
Upload Data to Snowflake with Pre-defined Processors for Free
Moving data from storage or directories to Snowflake or any other destination? Standardize, normalize, and load file data automatically with over 60 pre-built processors.
Copy Pristine Datasets into Snowflake on Autopilot
Receiving files with little to no standardization and consistency in structure? It’s a common frustration for data engineers. When new files land in places such as AWS S3 or your local directory behind your firewall, let StreamSets go to work, automatically reading the files and applying the processors to the data to ensure it’s complete, consistent and valid. Best of all, get automatically notified of processing errors when something falls beyond the boundaries you’ve set.
Field Remover to Eliminate Unnecessary Data
Got a file from your sales team in Germany with junky personal notes included? Or maybe a file with duplicate data? Remove a local teams’ “notes” field along with any other fields that are not needed for down-stream analytics. With Field Remover, easily select and keep the fields you want and discard those you don’t before copying into Snowflake.
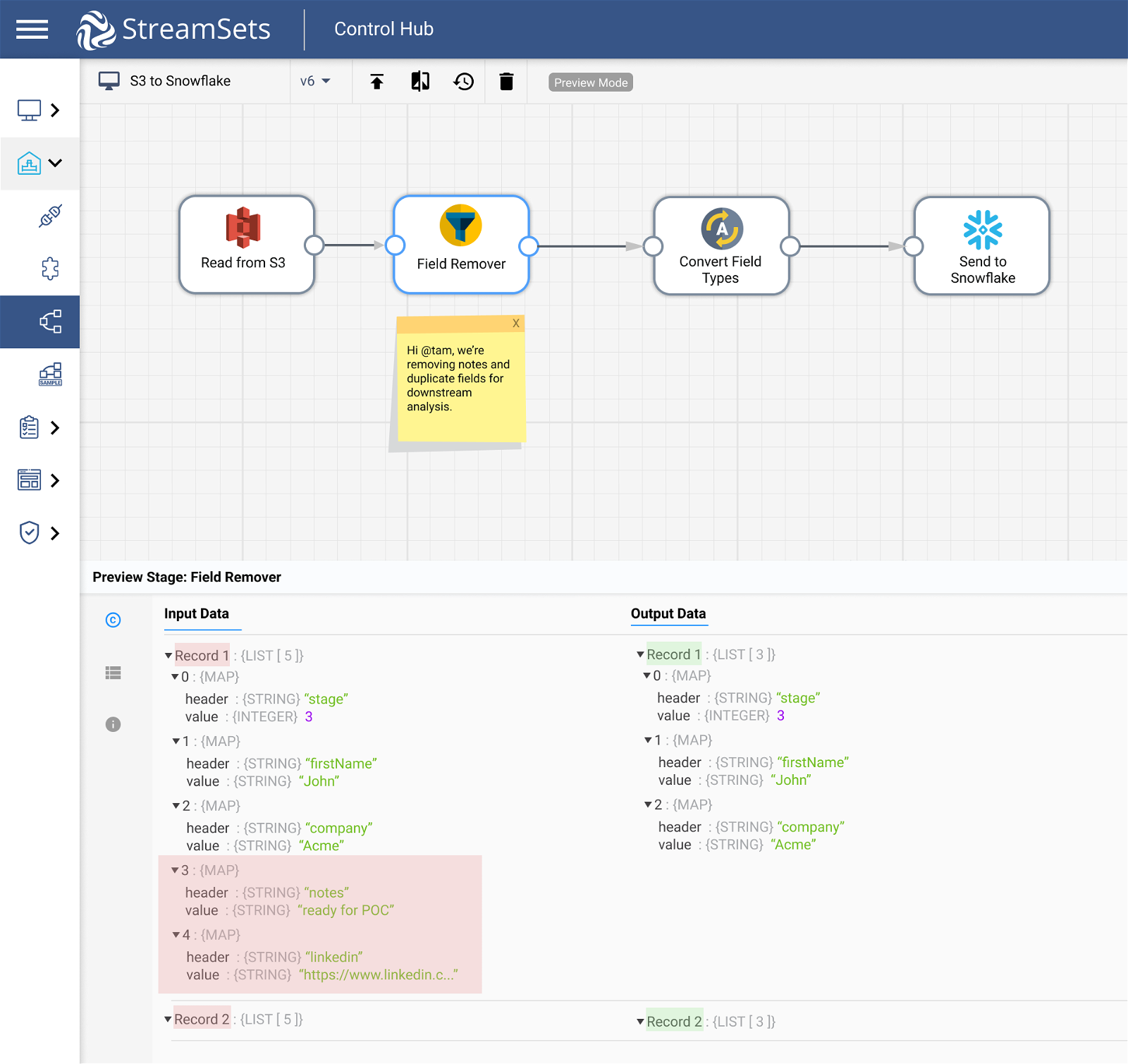
Expression Evaluator to Normalize Fields or Perform Calculations
Our uniquely flexible expression evaluator can perform calculations and write the results to new or existing fields, add or modify record header attributes and field attributes, and more. Easily drop in custom Jython, Java or Groovy libraries to apply virtually any processing logic to your data.
