In part 1, you learned how to extend StreamSets Transformer in order to train Spark ML RandomForestRegressor model.
In this part 2, you will learn how to create Spark MLeap bundle to serialize the trained model and save the bundle to Amazon S3.
MLeap is a common serialization format and execution engine for machine learning pipelines. It supports Spark, Scikit-learn and Tensorflow for training pipelines and exporting them to an MLeap Bundle. Serialized pipelines (bundles) can be deserialized back into Spark for batch-mode scoring or the MLeap runtime to power realtime API services.
For more details on MLeap, click here.
StreamSets Transformer Pipeline Overview
Before we dive into code, here is the extended pipeline overview.
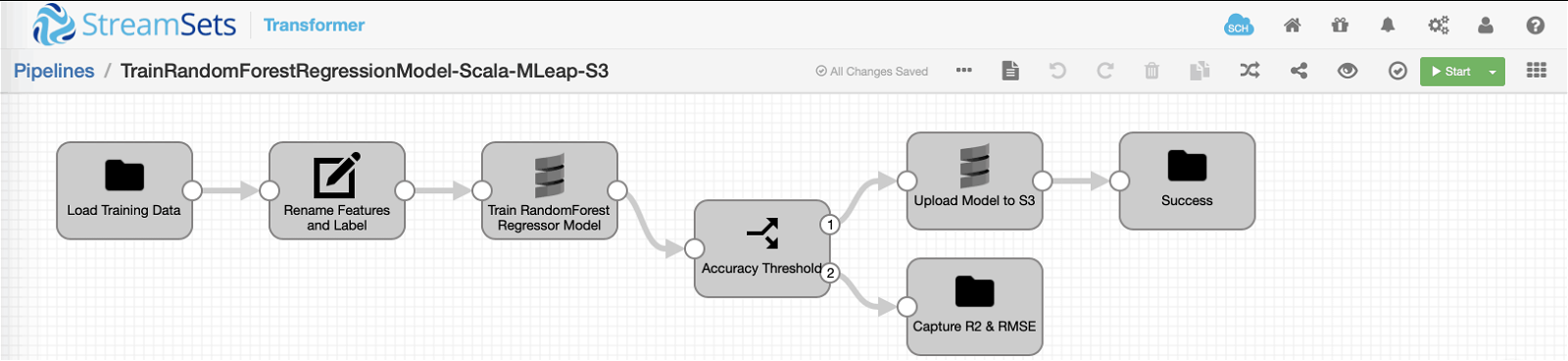
Prerequisites: For this pipeline to run, these external libraries must be installed from the UI via Package Manager under Basic Stage Library. (Note that this will require Transformer restart.)
Scala Processor
Below is the additional Scala code that takes the trained model, creates an MLeap bundle, and stores that in a temporary location as defined by saveModelZipPath variable.
For details on input data, preparing features and other such details, refer to part 1.
