StreamSets is proud to announce an expansion of its partnership with Databricks by participating in Databricks’ newly launched Data Ingestion Network. A key component of this integration is leveraging the recently released Databricks COPY command for bulk ingest into Databricks Delta Lake using StreamSets for Databricks.
Let’s consider a simple example of ingesting accounts information from Salesforce and storing it in queryable format in a Databricks Delta Lake table.
Prerequisites
- StreamSets for Databricks
- Databricks account
- Access to a Spark Cluster with >= Databricks Runtime 6.3
- Salesforce account
Here are the steps for designing our dataflow pipeline:
- Configure Salesforce origin to read (accounts) information
- Configure Expression Evaluator processor to transform input data attribute Type
- Configure Databricks Delta Lake destination to write the data to Databricks Delta Lake table
Salesforce—Origin
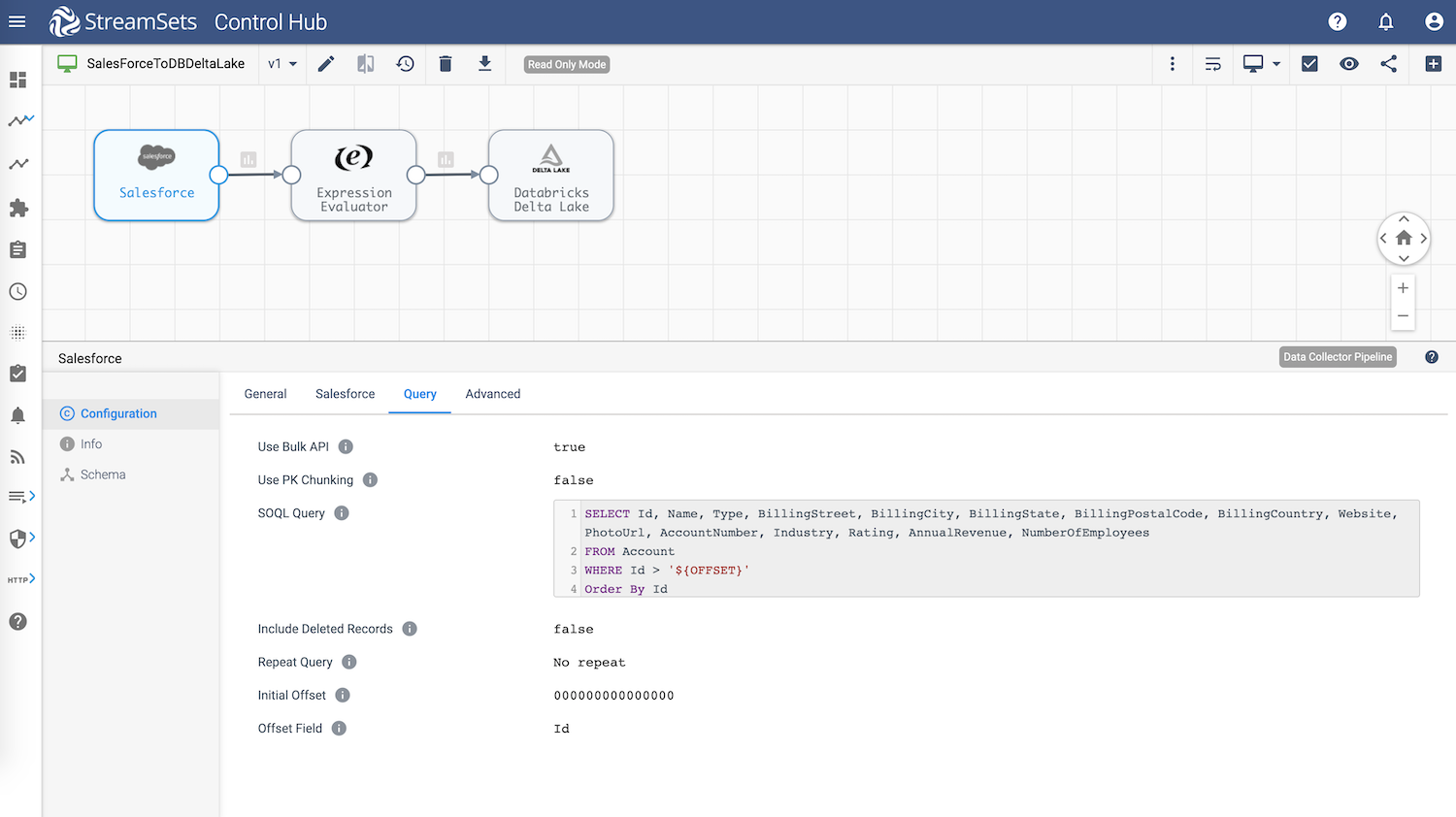
Salesforce credentials will need to entered on Salesforce tab and the other configuration attribute of interest here on Query tab is SOQL Query which will retrieve account details from Salesforce.
