 Graph databases represent and store data in terms of nodes, edges and properties, allowing quick, easy retrieval of complex hierarchical structures that may be difficult to model in traditional relational databases. Neo4j is an open source graph database widely deployed in the community; in this blog entry I’ll show you how to use StreamSets Data Collector to read case data from Salesforce and load it into the graph database using Neo4j’s JDBC driver.
Graph databases represent and store data in terms of nodes, edges and properties, allowing quick, easy retrieval of complex hierarchical structures that may be difficult to model in traditional relational databases. Neo4j is an open source graph database widely deployed in the community; in this blog entry I’ll show you how to use StreamSets Data Collector to read case data from Salesforce and load it into the graph database using Neo4j’s JDBC driver.
Salesforce Cases
Salesforce Service Cloud delivers customer support as a service. The core concept is the case – analogous to a ticket in other systems. A case can be associated with an account, a contact at that account and several other standard and custom Salesforce objects. Constant analysis of service cloud data is key to providing great customer service, and by combining Service Cloud data with other data, such as opportunities in the Sales Cloud, we can help support the sales team by, for example, identifying service tickets filed by customers with repeat business. Let’s see how we can extract all the information we need from Salesforce and write it to Neo4j using Data Collector.
Reading Cases from Salesforce
The Salesforce Origin, shipped with SDC since version 2.2.0.0, allows you to read data via SOQL queries and the Salesforce SOAP or Bulk API. We can use relationship queries to retrieve cases and their associated accounts and contacts in a single SOQL query:
SELECT Id, Account.Id, Account.Name, CaseNumber,
Contact.Id, Contact.Name, Contact.Account.Id,
Contact.Account.Name, Status, Product__c,
Subject, Priority, Description, IsClosed,
OwnerId
FROM Case
WHERE Id > '${OFFSET}'
ORDER BY Id
In this single query we retrieve all the cases with ID greater than a given offset, their associated accounts’ IDs and names, their contacts’ IDs and names, and their contacts’ account details (just in case they are different from the case’s associated account). We also retrieve the associated product code, a custom field present in Salesforce Developer Edition.
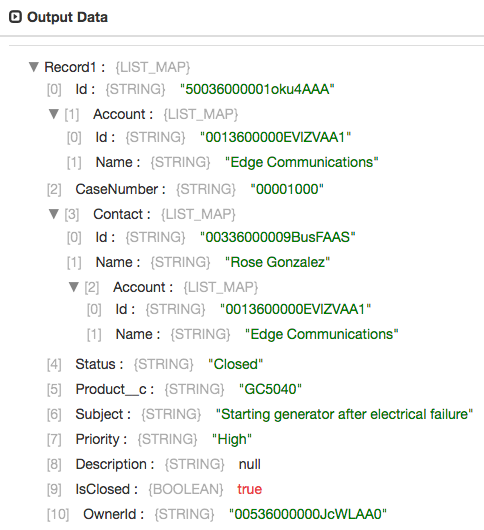
The Salesforce origin executes the relationship query and produces records with a hierarchy of fields:
Writing Data to Neo4j
Since we don’t need to transform the data en route from Salesforce to Neo4j, we can build a very simple pipeline:
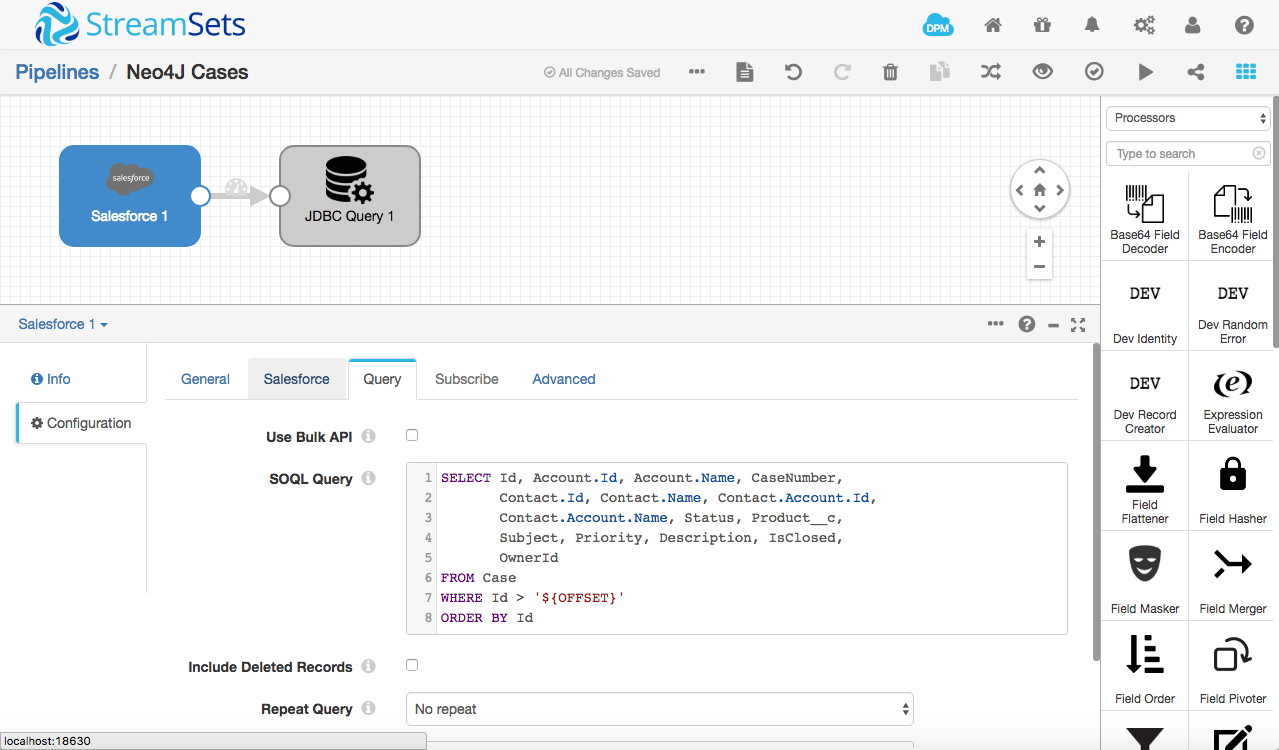
As Neo4j is very different from a relational database it does not use SQL. Instead, we interact with the graph database via Cypher. In particular, we can ‘upsert’ data using a Cypher MERGE clause.
At present, the JDBC Producer Destination does not allow us to write arbitrary statements – it’s hardcoded to use SQL’s INSERT. The JDBC Query Executor is more flexible, so we’ll use it here. Note, however, that the executors aren’t really designed to work in the data path – they aren’t optimized for high volumes of data, so performance might not be what you’ve come to expect from SDC. We’re a little bit out on the ‘bleeding edge’ here :-)