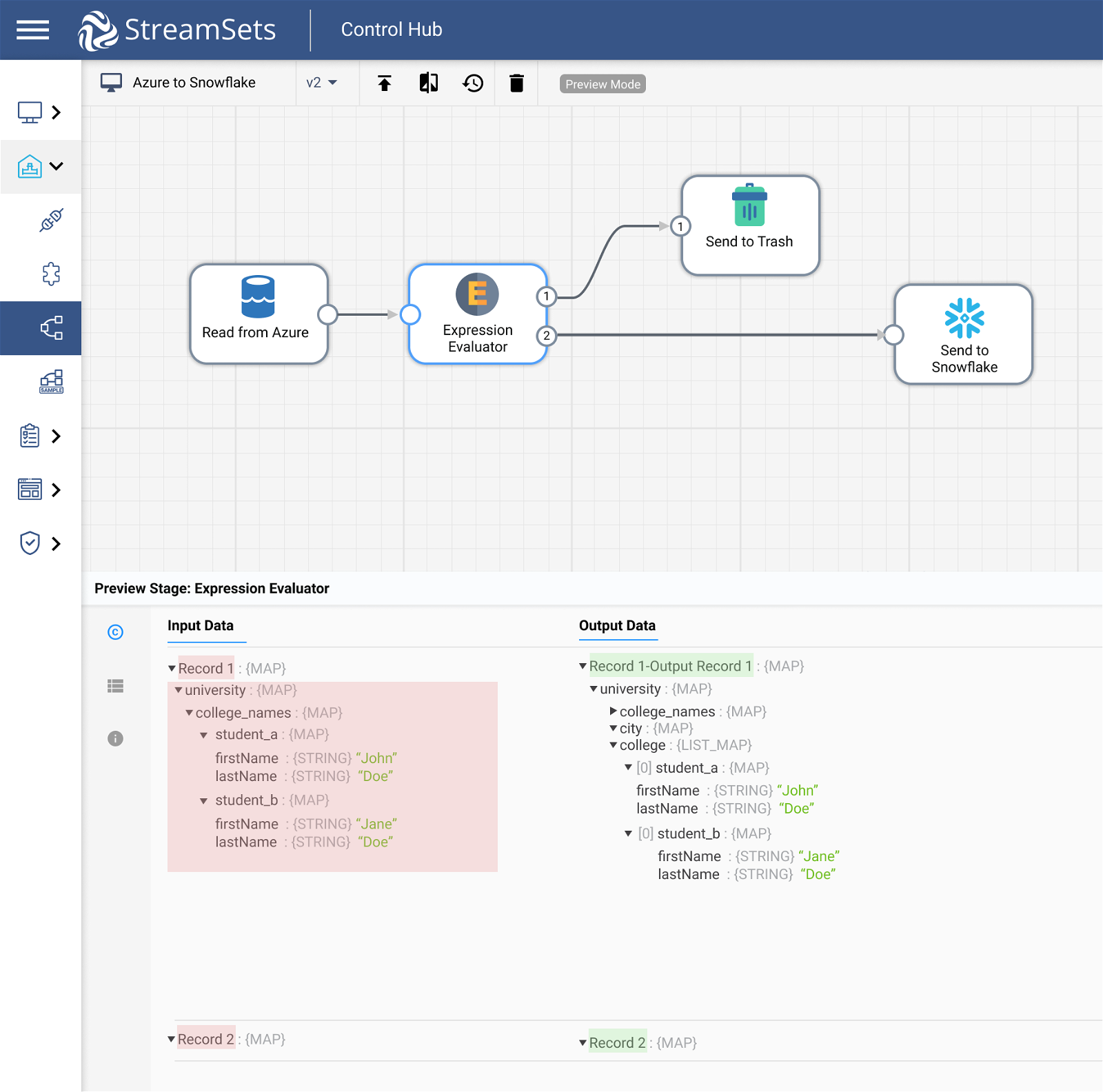
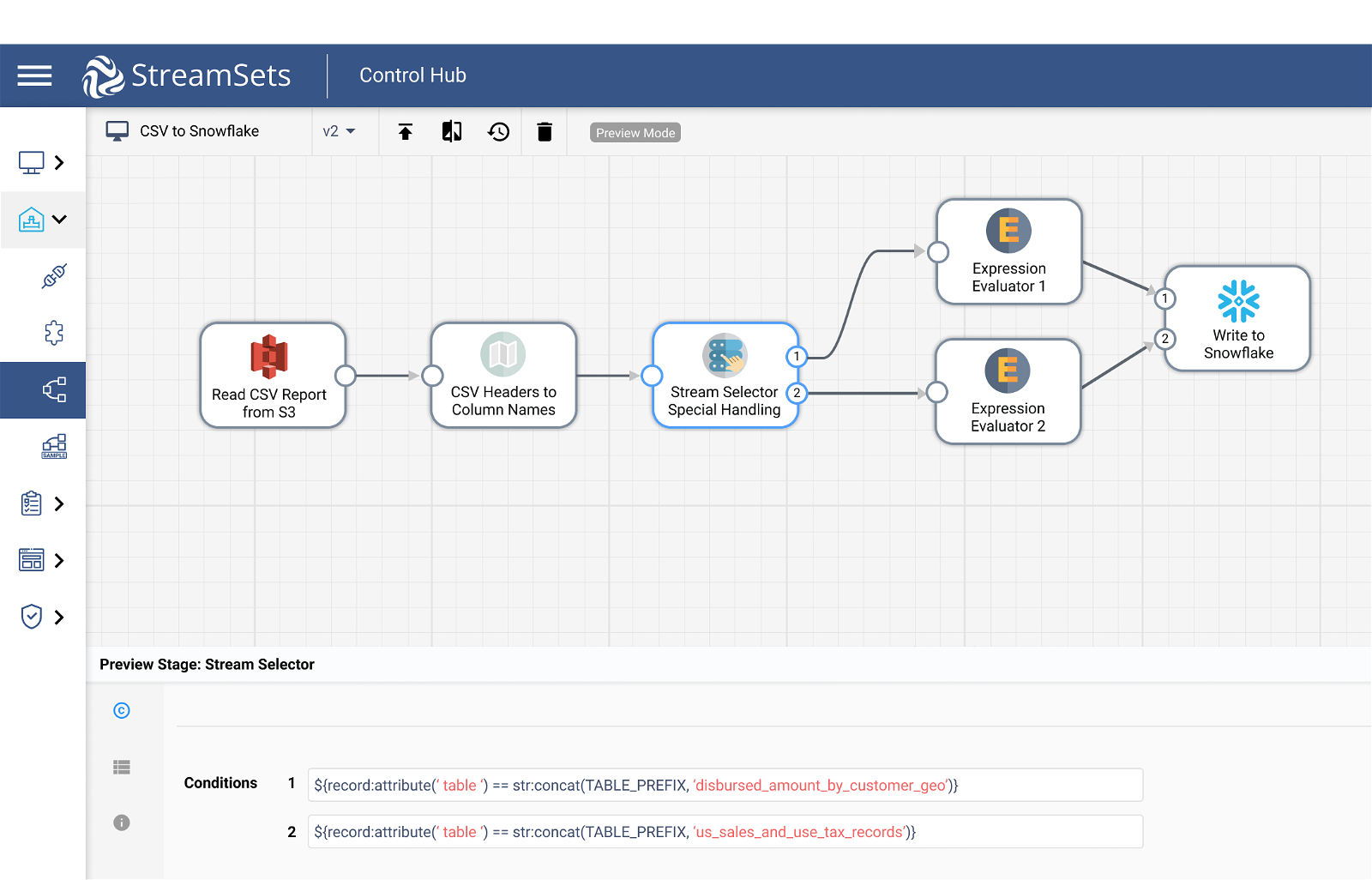
Stream Selector for Conditional Routing
Pulling in CSV data from several different customer reports in a single data pipeline? It’s unlikely you’ll need to process these files in the same way before uploading the data to Snowflake. Select and route records through your pipeline based on pre-set conditions with our stream selector.