SELECT Id, Name, Type, BillingStreet, BillingCity, BillingState, BillingPostalCode, BillingCountry, Website, PhotoUrl, AccountNumber, Industry, Rating, AnnualRevenue, NumberOfEmployees
FROM Account
WHERE Id > '${OFFSET}'
Order By Id
Expressions Evaluator—Processor
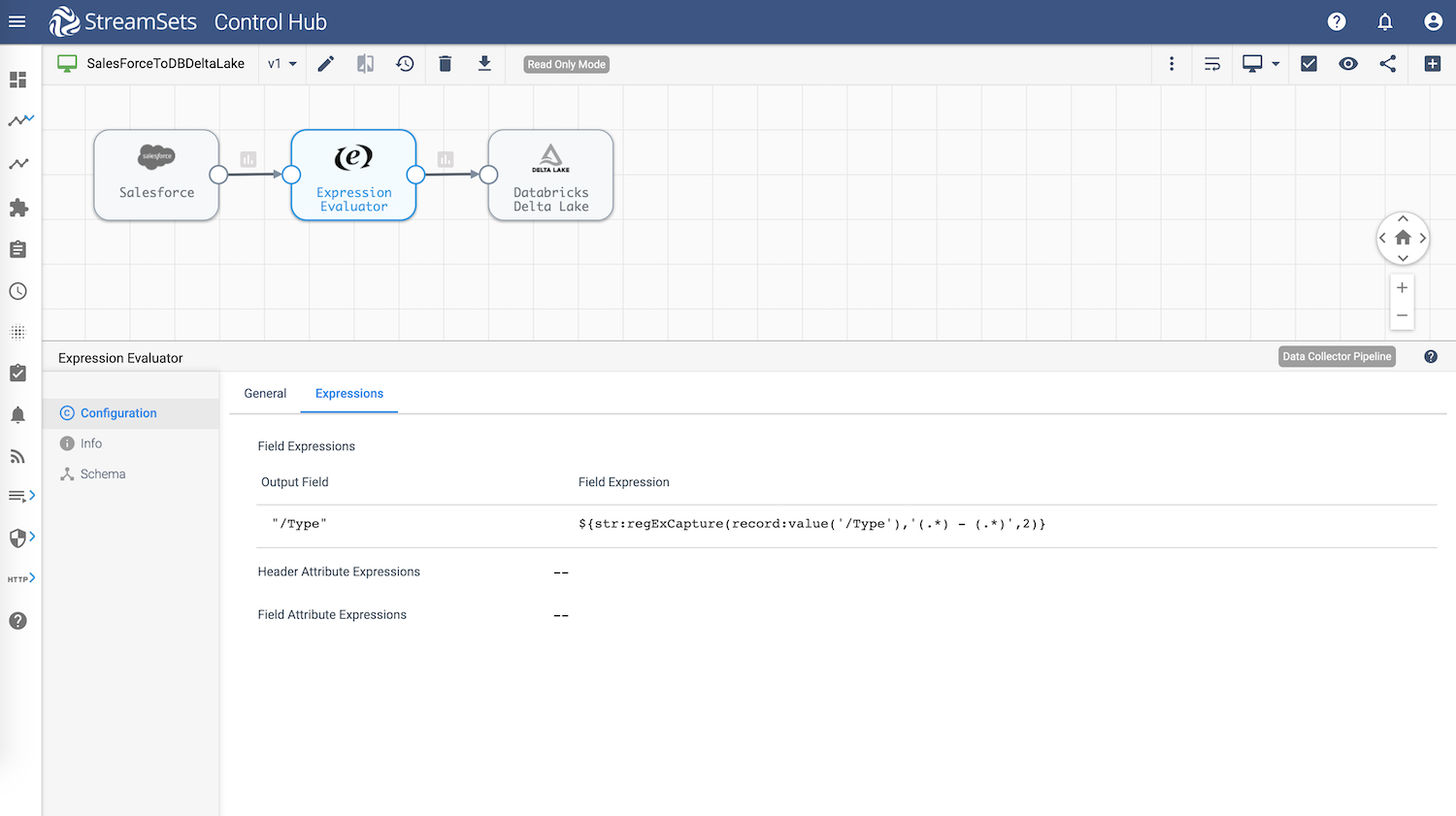
Configuration attribute of interest is Field Expression that uses regular expression to remove redundant prefix text “Customer –” from account Type field.