We can configure the executor with jdbc:neo4j:bolt://localhost as the JDBC URL to access Neo4j on localhost and drop a query straight into the JDBC Executor’s configuration using SDC’s Expression Language to populate the statement. Here’s a very simple example that just creates a case node, if there is not already a matching node in the database:
MERGE (case:Case {
CaseId: "${record:value('/Id')}",
CaseNumber: "${record:value('/CaseNumber')}",
Status: "${record:value('/Status')}",
Subject: "${record:value('/Subject')}",
Priority: "${record:value('/Priority')}",
Description: "${record:value('/Description')}",
IsClosed: ${record:value('/IsClosed')}
})
Although running this statement multiple times with the same data will only result in a single node in the database, it will still create duplicate nodes if any of the attributes change between MERGE calls, so it’s better to merge on the unique record ID, and SET the remaining attributes:
MERGE (case:Case { CaseId: "${record:value('/Id')}" })
ON CREATE SET case.CaseNumber = "${record:value('/CaseNumber')}",
case.Status = "${record:value('/Status')}",
case.Subject = "${record:value('/Subject')}",
case.Priority = "${record:value('/Priority')}",
case.Description = "${record:value('/Description')}",
case.IsClosed = ${record:value('/IsClosed')}
We can do much more than this, however! Since we have the related account and contact data, we can use multiple MERGE clauses in a single statement to handle the case, account, contact AND the relationships between them:
// 'Create' should be read as "Create, if it does not already exist"
// in each case!
MERGE (case:Case { CaseId: "${record:value('/Id')}" })
ON CREATE SET case.CaseNumber = "${record:value('/CaseNumber')}",
case.Status = "${record:value('/Status')}",
case.Subject = "${record:value('/Subject')}",
case.Priority = "${record:value('/Priority')}",
case.Description = "${record:value('/Description')}",
case.IsClosed = ${record:value('/IsClosed')}
// Create the corresponding account
MERGE (account1:Account { AccountId:"${record:value('/Account/Id')}" })
ON CREATE SET account1.Name = "${record:value('/Account/Name')}"
// Create the corresponding contact
MERGE (contact:Contact { ContactId:"${record:value('/Contact/Id')}" })
ON CREATE SET contact.Name = "${record:value('/Contact/Name')}"
// Create the contact's account
MERGE (account2:Account { AccountId:"${record:value('/Contact/Account/Id')}" })
ON CREATE SET account2.Name = "${record:value('/Contact/Account/Name')}"
// Create the corresponding product
MERGE (product:Product { Code:"${record:value('/Product__c')}" })
// Create a relationship between the case and its account
MERGE (case)-[:associatedWith]->(account1)
// Create a relationship between the case and its contact
MERGE (case)-[:associatedWith]->(contact)
// Create a relationship between the contact and its account
MERGE (account2)-[:isParent]->(contact)
// Create a relationship between the case and its product
MERGE (case)-[:concerns]->(product)
Now it should be apparent why we use MERGE rather than CREATE, even on a single run through the data: although we encounter each case only once when processing query results, we may encounter the associated objects any number of times. We wouldn’t want to create a whole bunch of duplicate nodes!
One optional optimization we can make, before running the pipeline, is to tell Neo4j that the Id fields on the Salesforce objects (and the product’s code attribute) are unique keys. This tells Neo4j to create the relevant indexes and improves performance:
CREATE CONSTRAINT ON (c:Case) ASSERT c.CaseId IS UNIQUE; CREATE CONSTRAINT ON (a:Account) ASSERT a.AccountId IS UNIQUE; CREATE CONSTRAINT ON (p:Product) ASSERT p.Code IS UNIQUE; CREATE CONSTRAINT ON (c:Contact) ASSERT c.ContactId IS UNIQUE;
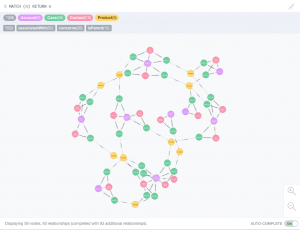
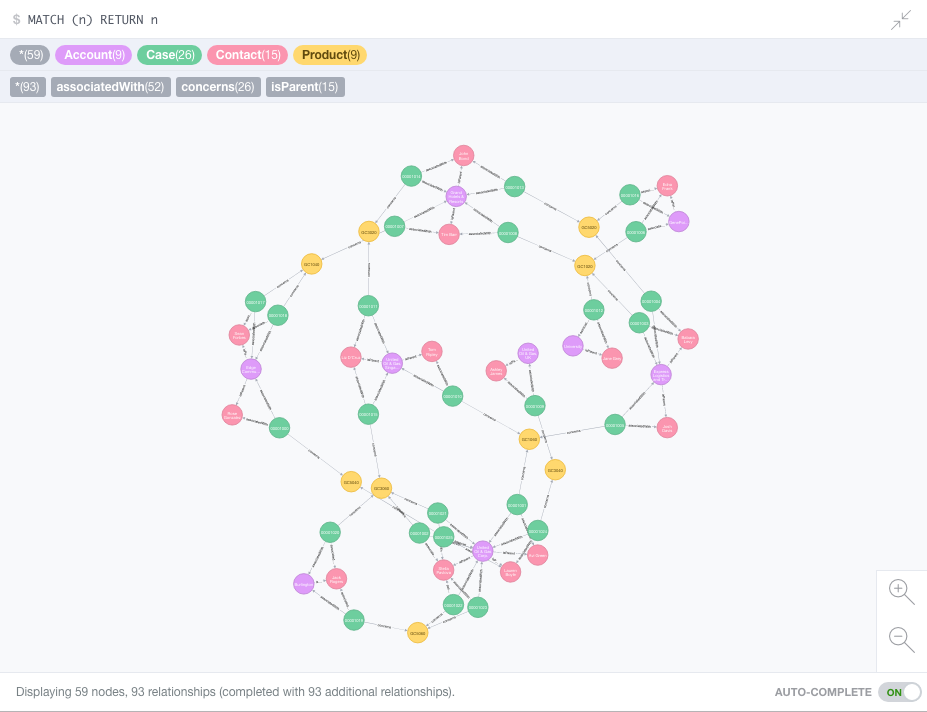
Running the pipeline against a Salesforce Developer Edition with its standard sample data takes just a few seconds and results in the following visualization in Neo4j’s Browser interface:
Note – at present, you must enable auto-commit in the JDBC Executor configuration since it does not commit after processing the batch. SDC-6042 (next on my todo list) will fix this fixes this in 2.6.0.0!
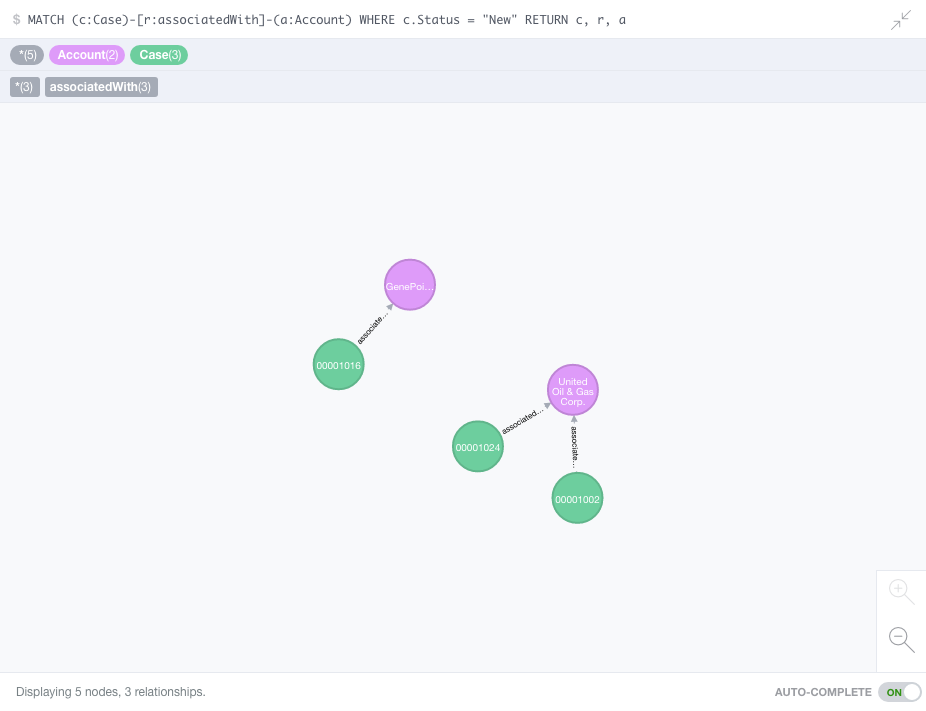
Not only can we interact with the visualization, examining nodes, and following relationships, we can also use Cypher queries to analyze the data. For example, let’s look at all of the accounts that have ‘new’ cases:
MATCH (c:Case)-[r:associatedWith]-(a:Account) WHERE c.Status = "New" RETURN c, r, a
We can also construct Cypher queries with tabular output. For example, account names and the number of closed cases for each:
MATCH (c:Case)-[r:associatedWith]-(a:Account) WHERE c.IsClosed RETURN a.Name as accountName, COUNT(a) as numberOfCases ORDER BY numberOfCases DESC

We could go on to explore the data in may different ways, for example, ‘Who are the contacts with cases open on a given product?’, but let’s look at how we can get opportunity data into Neo4j, bridging the Service Cloud and Sales Cloud.
Reading Opportunities from Salesforce
We can duplicate the Case pipeline and then edit it to suit opportunities. The SOQL query is:
SELECT Id, Account.Id, Account.Name, Amount, ExpectedRevenue,
IsClosed, Name, StageName
FROM Opportunity
WHERE Id > '${OFFSET}'
ORDER BY Id
Note – we retrieve the account id and name so we can link the opportunities to the existing account nodes in the graph.
The Cypher statement follows the same pattern as that for cases:
MERGE (oppty:Opportunity { OpportunityId: "${record:value('/Id')}" })
ON CREATE SET oppty.Amount = ${record:value('/Amount')},
oppty.ExpectedRevenue = ${record:value('/ExpectedRevenue')},
oppty.IsClosed = ${record:value('/IsClosed')},
oppty.Name = "${record:value('/Name')}",
oppty.StageName = "${record:value('/StageName')}"
MERGE (account:Account { AccountId:"${record:value('/Account/Id')}" })
ON CREATE SET account.Name = "${record:value('/Account/Name')}"
MERGE (oppty)-[:associatedWith]->(account)
Running the pipeline adds opportunities to the graph, as well as a couple of new accounts – these are prospects or customers with no associated cases:

Now we can reach for the brass ring – show the accounts with open cases, ordered by expected opportunity revenue:
MATCH (c:Case)-[r1:associatedWith]->(a:Account)<-[r2:associatedWith]-(o:Opportunity) WHERE c.Status <> "Closed" WITH a, SUM(o.ExpectedRevenue) AS totalExpectedRevenue ORDER BY totalExpectedRevenue DESC RETURN a.Name, totalExpectedRevenue

Wow – $5.5M is on the line from United Oil & Gas Corp – seems like we’d better prioritize their cases!
This blog post barely scratches the surface of Neo4j. I encourage you to download the free community edition and take it for a spin!
Conclusion
The Salesforce Origin allows you to easily retrieve data from Salesforce, modeling related objects as a hierarchy of fields. The JDBC Executor supports arbitrary queries against any JDBC-enabled data store, even those that don’t speak SQL, but bear in mind that it isn’t optimized for large data sets. If you’re a Neo4j user, try StreamSets today – it can read from a wide variety of data sources. Give Data Collector a try when you need to load data into the graph database, and let us know how you get on in the comments!