noble Embers Ridge,Littleton,CO,80126,1 3,Ann,Smith,XXXXXXXXX,XXXXXXXXX,3422 Blue Pioneer Bend,Caguas,PR,00725,1
Change Origin Input: Sample change records for existing and new customers
customer_id,customer_fname,customer_lname,customer_email,customer_password,customer_street,customer_city,customer_state,customer_zipcode 2,Mary,Barrett,XXXXXXXXX,XXXXXXXXX,4963 Ponderosa Ct,Park City,UT,80126 3,Ann,Smith,XXXXXXXXX,XXXXXXXXX,1991 Margo Pl,San Fran,CA,00725 11,Mark,Barrett,XXXXXXXXX,XXXXXXXXX,4963 Ponderosa Ct,Park City,UT,80126
Final Output: Given the two datasets above the resulting output will look like this
customer_id,customer_fname,customer_lname,customer_email,customer_password,customer_street,customer_city,customer_state,customer_zipcode,version 1,Richard,Hernandez,XXXXXXXXX,XXXXXXXXX,6303 Heather Plaza,Brownsville,TX,78521,1 2,Mary,Barrett,XXXXXXXXX,XXXXXXXXX,9526 Noble Embers Ridge,Littleton,CO,80126,1 2,Mary,Barrett,XXXXXXXXX,XXXXXXXXX,4963 Ponderosa Ct,Park City,UT,80126,2 3,Ann,Smith,XXXXXXXXX,XXXXXXXXX,3422 Blue Pioneer Bend,Caguas,PR,00725,1 3,Ann,Smith,XXXXXXXXX,XXXXXXXXX,1991 Margo Pl,San Fran,CA,00725,2 11,Mark,Barrett,XXXXXXXXX,XXXXXXXXX,4963 Ponderosa Ct,Park City,UT,80126,1
Notice that the total number of output records is 6; 3 records from master origin for existing customers and 3 records from the change origin–where two records are for existing customers Mary and Ann with their updated address and version incremented to 2 and one record for new customer Mark with version set to 1.
Pattern 2: Incremental Updates — JDBC Based (Streaming mode)
Now let’s say there is a JDBC connection enabled database (for example, MySQL) and it has a dimension table “customers” with composite primary key — customer_id, version. In this case, the goal is still the same as pattern 1 and 2 where we’d like to capture and maintain history of updates for new and existing customer records.
Sample Pipeline
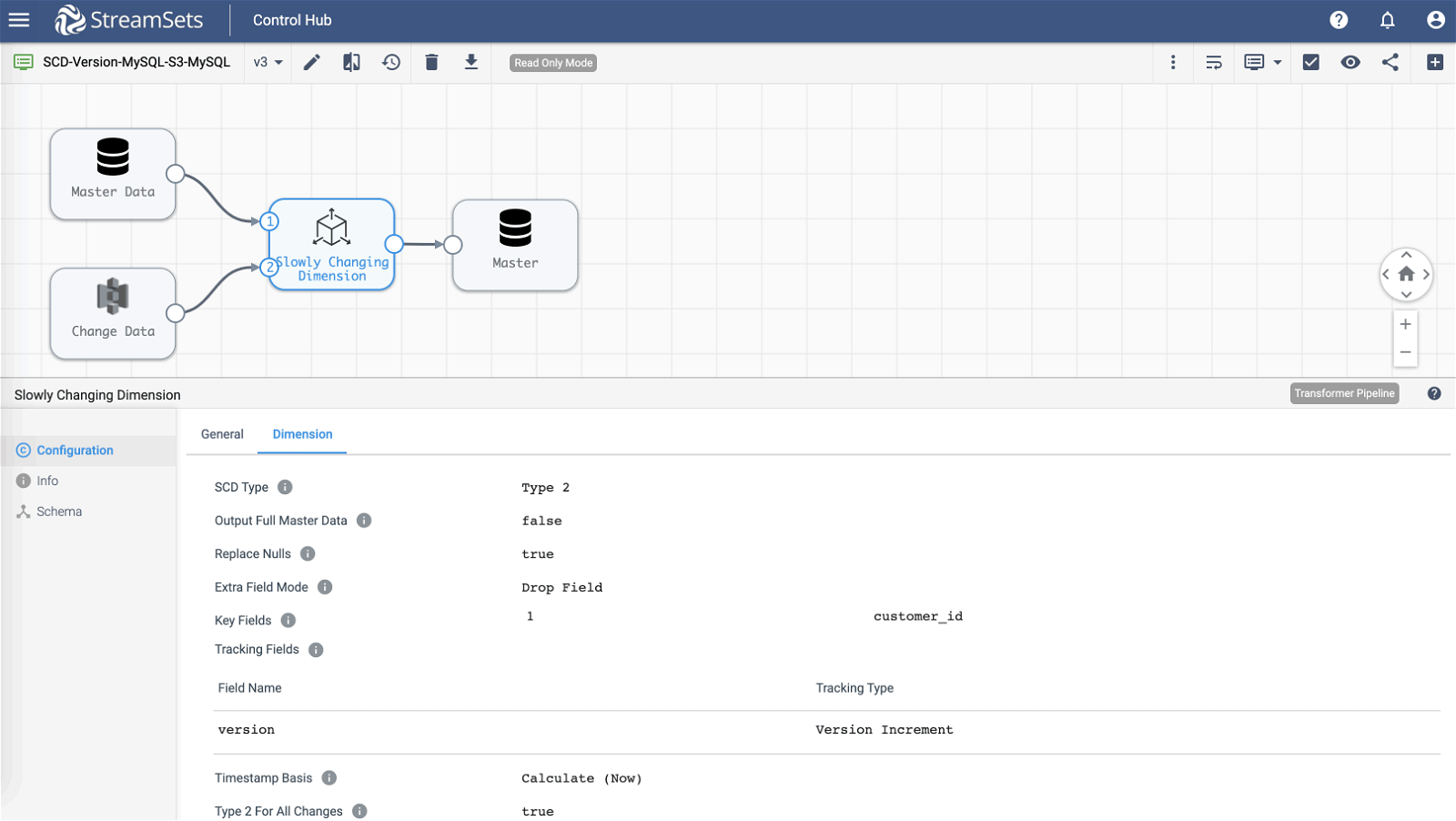
Note: For details on configuration attributes, click here.
The main differences between this and pattern 1 are as follows:
- Pattern 1 is designed to run in batch mode and terminate automatically after all the data has been processed; whereas pipeline in pattern 2 is configured to run in streaming mode–continuously till the pipeline is stopped manually–which means it will “listen” for customer updates being dropped in S3 bucket and process them as soon as they’re available without user intervention.
- Pattern 1 can only handle up to one additional update for any given customer record because of the fact that the master origin is not updated with new version number for every corresponding change record — which effectively means every update record coming in via change origin will get assigned version 2.
- Unlike pattern 1, the master gets updated with the latest version in pattern 2 (via JDBC Producer destination) so every update record coming in via change origin will get a new version assigned to it.
Query customers in MySQL
SELECT * FROM customers where customer_id = 1

Pattern 3: Incremental Updates — Databricks Delta Lake (Streaming mode)
This is very similar to Pattern 2. The main differences are:
- Single origin
- Delta Lake Lookup — For every update/change record coming in a lookup against the current Delta Lake will be performed based on dimension key customer_id. If there’s a match, the values customer_id and version will be returned and passed on to SCD processor. The SCD processor will increment the version number based on the lookup value and a new record with updated version will be inserted into the Delta Lake table.