${str:regExCapture(record:value('/Type'),'(.*) - (.*)',2)}
Databricks Delta Lake—Destination
With Databricks Runtime version 6.3 or later, you can use the Databricks Delta Lake destination in Data Collector version 3.16 and in future releases for the following bulk ingest and CDC use cases.
- Bulk Ingest — In this case the Databricks Delta Lake destination uses the COPY command to load data into Delta Lake tables.
- Change Data Capture — When processing CDC data, the Databricks Delta Lake destination uses the MERGE command to load data into Delta Lake tables.
In this blog, we’re focused on bulk ingestion so on Salesforce origin we have the following configuration:
- Query Existing Data — Set to true
- Subscribe for Notifications — Set to false
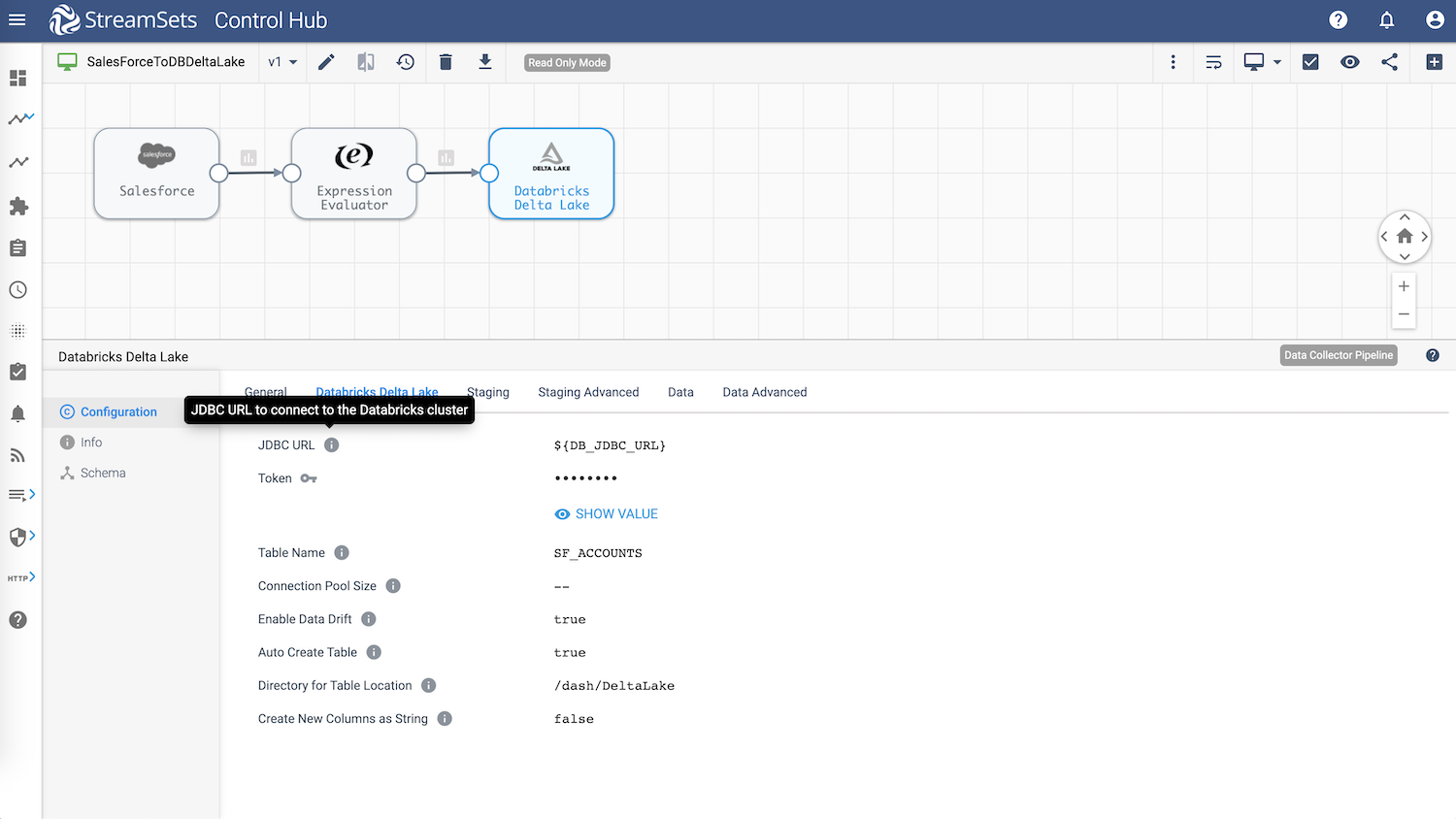
Configuration attributes of interest:
- JDBC URL — The JDBC URL to connect to the Databricks cluster
- Token — The user token to use to connect to the Databricks cluster
- Auto Create Table — Enabling this attribute will auto-create the Databricks Delta Lake table if it doesn’t already exist
Preview Pipeline
Previewing the pipeline is a great way to see the transformations occurring on attribute values. See below the selected Expression Evaluator processor and before and after values of Type attribute.
