This post describes how StreamSets Data Collector, a fast and flexible data ingestion engine, can be configured to take advantage of IAM Roles when running on AWS Elastic Kubernetes Service (EKS). IAM Roles allow data engineers to concentrate on business logic while AWS permissions are managed independently by AWS Administrators in accordance with AWS Best Practices for Security. If Data Collector is deployed directly on an EC2 instance, IAM Roles can simply be bound to the instance, but when running Data Collector on EKS, additional steps are needed.
The preferred way to make IAM Roles available to Data Collector running on EKS is to use IAM Roles for Service Accounts (IRSA). Alternate approaches include assigning IAM Roles directly to EKS nodes, which is undesirable as the IAM Roles would be available to all Pods running on the node, or using kube2iam which requires additional deployment and networking setup. This post covers IRSA.
Prerequisites
- An EKS Cluster
- AWS Permissions to create IAM Policies and Roles
- The aws cli and kubectl installed on your local machine
- A Control Hub Account (sign up for a free trial)
Overview
Here is a high-level overview of the steps for implementing IRSA for Data Collector Deployments on EKS (details of each step are provided below):
- Create an IAM Policy that specifies the AWS Permissions you wish to grant to Data Collector
- Create an OIDC Identity Provider for the EKS Cluster
- Create a namespace and Service Account for Data Collector Deployments
- Create an IAM Role that trusts the EKS Cluster’s OIDC Identity Provider and attach the IAM Policy to the Role
- Attach the IAM Role to the Data Collector’s Service Account
- Deploy Data Collector with the custom Service Account using Control Hub
With those steps in place, Data Collector pipelines will have the AWS Permissions granted by the IAM Role.
Step 1: Create an IAM Policy
I’ll create an IAM Policy named sdc-s3-ingest-policy that will allow Data Collector to List, Read and Write objects in an S3 bucket named sdc-ingest-bucket.
Here is the Policy definition:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::sdc-ingest-bucket/*",
"arn:aws:s3:::sdc-ingest-bucket"
]
}
]
}Step 2: Create an OIDC Identity Provider for your EKS Cluster
Follow these steps to create an OIDC identity provider for your EKS cluster.
Step 3: Create a Namespace and Service Account for Data Collector Deployments