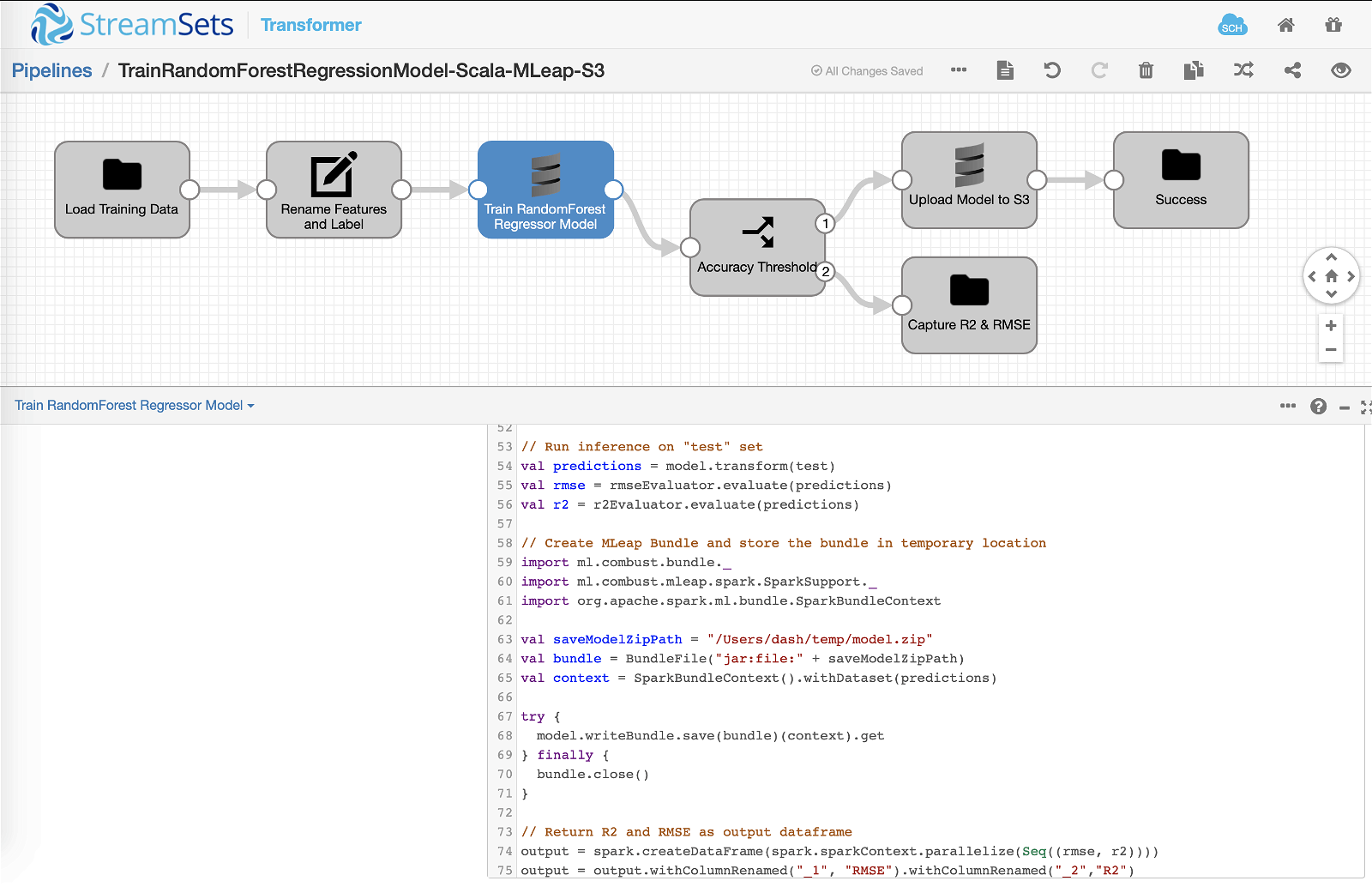
Here’s the entire code snippet that’s inserted into Scala processor >> Scala >> Scala Code section. The code of interest is from lines 61 to 74.
// Import required libraries
import spark.implicits._
import scala.collection.mutable.Buffer
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.{RandomForestRegressionModel, RandomForestRegressor}
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
// Setup variables for convenience and readability
val features = Array("TV", "Radio", "Newspaper")
val trainSplit = 80
val testSplit = 20
val numberOfTrees = 30
val numberOfCVFolds = 3
val treeDepth = 3
// The input dataframe is accessbile via inputs(0)
var df = inputs(0)
// MUST for Spark features
val assembler = new VectorAssembler().setInputCols(features).setOutputCol("features")
// Transform features
df = assembler.transform(df)
// Split dataset into "train" and "test" sets
val Array(train, test) = df.randomSplit(Array(trainSplit, testSplit), 42)
// Create RandomForestRegressor instance with hyperparameters "number of trees" and "tree depth"
// NOTE: In production, hyperparameters should be tuned to create more accurate models.
val rf = new RandomForestRegressor().setNumTrees(numberOfTrees).setMaxDepth(treeDepth)
// Setup pipeline
val pipeline = new Pipeline().setStages(Array(rf))
// Setup hyperparams grid
val paramGrid = new ParamGridBuilder().build()
// Setup model evaluators
// Note: By default, it will show how many units off in the same scale as the target -- RMSE
val rmseEvaluator = new RegressionEvaluator()
// Select R2 as our main scoring metric
val r2Evaluator = new RegressionEvaluator().setMetricName("r2")
// Setup cross validator
val cv = new CrossValidator().setNumFolds(numberOfCVFolds).setEstimator(pipeline).setEstimatorParamMaps(paramGrid).setEvaluator(r2Evaluator)
// Fit model on "train" set
val cvModel = cv.fit(train)
// Get the best model based on CrossValidator
val model = cvModel.bestModel.asInstanceOf[PipelineModel]
// Run inference on "test" set
val predictions = model.transform(test)
val rmse = rmseEvaluator.evaluate(predictions)
val r2 = r2Evaluator.evaluate(predictions)
// Create MLeap Bundle and store the bundle in temporary location
import ml.combust.bundle._
import ml.combust.mleap.spark.SparkSupport._
import org.apache.spark.ml.bundle.SparkBundleContext
val saveModelZipPath = "/Users/dash/temp/model.zip"
val bundle = BundleFile("jar:file:" + saveModelZipPath)
val context = SparkBundleContext().withDataset(predictions)
try {
model.writeBundle.save(bundle)(context).get
} finally {
bundle.close()
}
// Return R2 and RMSE as output dataframe
output = spark.createDataFrame(spark.sparkContext.parallelize(Seq((rmse, r2))))
output = output.withColumnRenamed("_1", "RMSE").withColumnRenamed("_2","R2")
Note: Under the covers, this custom code is compiled into a jar and handed-off to the underlying execution engine — which in this case is Spark.
Stream Selector Processor
In this processor we’re checking to see if our accuracy “threshold” is met by comparing the value of R2 that was calculated after training the model and running inference on “test” set.
Note: Similarly, other condition(s) can be applied to any metric calculated and made available during model training process.
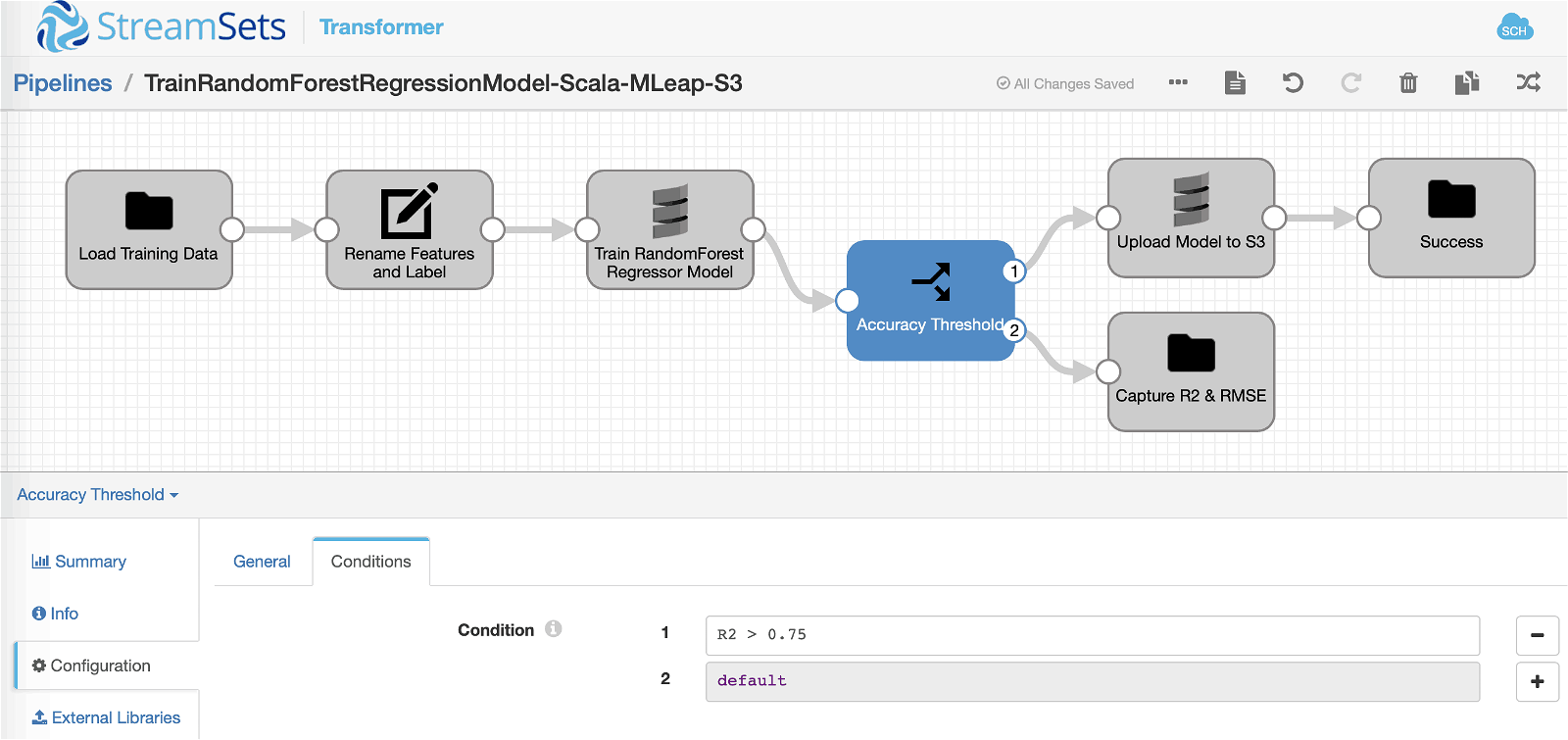
Scala Processor
If the accuracy “threshold” of R2 > 0.75 is met, the pipeline execution will continue down this path and the following Scala code will get executed. The code snippet takes the MLeap bundle (“model.zip”) created during the model training process and uploads it to Amazon S3.
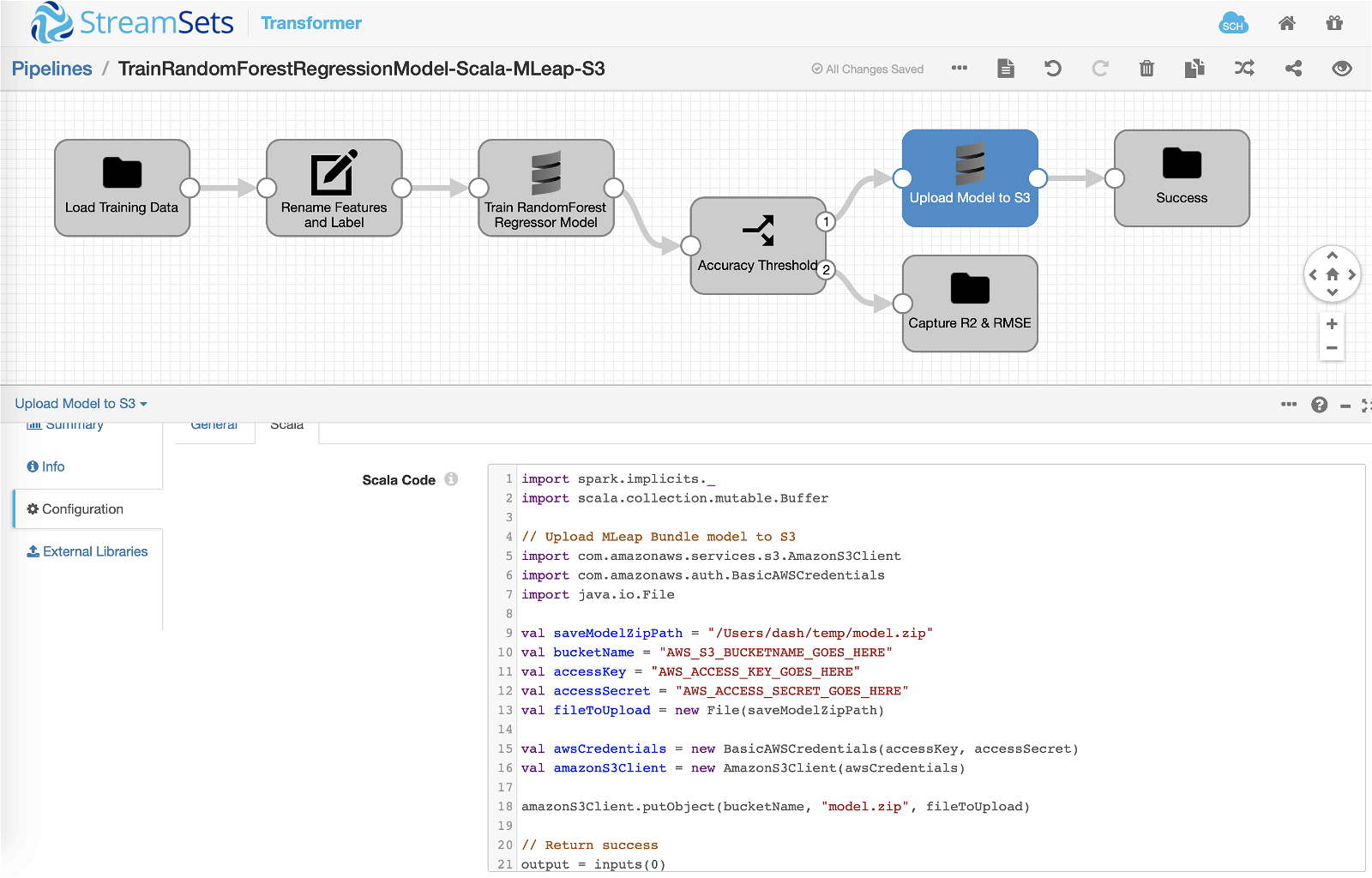
Here’s the Scala code inserted into Scala processor >> Scala >> Scala Code section.
// Import required libraries import spark.implicits._ import scala.collection.mutable.Buffer import com.amazonaws.services.s3.AmazonS3Client import com.amazonaws.auth.BasicAWSCredentials import java.io.File // Upload MLeap Bundle model to S3 val saveModelZipPath = "/Users/dash/temp/model.zip" val bucketName = "AWS_S3_BUCKETNAME_GOES_HERE" val accessKey = "AWS_ACCESS_KEY_GOES_HERE" val accessSecret = "AWS_ACCESS_SECRET_GOES_HERE" val fileToUpload = new File(saveModelZipPath) val awsCredentials = new BasicAWSCredentials(accessKey, accessSecret) val amazonS3Client = new AmazonS3Client(awsCredentials) amazonS3Client.putObject(bucketName, "model.zip", fileToUpload) // Return success output = inputs(0)
Output
Assuming things go well without any errors, running the pipeline will result in serialized MLeap bundle (“model.zip”) getting uploaded to Amazon S3 as shown below.
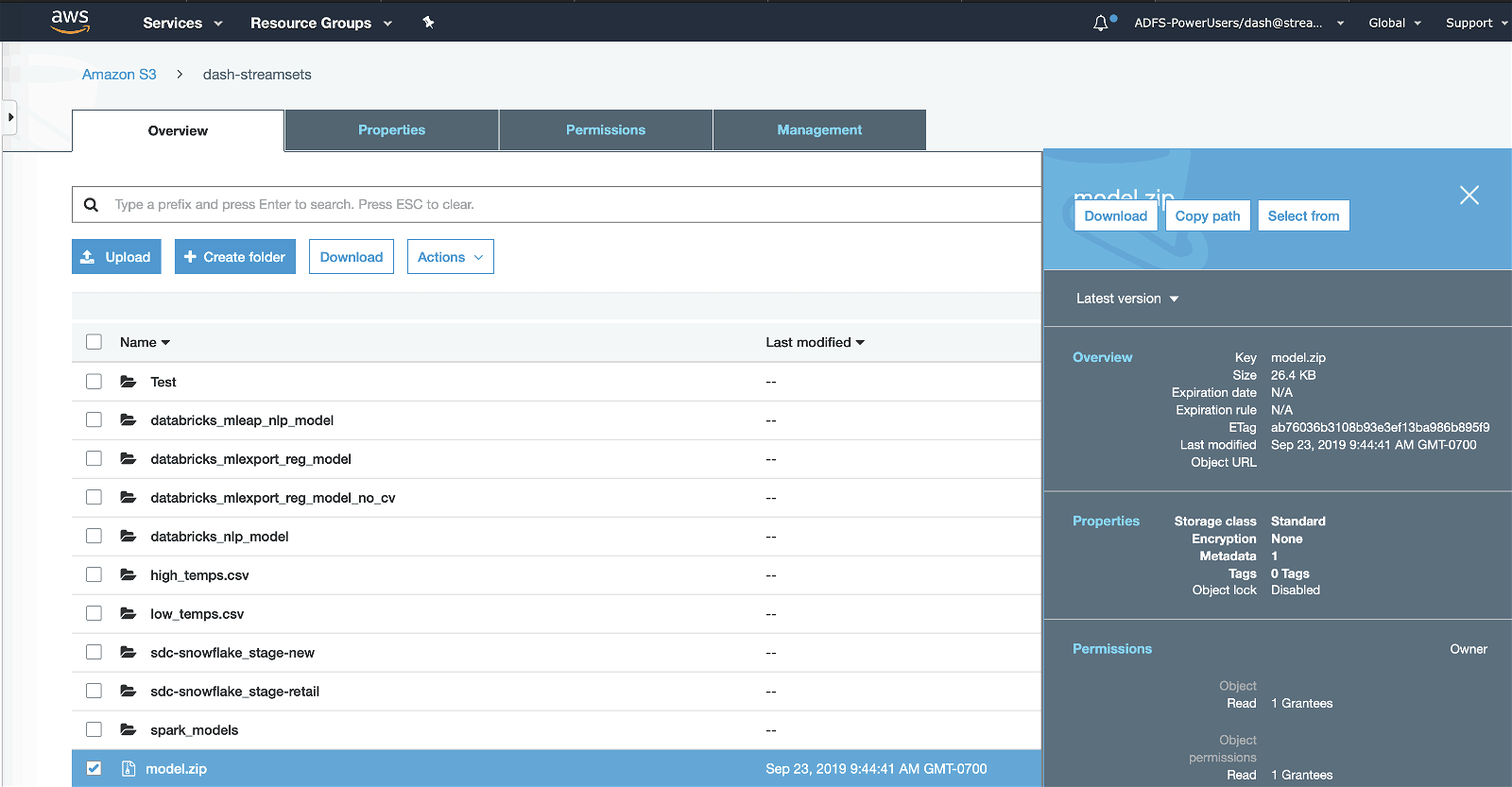
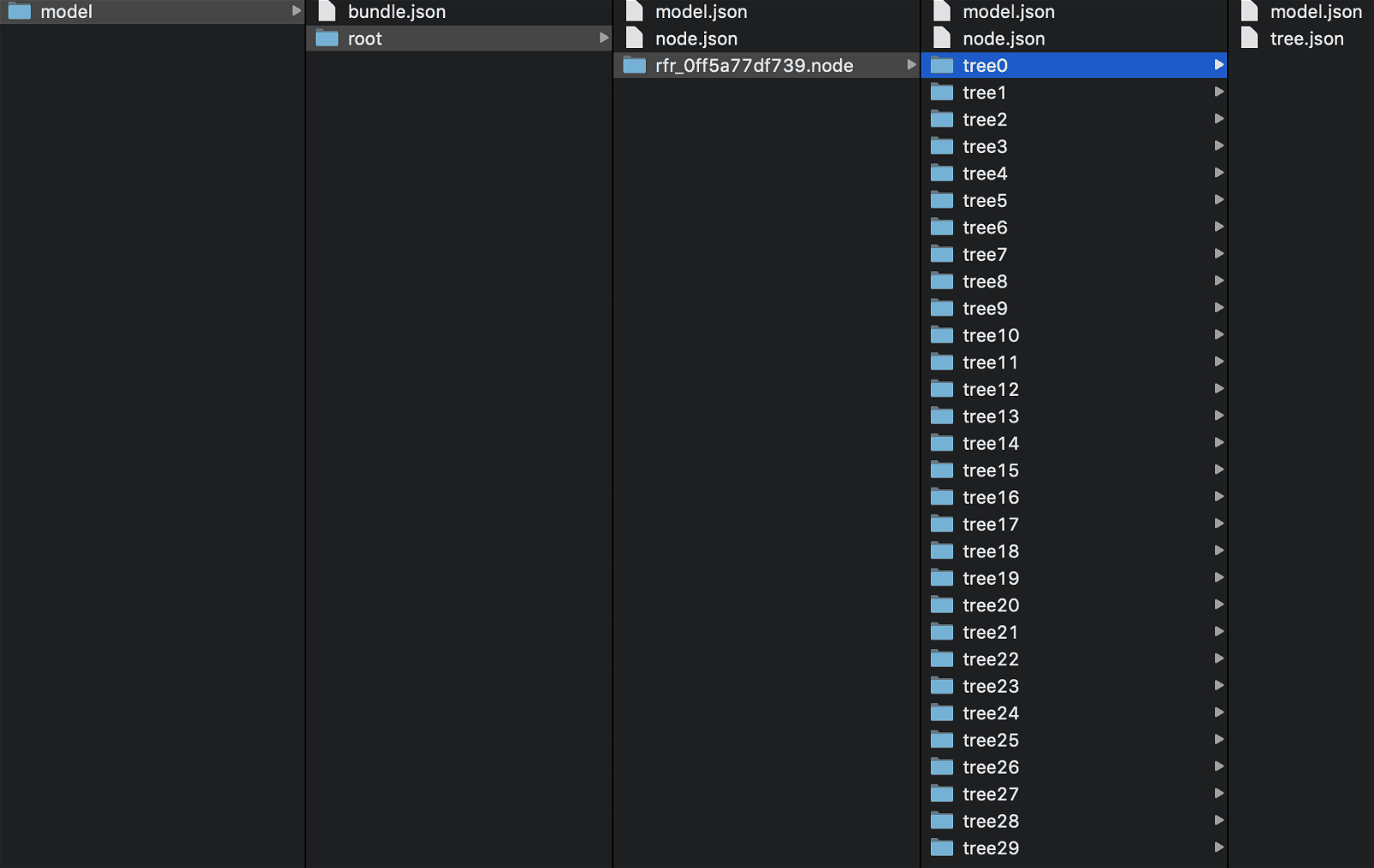
Note that downloading the serialized MLeap bundle (“model.zip”) from Amazon S3 should reveal trained Spark ML model’s contents similar to as shown below.
Stay tuned!
In this blog you learned how easily you can extend StreamSets Transformer’s functionality. In particular, you learned how to incorporate custom Scala code to train the Spark ML machine learning model, create a serialized MLeap bundle for it, and upload that to Amazon S3.
In part 3, I will illustrate how to load the serialized MLeap bundle and use the model for prediction on new data flowing through StreamSets Transformer pipeline. Stay tuned!
To learn more about StreamSets Transformer visit our website, refer to the documentation, join the webinar, and download the binaries.
UPDATE
I’ve published part 3 mentioned above which illustrates how to load the serialized MLeap bundle and use the model for prediction on new data flowing through StreamSets Transformer — Streaming Analysis Using Spark ML in StreamSets DataOps Platform.