 When it comes to loading data into Apache Hadoop™, the de facto choice for bulk loads of data from leading relational databases is using Apache Sqoop Commands. After initially entering Apache Incubator status in 2011, it quickly saw wide spread adoption and development, eventually graduating to a Top-Level Project (TLP) in 2012.
When it comes to loading data into Apache Hadoop™, the de facto choice for bulk loads of data from leading relational databases is using Apache Sqoop Commands. After initially entering Apache Incubator status in 2011, it quickly saw wide spread adoption and development, eventually graduating to a Top-Level Project (TLP) in 2012.
In StreamSets Data Collector Engine we now have capabilities that enable SDC to behave in a manner almost identical to Sqoop commands. Now customers can use SDC as a way to modernize Sqoop-like workloads, performing the same load functions while getting the ease of use and flexibility benefits that SDC delivers.
Modernizing Your Sqoop Commands
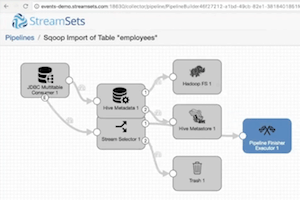
In addition to adding Sqoop-like capabilities, we’ve also added an importer tool that can automatically convert existing Sqoop commands to an equivalent pipeline within SDC. Check out this short video for a demonstration. The tool can be accessed by simply executing the Python command “pip3 install StreamSets”.
There are many ways in which SDC can be used as a way to modernize Sqoop, namely:
- Converting Sqoop commands into SDC is a great way to start. More frequently than not, customers have to perform entire data dumps each day or create custom scripting on top of Sqoop due to poor support for incremental imports and lack of data drift handling. By converting Sqoop commands to SDC pipelines, incremental imports are automated reducing the need for daily dumps and removing most if not all of the custom scripting that was previously needed to work around this problem.
- Sqoop’s ability to do incremental import is limited as it doesn’t have a proper method for persisting the “last offset”. While there is a “Sqoop metastore”, it is not supported in production by any Hadoop vendor due to various limitations (e.g. no backup, no security story, doesn’t work from Oozie which is most common scheduler for Sqoop).
- Sqoop is not data drift aware so StreamSets can help. Even though Sqoop can create an Apache Hive or Apace Impala (incubating) table for a user, it can’t “synchronize” the schema in the case where there was a data drift, whereas Drift Synchronization is a key feature of the Data Collector Engine. A typically deployed workaround is to drop the Hive table at the beginning of Sqoop import and re-create it from scratch which is clearly not ideal and adds to overall processing time.
- Since Sqoop has limited extensibility, most customers have to build various scripts around it for performing certain actions to be executed before or after their Sqoop commands. For most common use cases such as running JDBC or Hive queries, SDC includes standalone executors that can be plugged into start/stop event handling. Fore more advanced use cases, a Shell executor can move custom scripting to a single place (ie. an SDC pipeline).
The tool can be installed by simply executing the Python command “pip3 install StreamSets”. Then instead of running Sqoop directly:
$ sqoop import \ --username demo \ --password demo \ --connect jdbc:mysql://demo.streamsets.net/employees \ --table employees \ --hive-import
Use the streamsets-sqoop-import command:
$ streamsets-sqoop-import \ --username demo \ --password demo \ --connect jdbc:mysql://demo.streamsets.net/employees \ --table employees \ --hive-import
This command assumes that you’re running your Data Collector Engine locally on your machine and it will create and import the pipeline there. To import the pipeline to a Data Collector Engine running on a different machine, use the --sdc-url argument with the URL to the remote Data Collector Engine.
List of all Data Collector Engine specific arguments:
--sdc-urlURL to the Data Collector Engine where generated pipeline should be uploaded. Default value ishttp://localhost:18630/--sdc-stagelibName of stage library that should be used for all Hadoop stages. Primarily used to specify Hadoop distribution and version. Example value isstreamsets-datacollector-cdh_5_12-libfor CDH 5.12 orstreamsets-datacollector-mapr_5_2-libfor MapR 5.2.--sdc-usernameUsername for the Data Collector Engine. Default value isadmin.--sdc-passwordPassword for the Data Collector Engine. Default value isadmin.--sdc-hiveHiveServer2 URL to use when importing into Hive. Default value isjdbc:hive2://localhost:10000/default
Since Sqoop has been around for longer than StreamSets, in some cases Sqoop commands vary enough from SDC that we recommend you reach out and ask us for best practices, specifically:
- Most Sqoop connectors are JDBC based, as are the connectors in SDC. There are however few exceptions where Sqoop may have so called “direct” connectors. The most common ones include Oracle and Teradata and they are highly optimised. At this time SDC does not offer the same connectivity performance as Sqoop for this type of connectivity. In the situation where direct connectivity is important, using Sqoop is the preferred method.
In summary, for anyone loading data to Hadoop using StreamSets, you no longer need to use a separate tool for bulk data transfer if you don’t prefer to use Sqoop commands. Not only does StreamSets give you the same great functionality, but it also enables drift detection and integration with StreamSets Control Hub so it’s possible to run complex pipelines at scale with operational oversight and confidence.
Try StreamSets now. Visit Documentation for more details.