Create a namespace and a custom Service Account to run Data Collector. I’ll create a namespace named ns1 and a Service Account with the name sdc (neither name is critical) using these commands:
$ kubectl create namespace ns1
$ kubectl create serviceaccount sdc -n ns1Step 4: Create an IAM Role
Create an IAM Role for the sdc Service Account that trusts the EKS Cluster’s OIDC Identity Provider and the sts.amazon.com audience as described here.
Here is an example of creating this IAM Role:
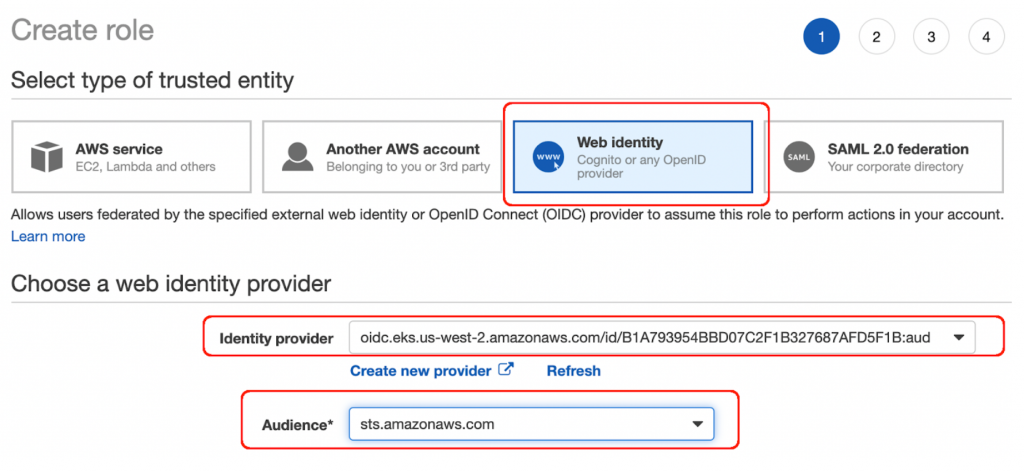
Attach the sdc-s3-ingest-policy Policy to the IAM role:
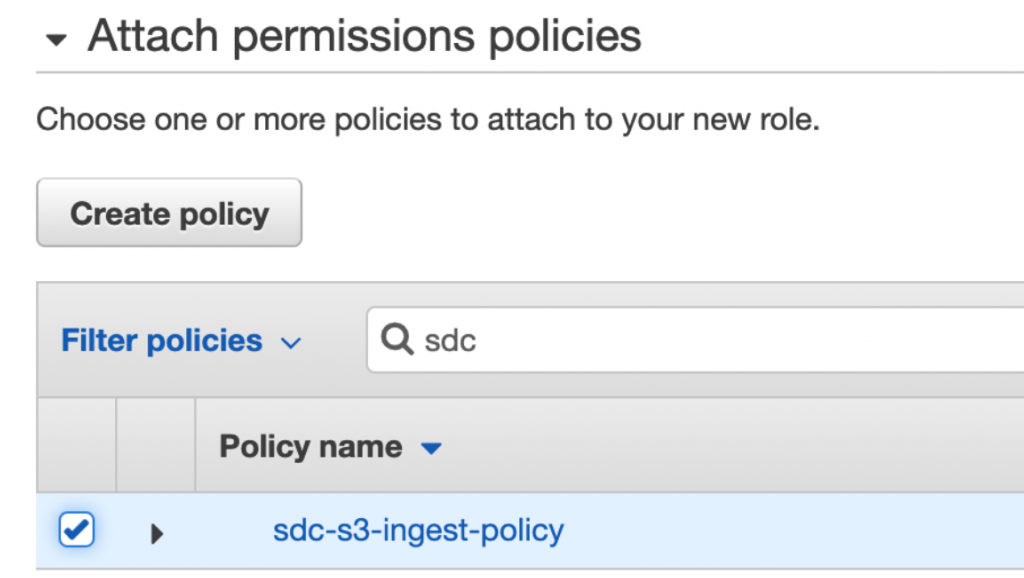
Save the Role with a name like sdc (the name is not critical). Then, after the Role has been created, edit the Role’s trust relationship as described in step 11 in the IAM Role section on this page, making these changes:
- Replace
:audwith:sub - Replace
sts.amazonaws.comwith your Service Account ID in the formsystem:serviceaccount:<NAMESPACE>:<SERVICEACCOUNT> - If necessary, update the
region-codeto match the EKS cluster’s region
My updated trust relationship looks like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::501672548510:oidc-provider/oidc.eks.us-west-2.amazonaws.com/id/50DCD1E10C8BAD2EC2B3E0E84647098C"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"oidc.eks.us-west-2.amazonaws.com/id/50DCD1E10C8BAD2EC2B3E0E84647098C:sub": "system:serviceaccount:ns1:sdc"
}
}
}
]
}
Save the Role.
Step 5: Attach the IAM Role to the Service Account
Attach the IAM Role to the sdc Service Account as described here, specifying your AWS Account ID and the IAM Role name, using a command like this:
$ kubectl annotate serviceaccount sdc eks.amazonaws.com/role-arn=arn:aws:iam::<AWS Account ID>:role/sdcStep 6: Create and Start a Data Collector Deployment
Use Control Hub to create a Deployment for a Data Collector instance with a manifest like the example shown below. The Deployment manifest should specify the following:
- The
sdcServiceAccount. - The property setting
fsGroup:65534in the Pod spec’s securityContext which will allow the ServiceAccount to read its AWS Web Identity Token. - A Data Collector image that contains the AWS stage library or a base Data Collector image with the AWS stage library loaded from a VolumeMount. See the blog post Best Practices for StreamSets Data Collector on Kubernetes for examples of loading stage libraries from Volumes.
The Control Hub Deployment should specify a DataCollector Label like eks-iam (the Label is not critical).
Here is an example manifest for use with a Data Collector image that includes the AWS stage library.
