The emerging practice of DataOps encompasses many activities that an enterprise may execute today including ingestion, ETL, and real-time stream processing. The trick to DataOps is to execute these things in concert with global visibility, central control, and unparalleled insight into performance and security. The StreamSets DataOps platform provides a foundational capability for modern companies to build a DataOps practice with powerful tools for ingestion, light-weight transformation, IoT connectivity, and data security.
Until recently, users had to explore solutions outside of the platform for one of the most common data processing workloads: Extract, Transform, and Load (ETL). The reasons for this were two fold. First, the market was already saturated with tools for ETL and in a world where most data was structured and static those tools mainly fulfilled the needs of our customers. Secondly, the boundaries between how companies viewed their management and handling of streaming data vs. batch processes was still fairly separate.
Fast forward to 2019. Data is abundant, in a million shapes and sizes, and the considerations for whether a workload is batch or streaming are becoming less important to the end consumers. At the same time, we have seen an explosive rise in a particular in-memory access engine that is setting the pace for the ecosystem.
Apache Spark and Modern ETL
Apache Spark has risen to be the de-facto data processing engine for modern analytics. Its native language interface, unmatched performance, and easy scalability have broken the paradigms of what is possible with modern ETL. It provides a powerful engine that can power some of the most aspirational workloads. However, Apache Spark is a tool too often relegated to mature data teams with significant skills investments. Developers execute Spark jobs on massive sets of data but often have little visibility into how their Spark jobs are running. If something does go wrong they are forced to sift through cryptic log files to find the culprit.
More companies yearn to democratize data engineering and simplify the operation of Apache Spark. While Scala, Java, and Python provide familiar interfaces for experienced coders, ETL developers and savvy data professionals are not able to leverage Spark without the intervention of an experienced data engineer. Even for mature Spark developers, the cumbersome nature of stitching together code for repeatable pipelines becomes a low value activity.
A New Addition to the DataOps Platform
To solve these problems and complete the execution layer of the StreamSets DataOps Platform we are extremely proud to announce the immediate general availability of StreamSets Transformer, a powerful tool for creating highly instrumented Apache Spark applications for modern ETL.
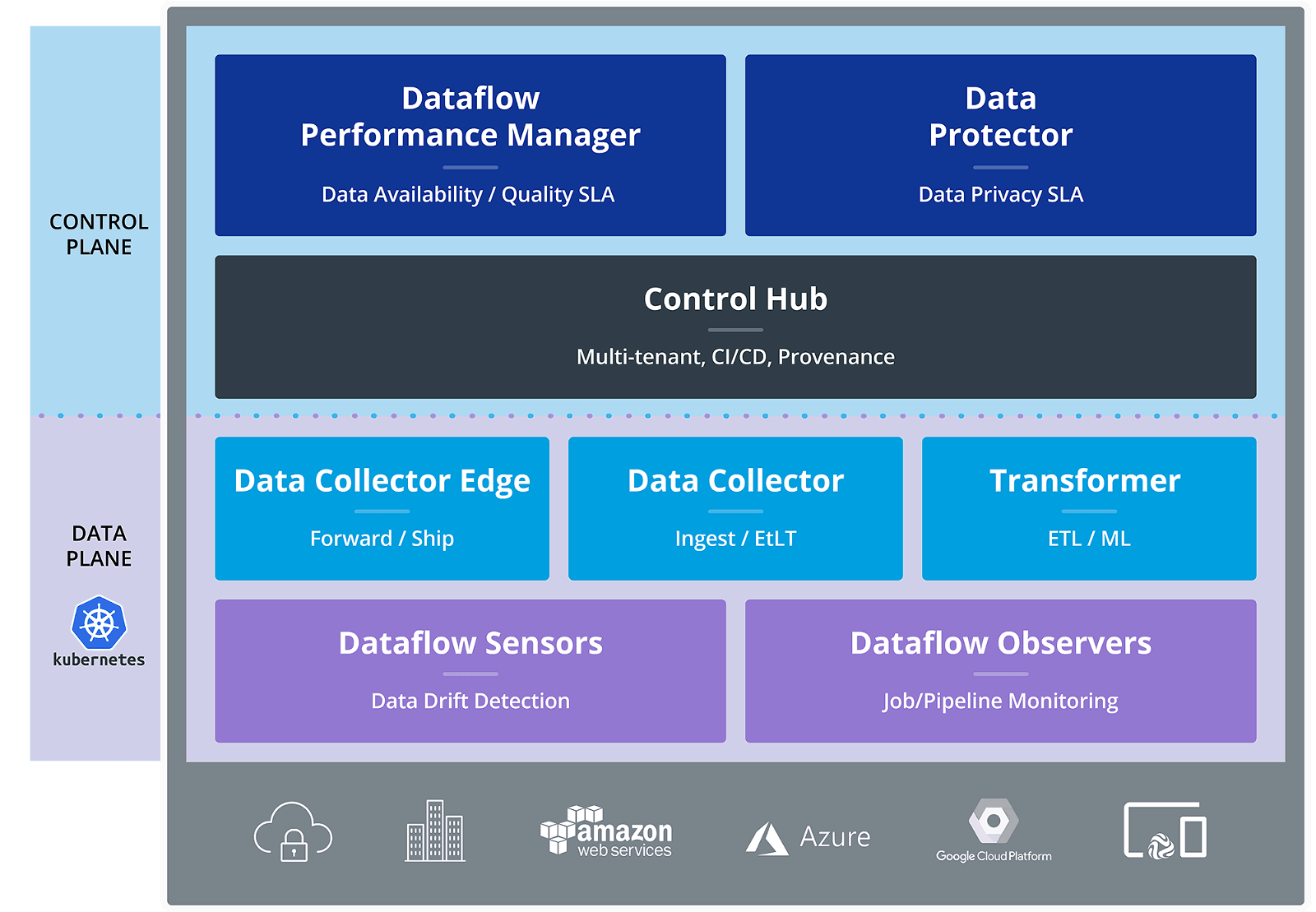
StreamSets Transformer is a critical new capability of the DataOps platform. Now, you do not have to be concerned, or even aware if the pipeline is batch, microbatch, or streaming. You design pipelines the same way and are abstracted away from the underlying variability in the execution. If StreamSets Data Collector is about heterogeneous connectivity, then Transformer is about the Big “T” of ETL for batch processing against much larger datasets.
StreamSets Transformer
StreamSets Transformer is an execution engine within the StreamSets DataOps platform that allows users to create data processing pipelines that execute on Spark. Using a simple to use drag and drop UI users can create pipelines for performing ETL, stream processing and machine learning operations. It allows everyone including the Data Analyst, Data Scientist or legacy ETL developer, not just the savvy Spark developer, to fully utilize the power of Apache Spark without requiring a deep technical understanding of the platform.
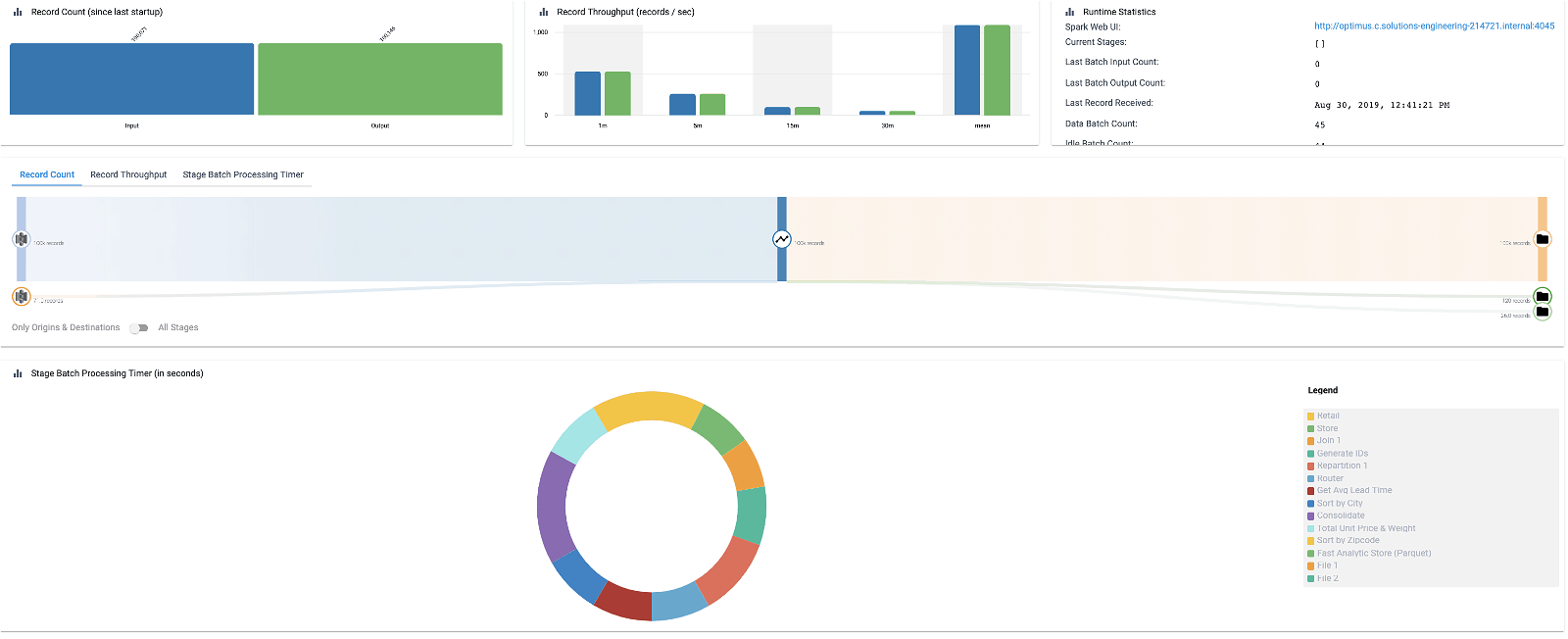
Transformer pipelines are heavily instrumented and provide deep visibility into the execution of Spark applications. Users can see exactly how long every operation takes, how much data gets transferred at every stage, and view proactive and contextual error messages if and when problems occur. These features further abstract the user away from the internals of the Spark cluster and allow them to solve the core business problem.
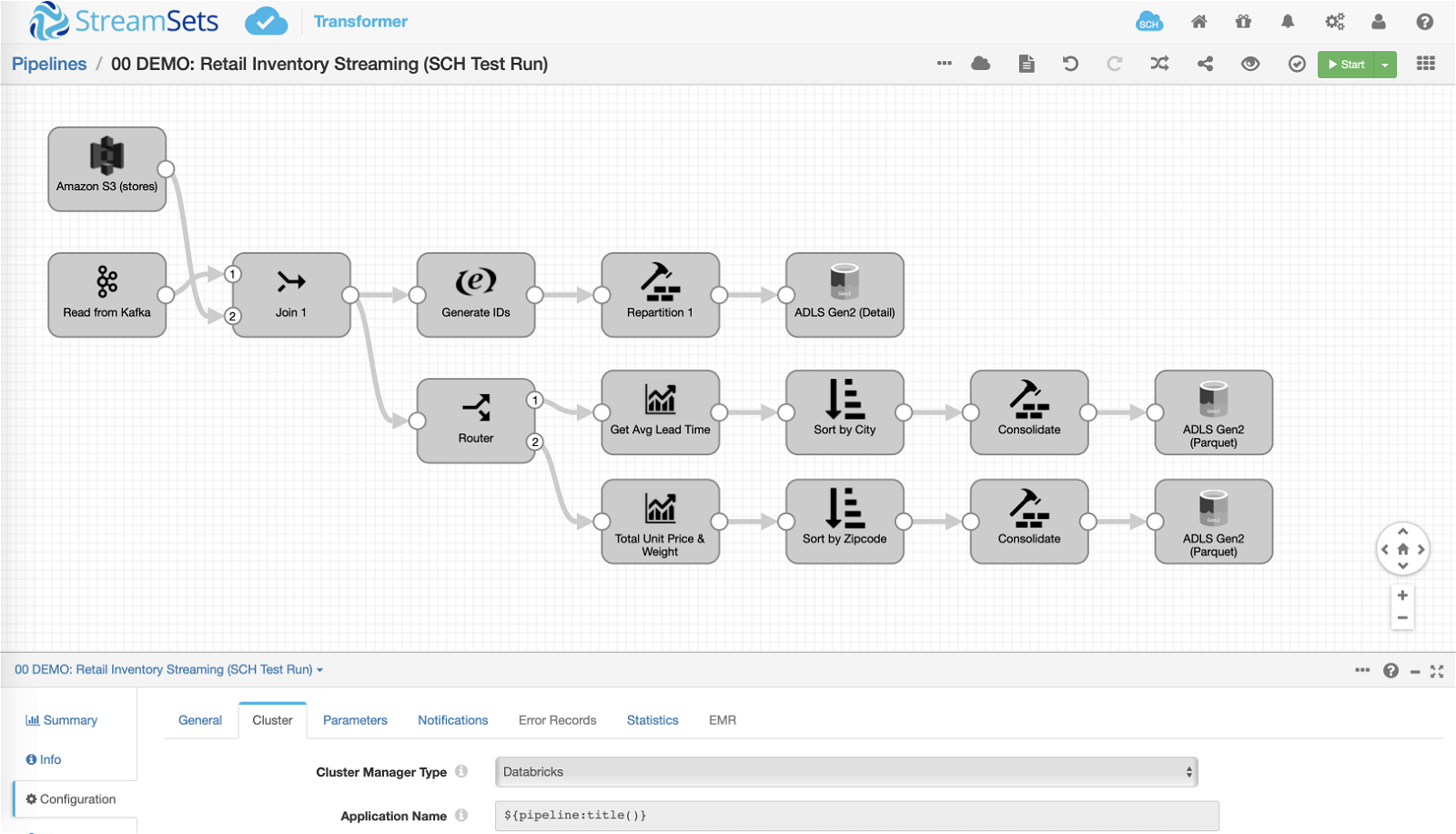 Pipelines can read from and write to Batch or Streaming sources and destinations and mix and match as they choose. Users never have to make batch, streaming, lamda, kappa architectural decisions when designing pipelines, instead they focus on working with Continuous Data (data as, when and where they need).
Pipelines can read from and write to Batch or Streaming sources and destinations and mix and match as they choose. Users never have to make batch, streaming, lamda, kappa architectural decisions when designing pipelines, instead they focus on working with Continuous Data (data as, when and where they need).
Learn More
We believe that StreamSets Transformer is different than any product you have seen before. But don’t believe us, see more for yourself. To learn more about StreamSets Transformer visit our website, join the webinar, and download the binaries today.