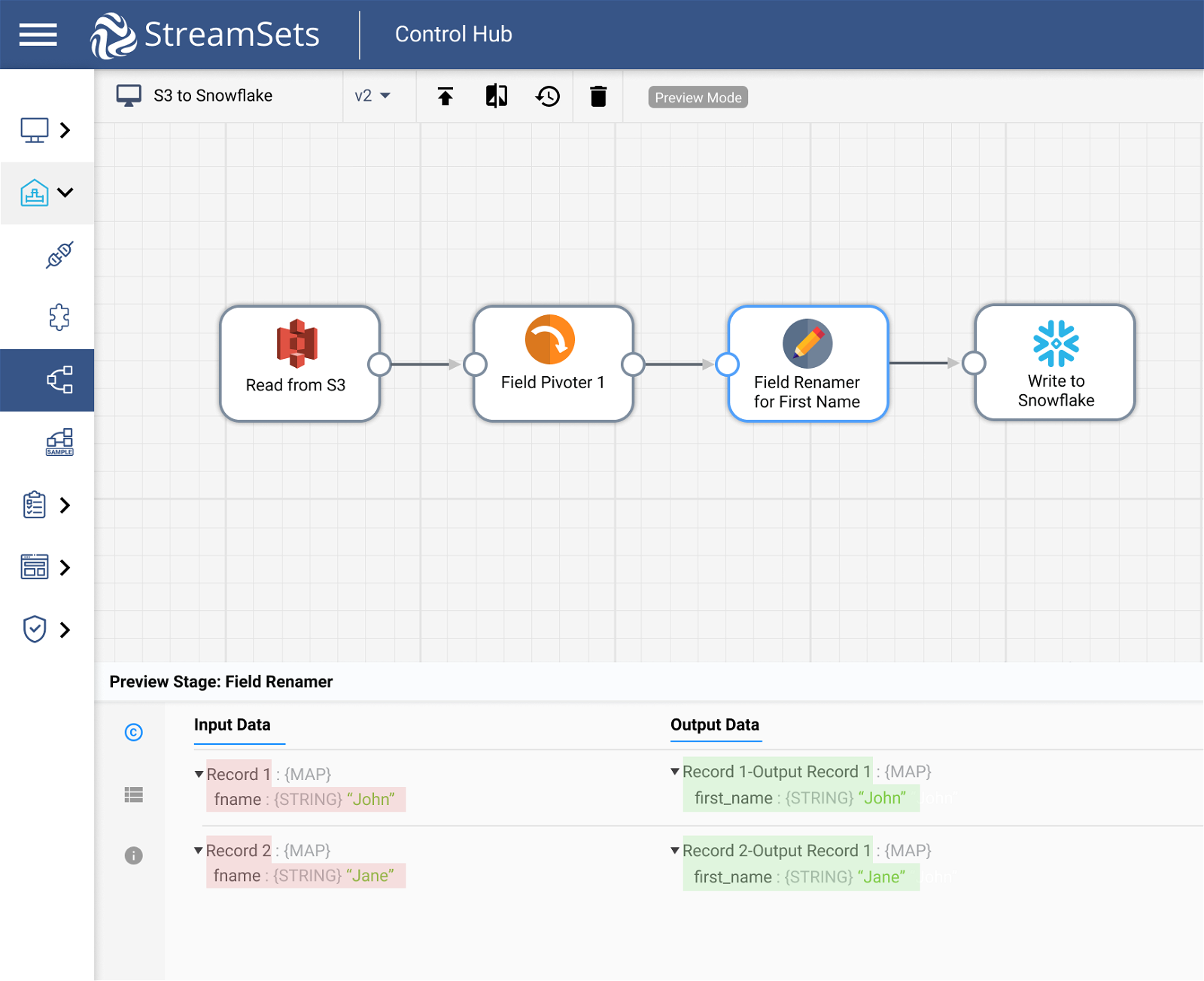
Field Renamer to Rename Record Fields
Matching source and destination fields is a constant battle. Now, you could explicitly specify each field, but that’s a bit laborious, not to mention brittle in the face of data drift. Handle new fields appearing in the input data automatically. With Field Renamer, configure behavior when a source field does not exist, when a target field with a matching name already exists, when a source field matches multiple source field expressions, and more.
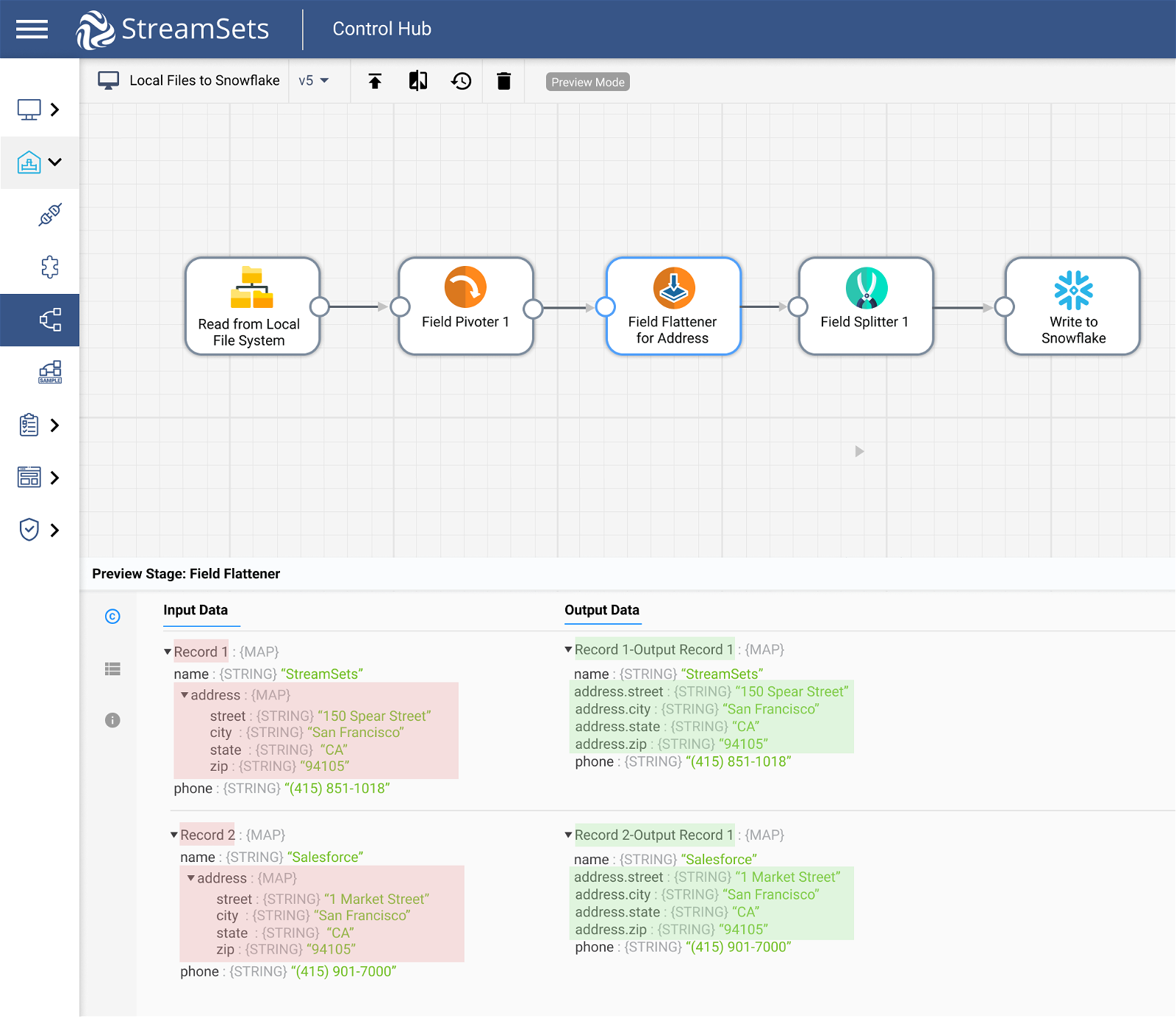
Field Flattener to Ensure Files Meet Conditions Before Loading
Data formats such as Avro and JSON sometimes represent hierarchical structures, where records contain fields that are themselves a collection of fields, such as an address field. Many destinations such as Snowflake or your Delta Lake, however, require a ‘flat’ record, where each field is a single string, integer, etc. Use Field Flattener to flatten the structure of your entire record or just a specific field automatically before uploading data to Snowflake.
Our customers run millions of data pipelines using StreamSets

StreamSets Does More Than Simplify Data Processing
Easy to Start, Easy
to Run, Easy to Expand
Handle Data
Drift Automatically
Deploy Securely
in Any Environment
What Our Customers Say