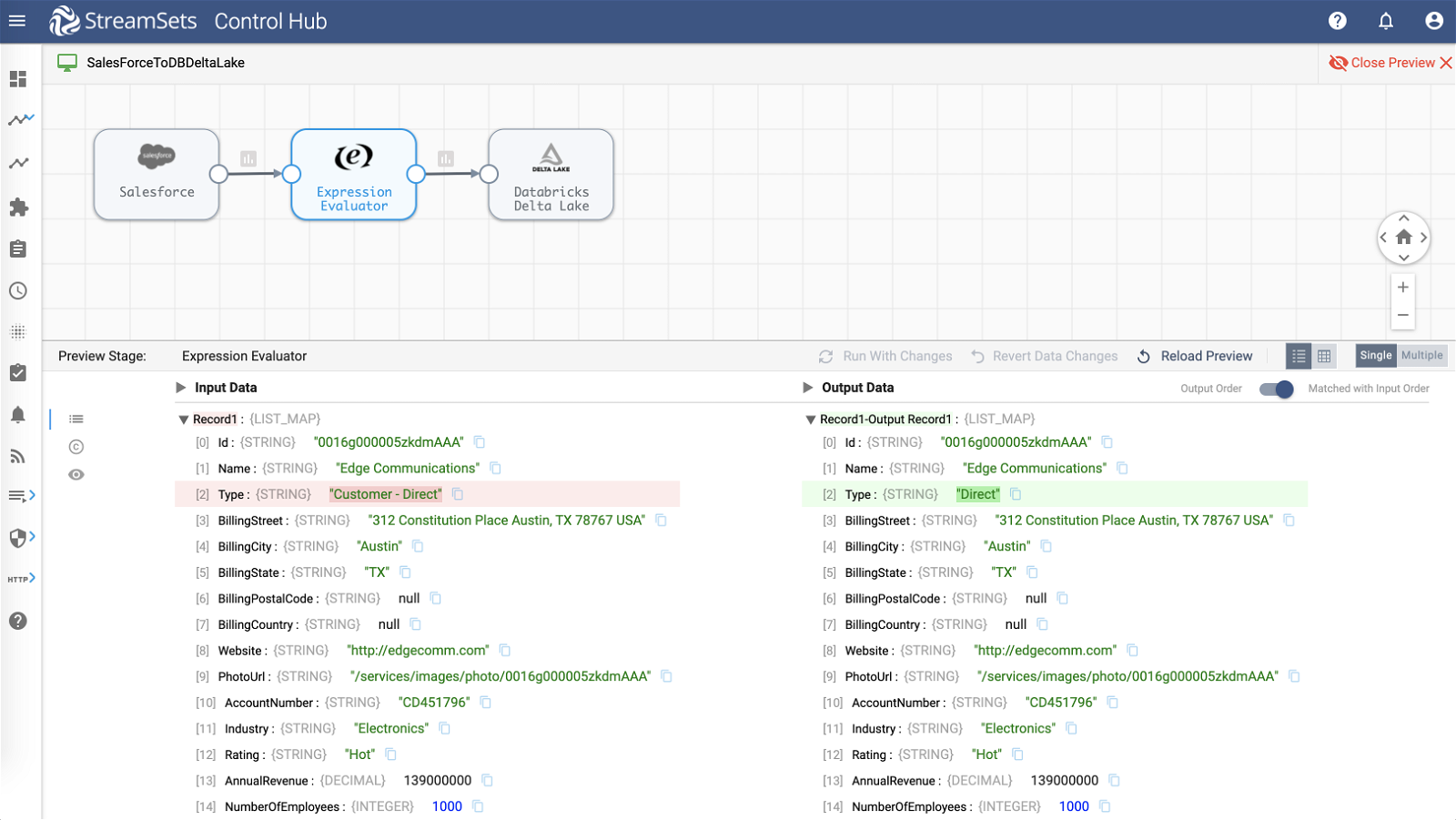
Query Databricks Delta Lake
If everything looks good in preview mode, running the pipeline should bulk copy accounts information from Salesforce to Databricks Delta Lake.
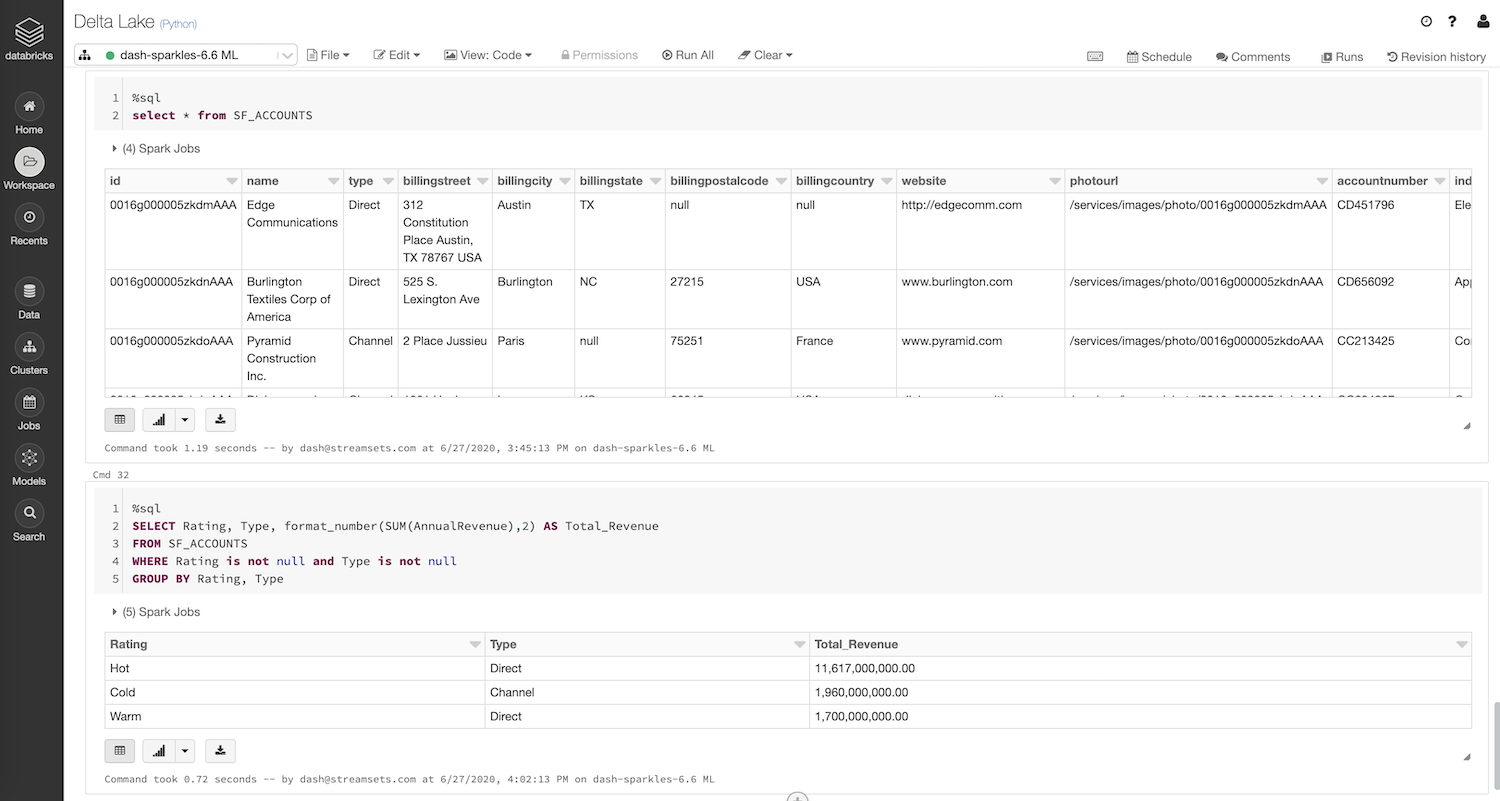
Once the Delta Lake table is populated, you can start analyzing the data. For example, running the following query will give us insights into total revenue generated based on account ratings and types of accounts.
Total Revenue by Rating and Account Type
SELECT Rating, