Introduction: from HDFS Data to S3
I am very excited to announce the new Hadoop FS Standalone origin in StreamSets Data Collector 3.2.0.0. Data Collector has long supported the Hadoop FS origin, but only in the cluster mode. The Hadoop FS (HDFS) Standalone origin does not need MapReduce or YARN installed and can run in multithreaded mode, with each thread reading one file at a time in parallel.
The great thing about Data Collector is that all the stage libraries, containing origins, processors, destinations, and executors, are pluggable. In this article, our use case is synchronizing data from HDFS into Amazon S3, but you can use any Data Collector destination that supports whole file data format, such as Azure Data Lake Store, Hadoop FS, Google Cloud Storage, or MapR FS.
The Cluster Mode Hadoop FS Origin
Running a pipeline with the Hadoop FS origin in cluster mode is a great way to migrate data from HDFS to another Hadoop cluster or other data stores like Azure, Google Cloud Storage, or MapR FS. To run in a pipeline in cluster mode, Data Collector must be installed in the Hadoop system so it can submit MapReduce jobs to YARN.
For example, you can migrate data from blob storage using the Hadoop FS origin in cluster mode to Amazon S3. In this case, Data Collector needs to be installed in HDInsight (Azure’s Hadoop cluster). You can find Data Collector for HDInsight in the Azure marketplace.
Lastly, the Hadoop FS origin in cluster mode supports Avro, Delimited, and Text data formats.
The Simplicity of Using Hadoop FS Standalone
With the Hadoop FS Standalone origin, Data Collector does not need MapReduce or YARN, nor need to be in the Hadoop cluster at all. You can even run Data Collector on your local machine to move data from Azure Blob Storage to Amazon S3.
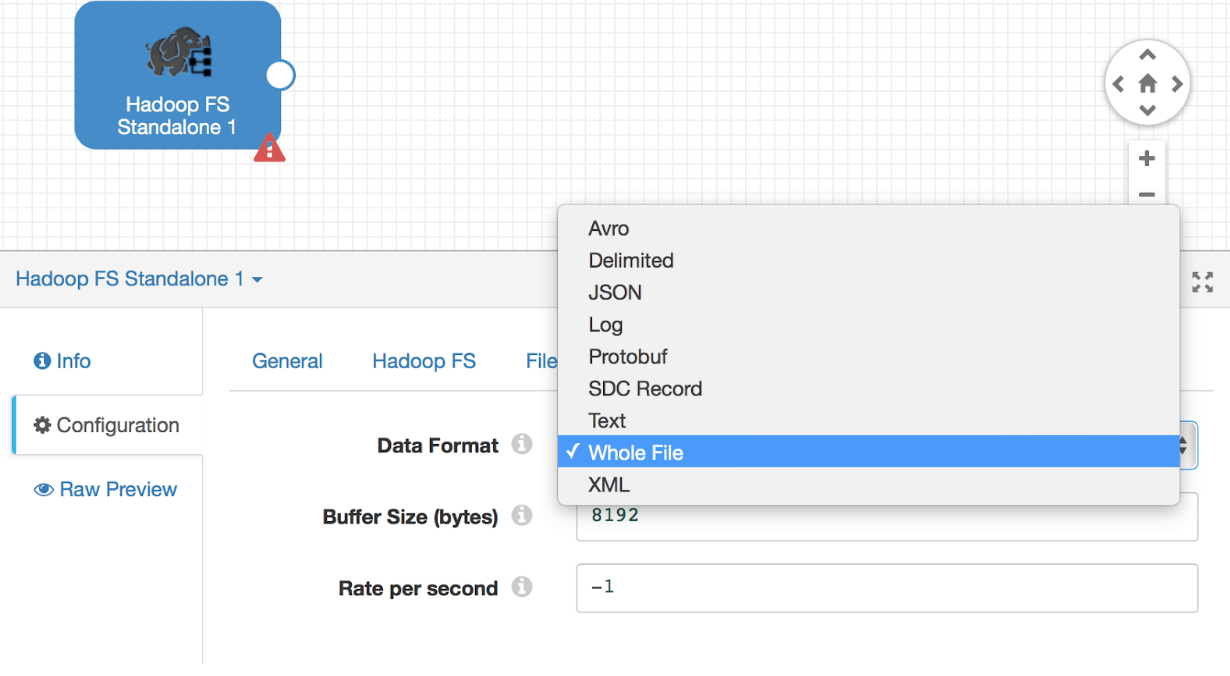
The Hadoop FS Standalone origin also supports a much wider range of data formats such as Avro, Delimited, JSON, LOG, Protobuf, SDC Record, Text, Whole File, and XML
The Hadoop FS Standalone Configuration
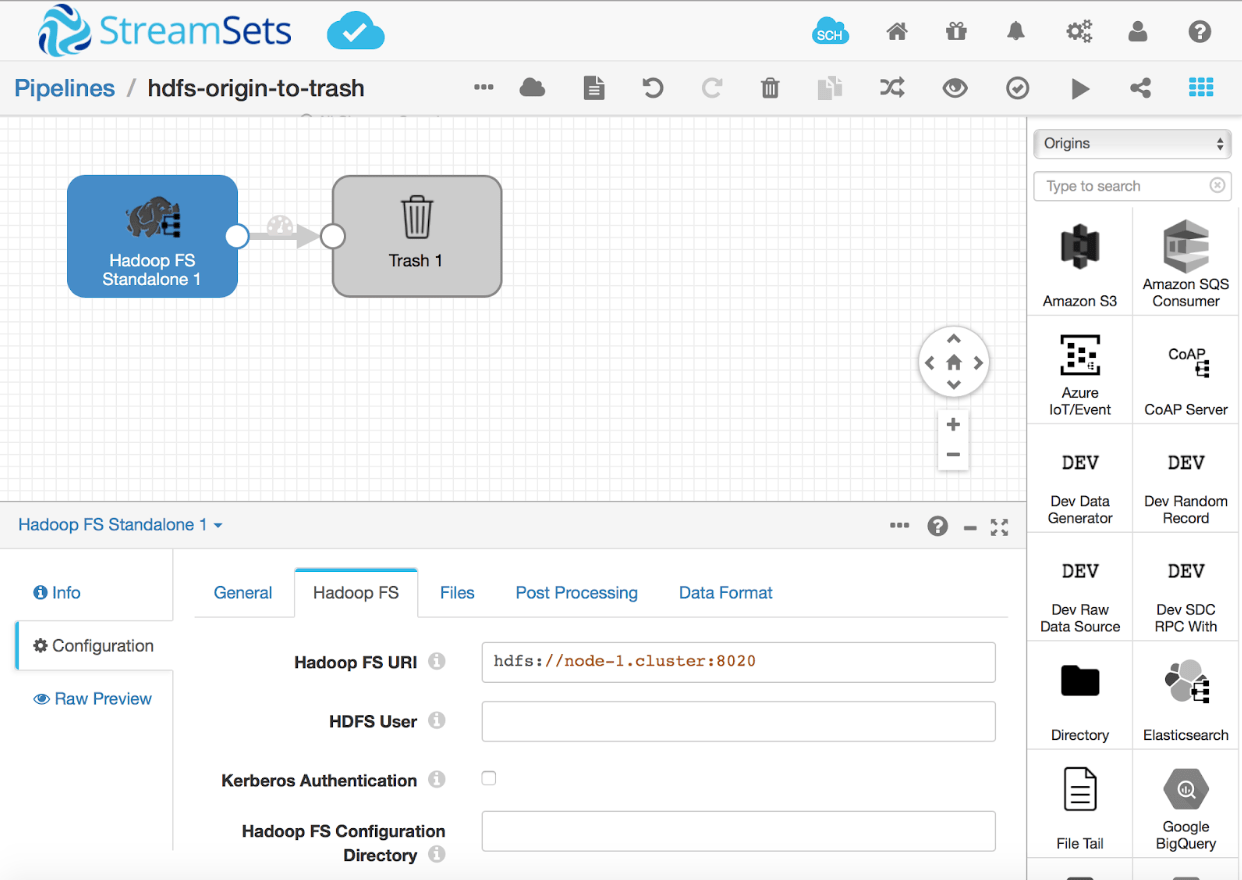
Let’s first start with the Hadoop FS Standalone origin. You can configure Hadoop FS connection information in the Hadoop FS tab shown below. Make sure that the Inter Process Communicator port (IPC) for name node is open and that the user has access to the files. You can impersonate to grant to the file by configuring the HDFS User.
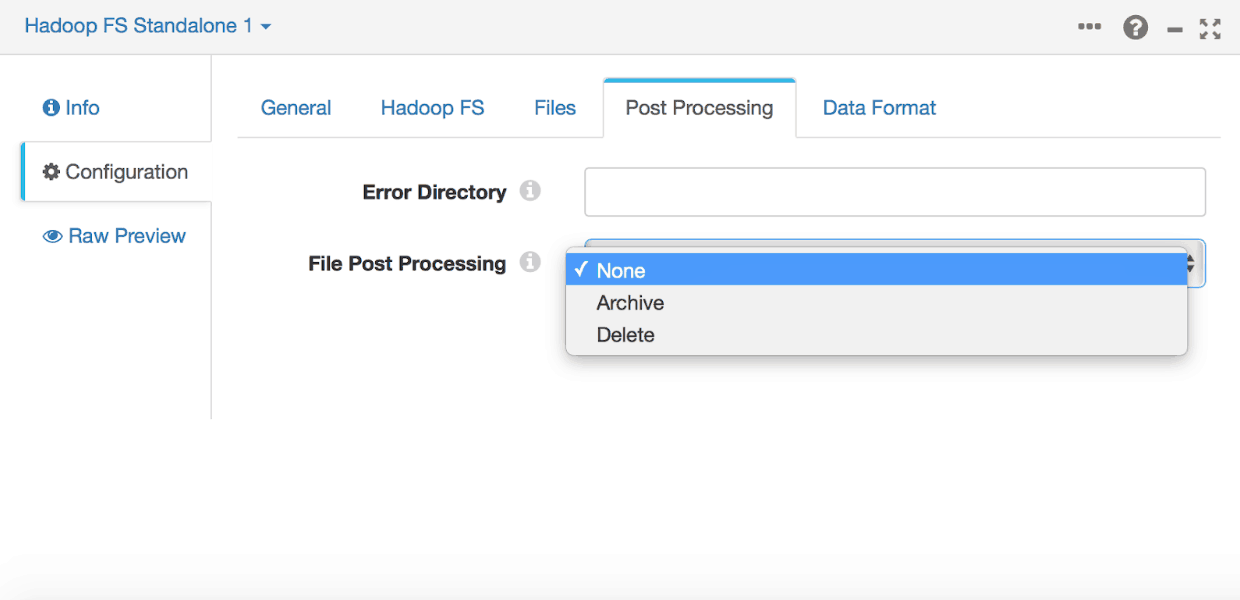
On the Files tab, enter the appropriate configuration. Let’s read using the last-modified timestamp so that we can synchronize the new incoming files under the configured folder.
Since we want to migrate data from HDFS into Amazon S3, we set File Post Processing to “None” for now.
The Hadoop FS Standalone origin supports the following data formats, in this example, we use Whole File data format. With the Whole File data format, you can transfer any type of file from the origin system to destination system.
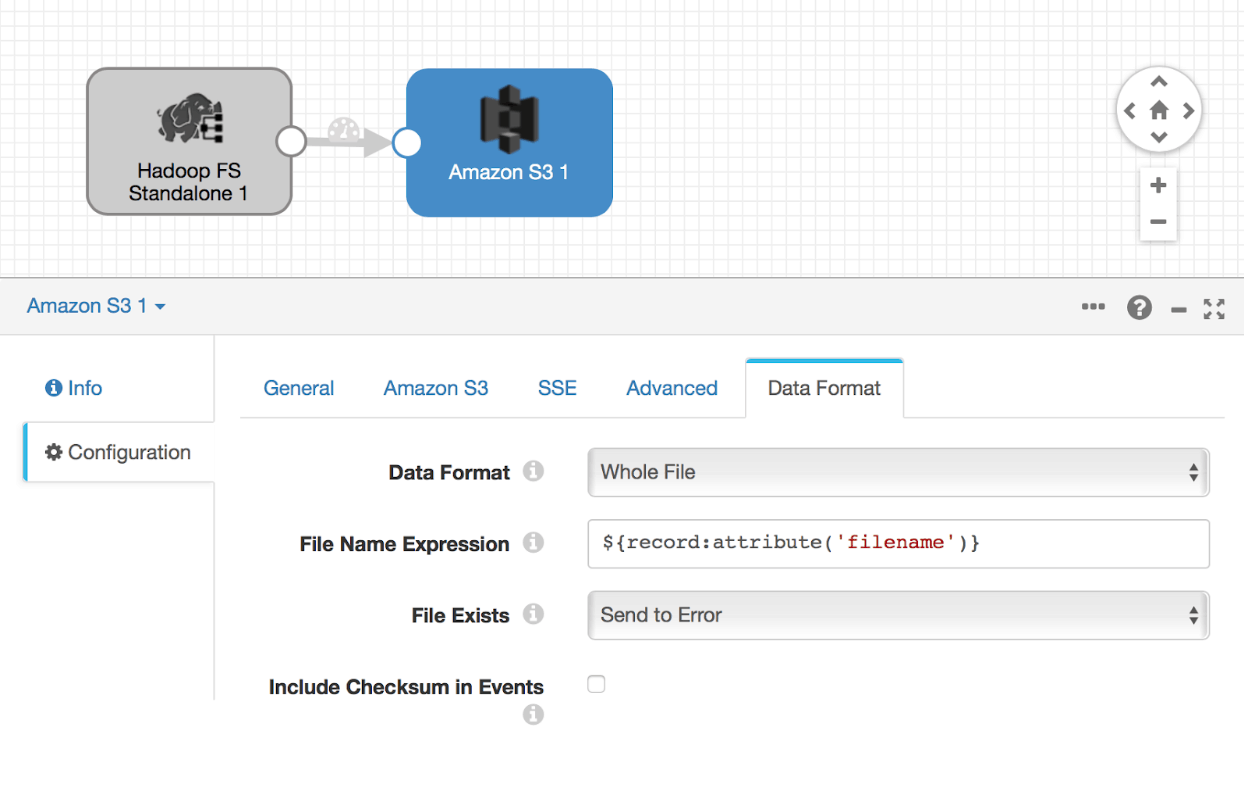
Amazon S3 Configuration
When we use whole file data format from the origin, we need to make sure the Amazon S3 destination also uses the whole file data format.
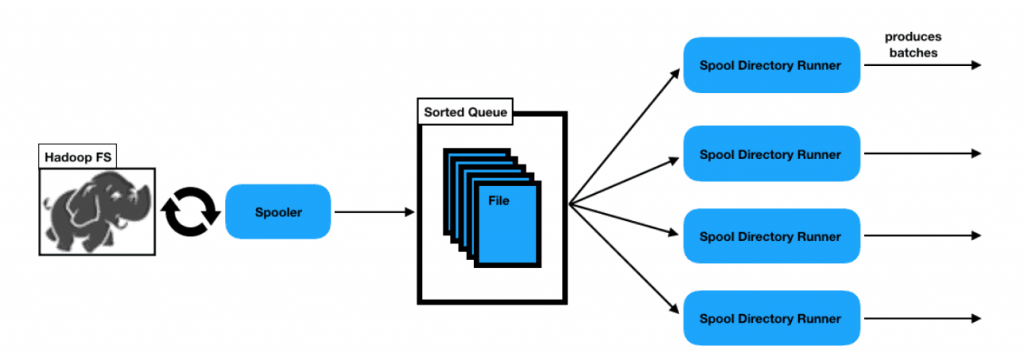
When you run the pipeline, the directory spooler thread runs in default every 5 seconds to spool the list of files from HDFS. This interval can be configured via the Spooling Period (secs) property. Once the list of spooled files is stored in the sort queue, each Hadoop FS Standalone runner thread pulls the file and passes it to the next stage, the Amazon S3 destination.
 Conclusion
Conclusion

The Hadoop FS Standalone origin can be deployed in many use cases to move between data stores. It is extremely handy because Data Collector does not need to be installed in the Hadoop ecosystem and it supports pretty much all data formats.
As always, if you have questions while you are configuring your StreamSets Data Collector pipelines, you can ask in the Community Slack.