Sample Pipeline
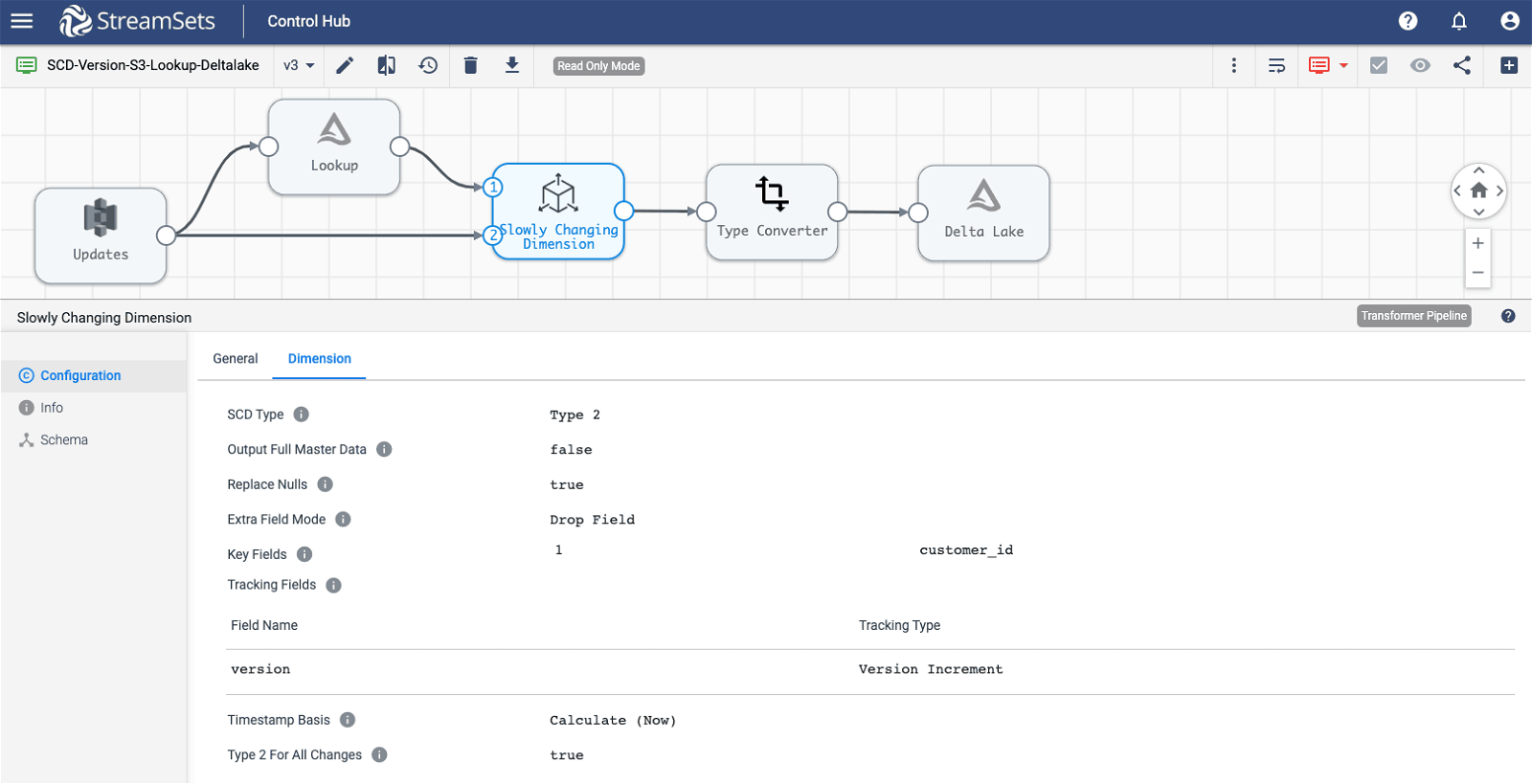
Note: For details on configuration attributes, click here.
Query customers in Delta Lake DBFS
SELECT * FROM delta.`/DeltaLake/customers` where customer_id in (1)

Pattern 4: Upserts — Databricks Delta Lake And Time Travel (Streaming mode)
If you’re using Delta Lake, another option is to leverage Delta Lake’s built-in upserts using merge functionality. Here the underlying concept is the same as SCD which is to maintain versions of dimensions, but the implementation of it is much simpler.
Sample Pipeline
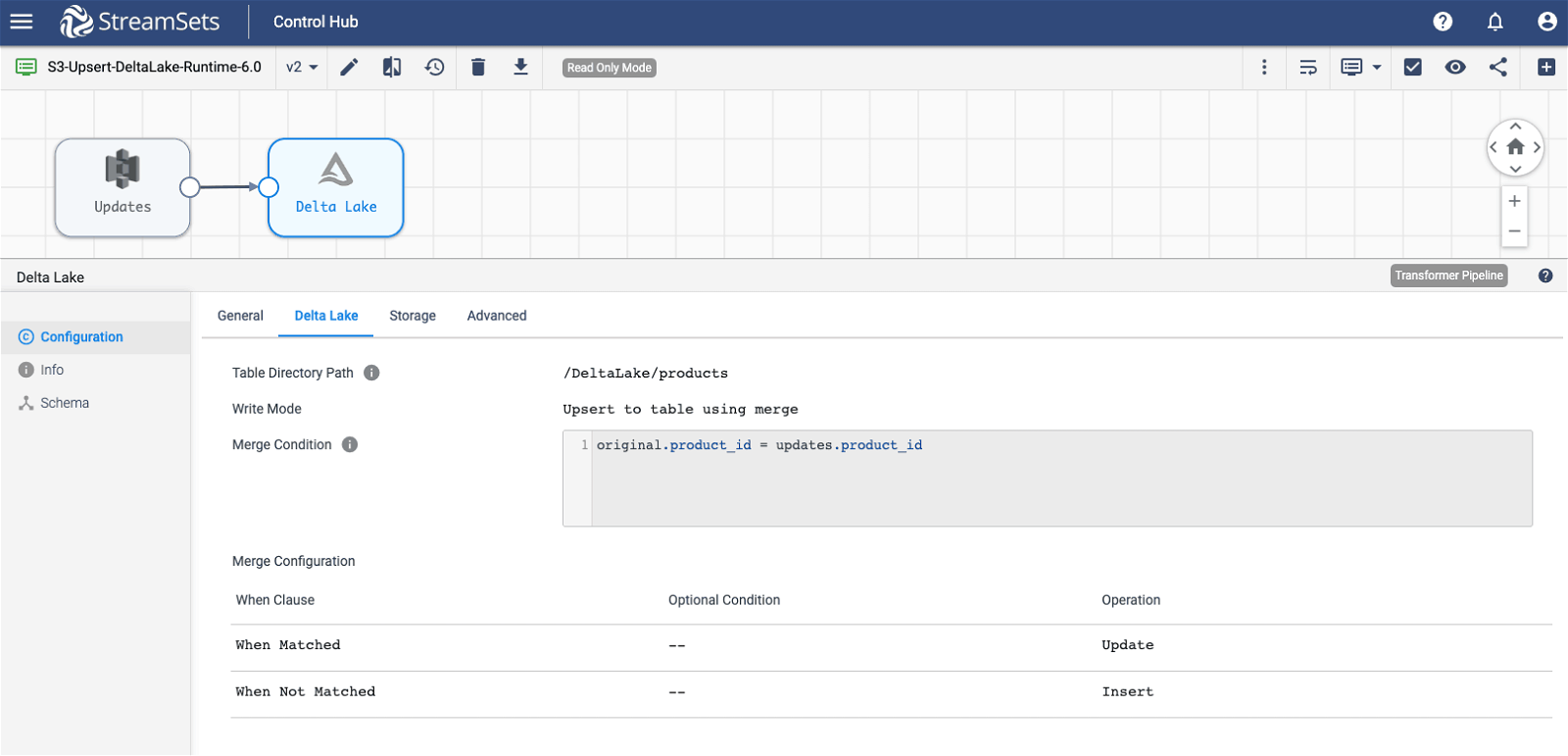
Note: For details on configuration attributes, click here.
In this pattern, for every record coming in via the (S3) origin, an insert or an update operation is performed in Delta Lake based on the conditions configured for new (“When Not Matched”) and existing products (“When Matched”) respectively. And since Delta Lake storage layer supports ACID transactions, it is able to create new (parquet) files for updates — while allowing to query for the most recent record with simple SQL without explicitly requiring tracking field (for example, “version”) to be present in the table and the where clause.
For instance, consider this original record:
product_id,product_category_id,product_name,product_description,product_price 1,2,"Quest Q64 10 FT. x 10 FT. Slant Leg Instant U","",59.98
And this change record with updated price from 59.98 to 69.99
product_id,product_category_id,product_name,product_description,product_price 1,2,"Quest Q64 10 FT. x 10 FT. Slant Leg Instant U","",69.98
Query products in Delta Lake Table
SELECT * FROM products where product_id=1

Note that the table products doesn’t have tracking type field (for example, “version”) while the query still retrieves the most “current” version of the record with product price of $69.98.
To query older versions of the data, Delta Lake provides a feature called “Time Travel”. So in our case, to retrieve the previous (0) version of the product’s price, the SQL query would look like:
SELECT * FROM products VERSION AS OF 0 where product_id=1

Notice the product price of $59.98. For more details and options on Delta Lake Time Travel, click here.
Conclusion
This blog post highlighted some common patterns of handling SCD Type 2 and also illustrated how easy it is to implement those patterns using Slowly Changing Dimension (SCD) processor in StreamSets Transformer.
If you’d like to learn more about StreamSets Transformer, here are some useful resources for you to get started: Product overview | Technical documentation | Overview video | Datasheet | Blogs.