apiVersion: apps/v1
kind: Deployment
metadata:
name: sdc
spec:
selector:
matchLabels:
app: sdc
template:
metadata:
labels:
app: sdc
spec:
serviceAccountName: sdc
containers:
- name: sdc
image: <your sdc image>
securityContext:
fsGroup: 65534
Start the Deployment and the new Data Collector should register with Control Hub:
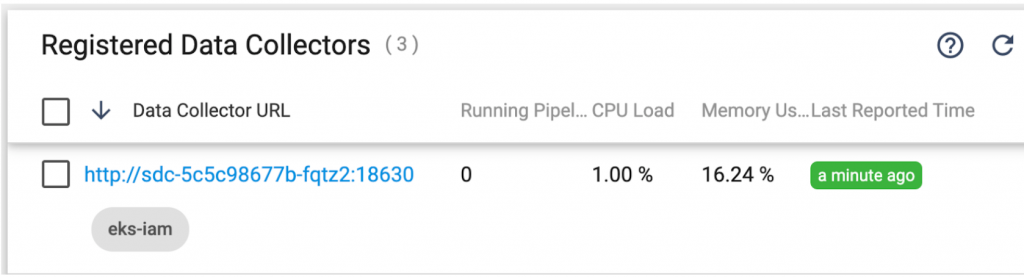
Confirm that Data Collector has the IAM Role
To confirm SDC has the AWS permissions granted by the IAM Role, create a Pipeline for the newly registered Data Collector that writes to the relevant S3 bucket. I’ll use a simple Pipeline like this:
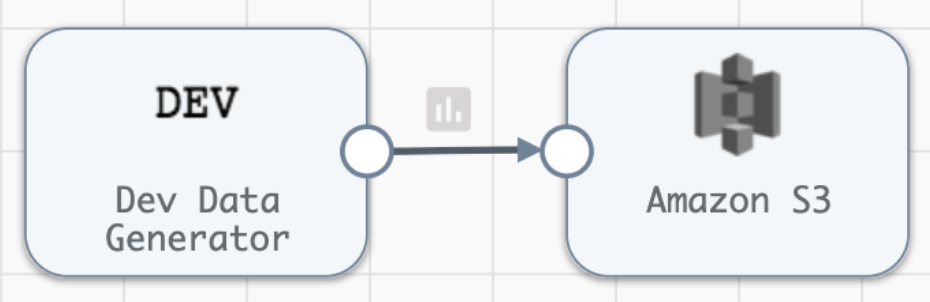
Configure the S3 Destination to use “Instance Profile” as its authentication method (which will access the IAM Role) and to write to a folder within the chosen bucket:
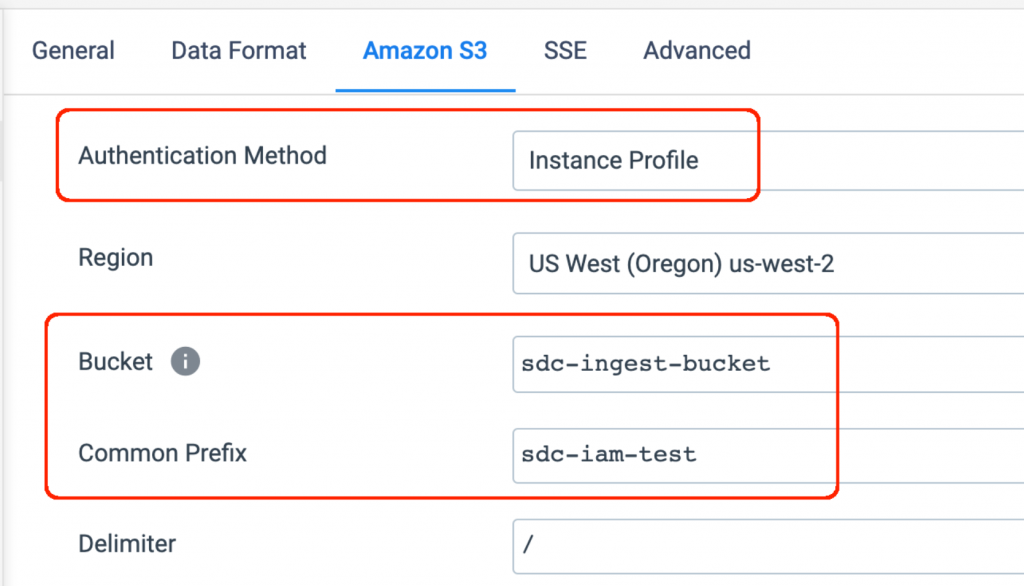
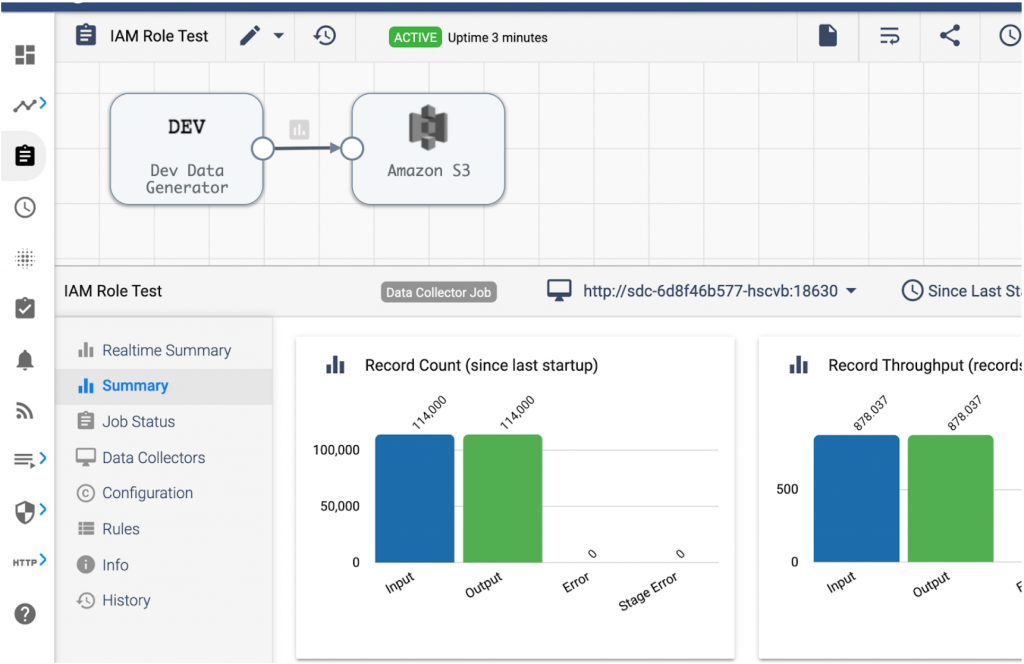
Create a Job for the Pipeline with the Data Collector Label eks-iam so it will run on the newly deployed Data Collector. Start the Job and view its metrics to confirm it is writing to S3:
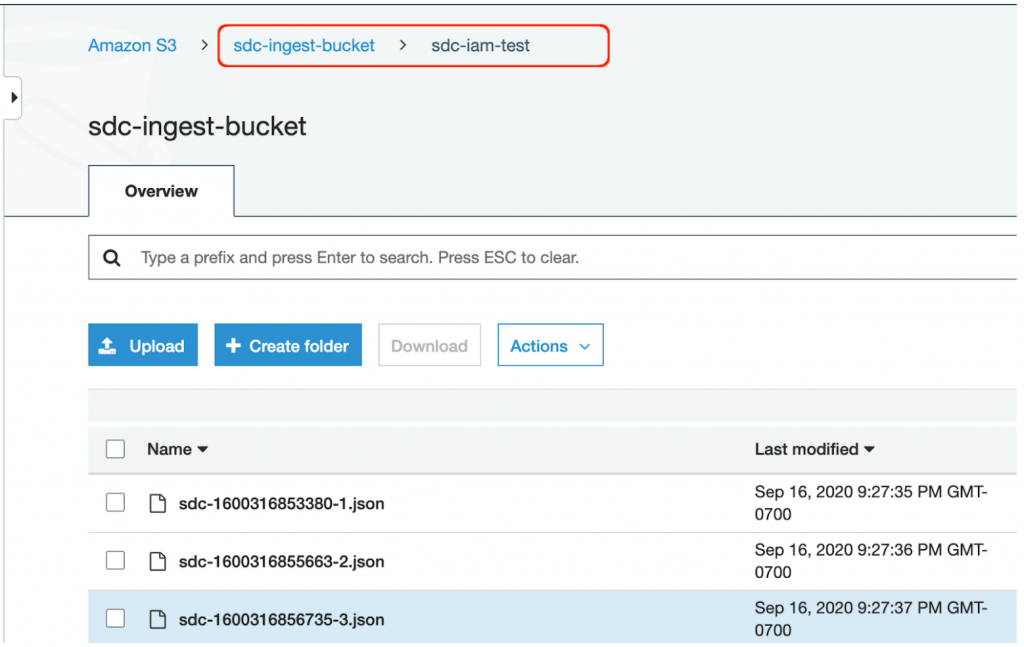
Confirm that data has been added to the S3 Bucket
We can see data has been written to our S3 bucket:
Conclusion
This post showed how to take advantage of IAM Roles when deploying Data Collector on AWS Elastic Kubernetes Service. With simple administrative configuration in both AWS and StreamSets, it is easy to manage fine-grained AWS permissions for Data Collector pipelines in accordance with AWS Best Practices for Security.
Try it out!
If you are running Data Collector on EKS, give this technique a try and let us know how it works for you!
You may also be interested in earlier posts about StreamSets and Kubernetes: