Many StreamSets Data Collector customers are now migrating their Hadoop ingestion pipelines to cloud platforms like AWS and they want to take full advantage of the AWS native services such as S3, EMR and Redshift. Landing in S3 is very straightforward. From there, customers often take data into EMR using Transformer for Spark for rich data processing and then directly output the data into Redshift or S3. But what about data loads directly from S3 into Redshift? Do I need to go through Transformer to load to Redshift? The answer is no, you can and should use the JDBC Producer stage in our Data Collector engine to write to Redshift. It’s simple and I’ll show you how it’s done.
There is also a powerful complementary capability we offer that many do not fully appreciate. Our Python SDK helps our enterprise users scale their operations by forming templates which can be used to automate configuration changes and instantly create several pipelines with just one script. What I’m about to walk you through was executed with ~80 lines of code. While this is a relatively small program, if you will only need to use this pipeline one time, then you’re probably better off building it directly inside our platform.
However, say you have several, maybe hundreds of jobs, and the pipelines are pretty similar save for a few minor configuration differences – in this case, the SDK is a great tool to utilize. It provides a big productivity boost for teams because they don’t have to manually duplicate pipelines and configure each one. It can be automated with code instead. You can also use our SDK to destroy and rebuild pipelines when you want to make alterations in the future.
In this blog, I will show you how to use our Python SDK to build an AWS S3 to Redshift Data Collector pipeline, all running on an m5.xlarge EC2 instance. However, you can run your Python on any supported Linux instance and it will work. The steps I will cover are:
- The prerequisites for using our Python SDK
- Creating an Environment, Deployment and Connection
- Building and configuring an S3 > Redshift pipeline
Prerequisites
To get started you will need a StreamSets account. If you’re new to our platform, you can schedule a demo & set-up session here.
You can find the prerequisites for the Python SDK here. Python 3.6 is the recommended version, however I used 3.7.12 which worked fine. Then install the latest version of the StreamSets SDK by running the following command in your Terminal:
$ pip3 install streamsets~=5.0
The next step is to create a token to connect the SDK to your account. This is done in your StreamSets account. From the left navigation panel, go to Manage > API Credentials.
Steps
- Click on the plus (or +) sign to create a new credential ID/token pair.
- Name it so it is easy for you to identify.
- Click on ‘Save & Generate’ and it will create a credential ID and token for you.
- IMPORTANT: Save these credentials somewhere because once you navigate away from this screen you will not be able to see them again. If you lose this one, you will need to delete and create new credentials.
Putting the Python SDK To Work
Part 1: Configuring Your Setup
In order to connect to the StreamSets Control Hub, at the beginning of your python script you will need to pass in the credentials you generated earlier, as shown at the beginning of the script in this sample template.
Create your environment. The SDK is designed to mirror the UI so any required fields should be included. In this example, I am using a self-managed environment. For a CSP environment (AWS, Azure or GCP), this part of your script will look slightly different. Any of these will work and each has its own configuration guidelines.
Next you will create a self-managed deployment. We will be using a Data Collector engine for this example, notated by ‘DC’, in the github template. You’ll notice that this is structured similarly to the first part of the script where you are creating an environment, however, the important thing to note here is the order in which you carry out the steps. See below for reference.
Steps To Configure Your Deployment
- Call the deployment builder
- Configure the build parameters for the deployment
- Choose your deployment install type – Docker (recommended for Windows users) or Linux (Tarball installation method) – you can check prerequisites for each one here
- Add the deployment
- Start the deployment
- Optionally configure stage libraries for your deployment (line 49 in the script) – for this example you will need the ‘aws’ and ‘jdbc’ libraries in addition to the default libraries. If you skip this step, it will automatically configure the 3 default libraries (basic, dev, dataformats)
- Optionally add any necessary driver; certain stages require a driver, but not all. For this example you are uploading the Amazon Redshift JDBC driver (it is already included in line 51 in the script) Alternatively, you can click on the engine within the UI and manually upload it under External Resources > External Libraries.
