Apache Spark has been on the rise for the past few years and it continues to dominate the landscape when it comes to in-memory and distributed computing, real-time analysis and machine learning use cases. How can you quickly leverage the benefits and power of Apache Spark with minimal operational and configuration overhead? Introducing StreamSets Transformer, a powerful tool for creating highly instrumented Apache Spark applications for modern ETL.
In this blog, you will learn how to extend StreamSets Transformer in order to train Spark ML RandomForestRegressor model.
StreamSets Transformer Extensibility
While StreamSets DataOps platform as a whole empowers you to all things DataOps, StreamSets Transformer takes it a few steps further and also enables you to incorporate and automate some of the more common tasks involved in Spark for machine learning. For example, data preparation by way of combining, joining and enriching training datasets from multiple sources, renaming features, converting datatypes of features to those expected by machine learning algorithms, etc.
In addition, StreamSets Transformer also provides a way for you to extend its functionality by writing custom Scala and PySpark code as part of your data pipelines. These new capabilities and extensibility aspect of the platform opens doors for automating ML tasks, such as, training machine learning models.
StreamSets Transformer Pipeline Overview
Before we dive into code, here is the high-level pipeline overview.
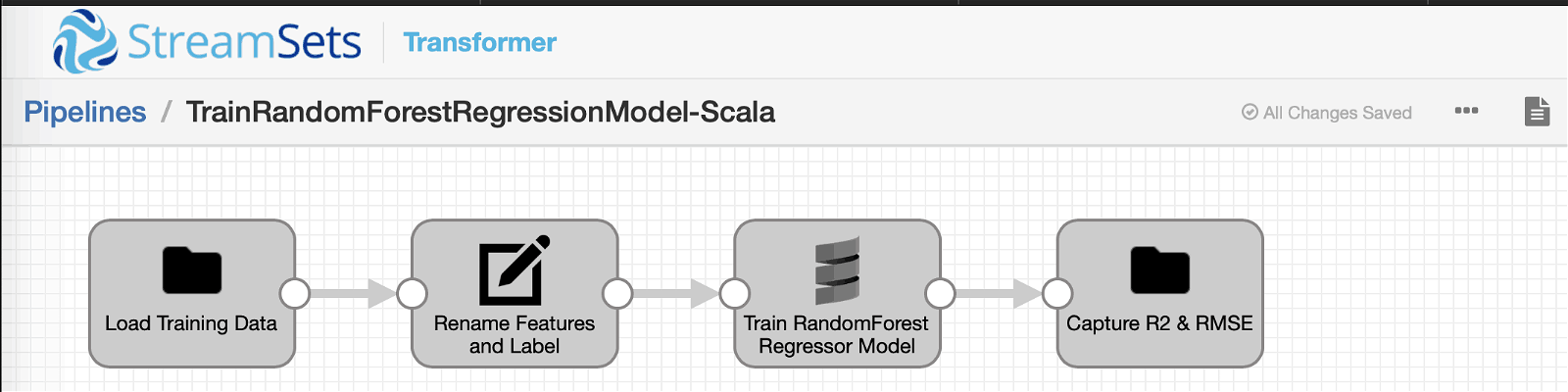
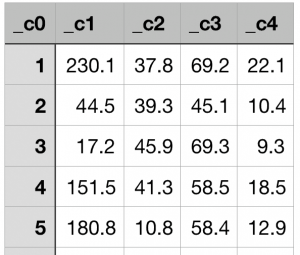
Input
A delimited (.csv) file that contains historical advertising budgets (in 1000s of USD) for media channels–TV, Radio and Newspapers–and their sales (in 1000s of units).
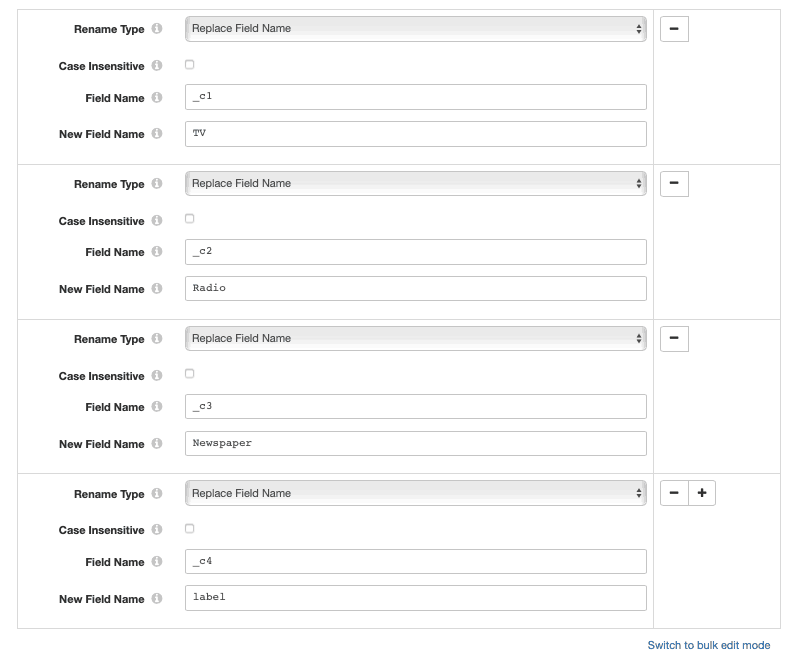
Field Renamer
This processor renames columns (aka features to be used for model training) to be more human readable — “_c1” → “TV”, “_c2” → “Radio”, and “_c3” → “Newspaper”.
More importantly, it also renames column “_c4” which represents “Sales” (== number of units sold) to “label” which is a must/required thing for Spark ML.
Scala Processor
The pipeline loads training dataset as described above and passes it down to the Scala processor that encapsulates custom code to train Spark ML RandomForestRegressor model. The model is trained to predict sales (== number of units sold) based on advertising budgets allocated to TV, Radio and Newspapers media channels.
Prerequisites: For the pipeline to run our custom Scala code, the following external libraries must be installed from the UI via Package Manager under Basic Stage Library. (Note that this will require Transformer restart.)
Meat of the machine learning pipeline!
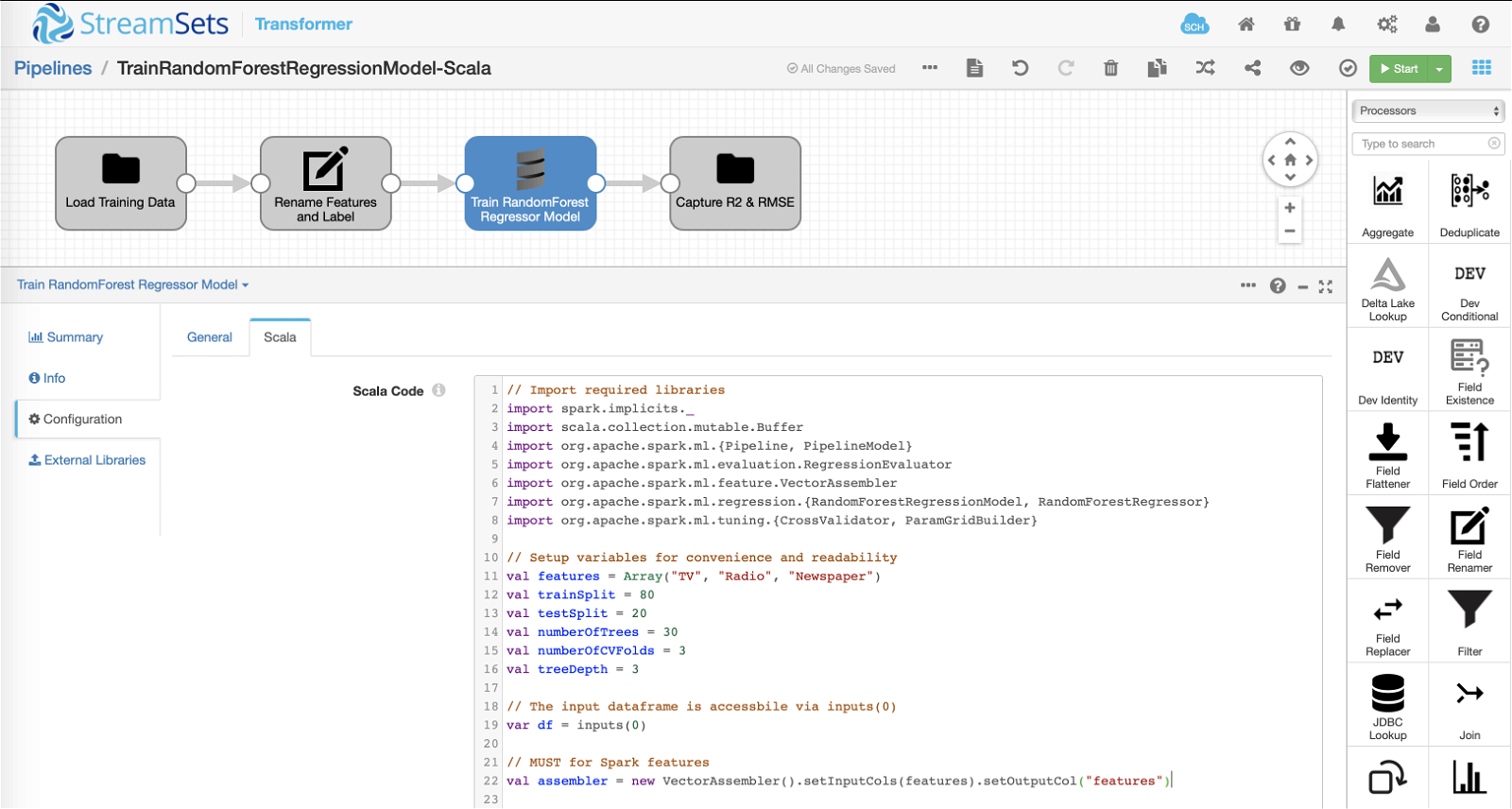
Below is the Scala code inserted into Scala processor >> Scala >> Scala Code section. It basically takes the input data and trains Spark ML RandomForestRegressor model–while incorporating train-test split, hyperparameter tuning, and cross-validation. (See in-line comments for a walk-through.)
