Cloud Data Warehouse Integration
Resilient data warehouse solutions for data integration, migration and management.
You Need Data Everywhere, Not in Silos
The promise of cloud data warehouses is tantalizing–boundless capacity, high performance processing, and seamless scaling without the management hassle. You can make continuous data available on-demand to analysts and data scientists for innovation and exploration with cloud data warehouse integration.
Should you replicate your data infrastructure to the cloud and “go”? Not so fast, a legacy data architecture in a cloud data warehouse is still a legacy architecture: all of the complexity and none of the power. It’s not designed for cloud-native architectures and modern execution environments.
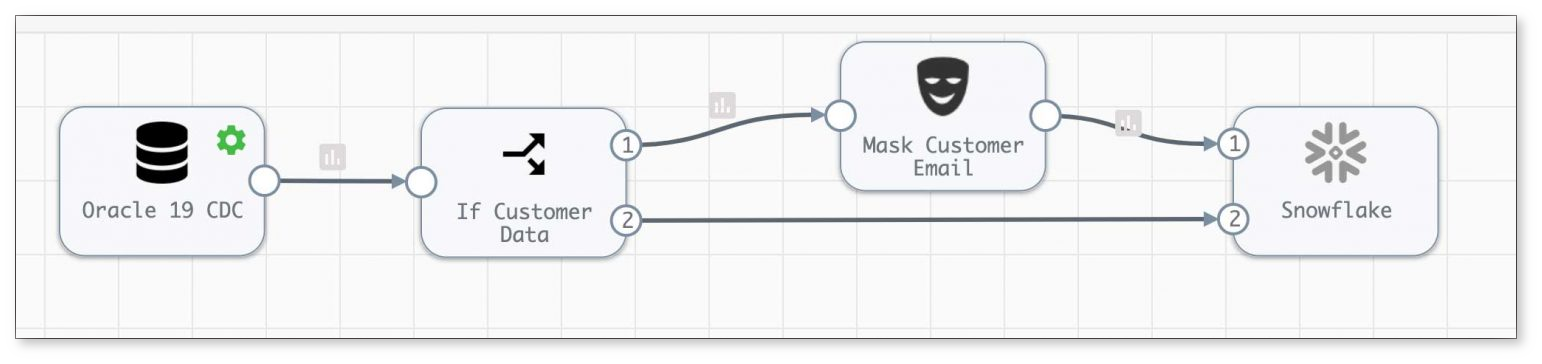

The StreamSets Data Integration Advantage
StreamSets data engineering platform helps you accelerate your data ingestion, and keep data sources and legacy systems in sync with your cloud data warehouse. Learn more about data integration from a data engineering point of view.
Flexible Hybrid and Multi-cloud Architecture
Easily migrate your work to the best data platform or cloud infrastructure for your needs.





What Is a Data Warehouse?
A data warehouse is a repository for relational data from transactional systems, operational databases, and line of business applications, to be used for reporting and data analysis. It’s often a key component of an organization’s business intelligence practice, storing highly curated data that’s readily available for use by data developers, data analysts, and business analysts.
Cloud data warehouses bring the added advantage of cost-effectiveness and scalability with pay-as-you-go pricing models, a serverless approach, and on-demand resources. This is made possible by separating compute and storage to take advantage of cost-effective storage and to provide a compute and data access layer specifically for fast analytics, reporting, and data mining. Learn more about the difference between a data lake and a data warehouse.
Basic Design Pattern for Cloud Data Warehouse Integration
Cloud data warehouses are a critical component of modern analytics architectures. With them, you can leverage massive amounts of data to drive product innovation, and uncover new insights for decision-making.
A basic data ingestion pattern to a cloud data warehouse starts by reading data from the source, whether on-premises or in the cloud, then converting data types and enriching records as needed. Once your data is transformed and conformed, it is stored in the cloud data warehouse, ready for analysis.
One of the most common challenges to that flow is structural drift, when data schema changes. Also of concern is semantic drift–the meaning of data are updated. If you don’t handle data drift your data drops, disappears, or never reaches its destination.

Smart Data Pipelines for Cloud Data Warehouse Integration
The Smart Data Pipeline Difference
Using proprietary data loading tools may deliver quick results, but what happens when changes come along? Smart data pipelines decouple sources, destinations and data types from the pipeline so you can make changes without rewriting, and are fully instrumented to automatically detect drift in real time.

What Smart Data Pipelines Do
- Automatically convert formats of the same data type or create new fields
- Auto-create a table or multiple tables, even when the source schema is unknown
- Enable real-time transformation regardless of source, destination, data format or processing mode
- Enable stop and restart of the pipeline and failover at the execution engine
- Improve performance and simplify debugging with built-in preview and snapshots

Managing Structural Drift
StreamSets Data Collector automatically creates columns and tables without specifying the schema when you set up your pipeline. Because the smart pipeline is not dependent on that schema, when new tables are created, StreamSets can identify the new table and edit the upstream system to accept the data. When an application or data field is added, deleted, or reordered, smart data pipelines handle it.

Frequently Asked Questions
What is the cloud data warehouse?
A data warehouse is a centralized repository of digitally stored business information used to drive reporting and data analysis. It consists of massive quantities of data extracted from numerous sources, such as relational databases, internal applications, transactional systems, and external partner systems, aggregated into unified, well-structured historical data. Cloud data warehousing brings pay-as-you-go pricing models, a serverless approach, and on-demand resources that make data warehousing highly cost-effective and scalable. Compute and storage are separated, providing a data access layer specifically for fast analytics, reporting, and data mining that makes cloud data warehousing highly efficient, too.
What are the advantages of a cloud data warehouse?
There are several! Data quality and confidence are enhanced due to having the data in a common format. Consistent data formats and more complete data sets can fuel better reporting. Cloud data warehouses store robust historical data for better insights. The unification and harmonization of data eliminate interdepartmental silos providing a single picture of operational data.