- Update the deployment
The steps must be carried out in this order, or you will not configure the deployment correctly.
Now that you have a deployment object, in order to launch your engine you need to retrieve and run the deployment install script (shown in lines 57-61 in the github repo). This next part may take a few minutes, but once complete you will see the engine in your account under Set Up > Engines. *Note: If this is your first Linux/Tarball installation, you will need to increase the ulimit.
The last step of setup is creating your S3 connection. First, you need to identify the engine object which you launched in the previous step. The title of the connection can be anything that makes it easy for you to identify. Then go into your AWS account and create an Access Key which you will use as shown below.
connection_builder = sch.get_connection_builder() connection = connection_builder.build(title='s3-connection', connection_type='STREAMSETS_AWS_S3', authoring_data_collector=sdc, tags=None) connection.connection_definition.configuration['awsConfig.awsAccessKeyId'] = <your-access-key> connection.connection_definition.configuration['awsConfig.awsSecretAccessKey'] = <your-secret-access-key> sch.add_connection(connection)
To check if your script worked, when you run it you should see the connection appear under Set Up > Connections. Once that is complete, you have successfully completed your setup!
Part 2: Building the Pipeline
This next section is currently not outlined as explicitly in the documentation but once again, follows the UI’s design pretty closely.
pipeline_builder = sch.get_pipeline_builder(engine_type='data_collector', engine_id=sdc.id) origin = pipeline_builder.add_stage('Amazon S3', type='origin') origin.use_connection(connection) origin.set_attributes(bucket=<your-s3-bucket-name>, prefix_pattern='*.csv', data_format='DELIMITED', header_line='WITH_HEADER', stage_on_record_error='TO_ERROR') destination = pipeline_builder.add_stage('JDBC Producer') destination.set_attributes(default_operation='INSERT', table_name=<your-table-name>, schema_name='public', field_to_column_mapping=None, jdbc_connection_string=<your-jdbc-connection-string>, username=<your-username>, password=<your-password>) no_more_data_finisher = pipeline_builder.add_stage('Pipeline Finisher Executor')
The attributes I have included above are specific to the Amazon S3 origin and JDBC Producer destination. The fields in your script should match the required fields within whichever stages you are using and I have also included the JDBC connection string for this example which you can find in your Redshift account. You can optionally also include a Pipeline Finisher Executor, which automatically stops your job once all the data has passed through. *Note: You will only be able to view the pipeline within your account after you publish it, as shown in the code snippet below.
origin >> destination origin >= no_more_data_finisher pipeline = pipeline_builder.build('SDK pipeline') sch.publish_pipeline(pipeline, commit_message='First commit of my sdk pipeline')
When I check within my account, I can see the new pipeline with the configured stages, shown below.
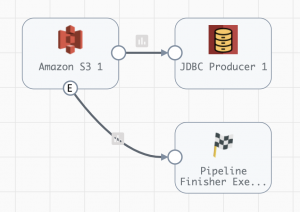
The last step is to create a job to execute your pipeline. Be sure to include your data collector labels (line 107 in the script)!
job_builder = sch.get_job_builder() pipeline = sch.pipelines.get(name='SDK pipeline') job = job_builder.build('SDK job', pipeline=pipeline) job.data_collector_labels = ['Self-Managed-Deployment-PythonSDK'] sch.add_job(job) sch.start_job(job)
Once the job is completed, if you check in Redshift, you should see the data that was moved from your S3 bucket. This was a fairly basic pipeline, simply taking the data from an S3 bucket and inserting it into a Redshift database. With StreamSets, you can also use any of our numerous processors to manipulate the data before it reaches its destination.
There are many more things you can do with our Python SDK, so start exploring now! If you have any questions as you are going through it, our Community is a great resource and you can always reach out through the chat box within our platform or by booking an expert call.
Click here for access to the entire template in github.