// Import required libraries
import spark.implicits._
import scala.collection.mutable.Buffer
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.{RandomForestRegressionModel, RandomForestRegressor}
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
// Setup variables for convenience and readability
val features = Array("TV", "Radio", "Newspaper")
val trainSplit = 80
val testSplit = 20
val numberOfTrees = 30
val numberOfCVFolds = 3
val treeDepth = 3
// The input dataframe is accessbile via inputs(0)
var df = inputs(0)
// MUST for Spark features
val assembler = new VectorAssembler().setInputCols(features).setOutputCol("features")
// Transform features
df = assembler.transform(df)
// Split dataset into "train" and "test" sets
val Array(train, test) = df.randomSplit(Array(trainSplit, testSplit), 42)
// Create RandomForestRegressor instance with hyperparameters "number of trees" and "tree depth"
// NOTE: In production, hyperparameters should be tuned to create more accurate models.
val rf = new RandomForestRegressor().setNumTrees(numberOfTrees).setMaxDepth(treeDepth)
// Setup pipeline
val pipeline = new Pipeline().setStages(Array(rf))
// Setup hyperparams grid
val paramGrid = new ParamGridBuilder().build()
// Setup model evaluators
// Note: By default, it will show RMSE -- how many units off in the same scale as the target
val rmseEvaluator = new RegressionEvaluator()
// Set R2 as our main scoring metric
val r2Evaluator = new RegressionEvaluator().setMetricName("r2")
// Setup cross validator
val cv = new CrossValidator().setNumFolds(numberOfCVFolds).setEstimator(pipeline).setEstimatorParamMaps(paramGrid).setEvaluator(r2Evaluator)
// Fit model on "train" set
val cvModel = cv.fit(train)
// Get the best model based on CrossValidator
val model = cvModel.bestModel.asInstanceOf[PipelineModel]
// Run inference on "test" set
val predictions = model.transform(test)
val rmse = rmseEvaluator.evaluate(predictions)
val r2 = r2Evaluator.evaluate(predictions)
// Return R2 and RMSE as output dataframe
output = spark.createDataFrame(spark.sparkContext.parallelize(Seq((rmse, r2))))
output = output.withColumnRenamed("_1", "RMSE").withColumnRenamed("_2","R2")
Note: Under the covers this custom code is compiled into a jar and handed-off to the underlying execution engine — which in this case is Spark.
Output
Assuming all goes well, the “output” dataframe will contain “R2” and “RMSE” written out to a file in a location configured in the File destination labeled “Capture R2 and RMSE” in the above pipeline. And, for example, if Data Format of the File destination is set to JSON, the contents of the JSON file might look similar to:
{“RMSE”:2.133713963903168,”R2″:0.7982041432604049}
It goes without saying that the model accuracy will depend on the size and quality of the training dataset as well as which hyperparameters are tuned. :)
Summary
In this blog you learned how easily you can extend StreamSets Transformer’s functionality. In particular, you learned how to incorporate custom Scala code to train Spark ML machine learning model. In a similar fashion, you can also write custom code using the Python API for Spark, or PySpark and use built-in PySpark processor.
While the platform is easily extensible, it’s important to note that the custom code still leverages underlying, built-in features and power of StreamSets Transformer. To name a few:
- Executing on any Spark cluster, on-prem on Hadoop or on cloud hosted Spark services, for example, Databricks.
- Progressive error handling to learn exactly where and why errors occur, without needing to decipher complex log files.
- Highly instrumented pipelines that reveal exactly how every operation, and the application as a whole, is performing.
Learn more about Spark for ETL and machine learning using StreamSets Transformer.
UPDATE
In part 2, I’ve illustrated how to create Spark MLeap bundle to serialize the trained model and save the bundle to Amazon S3.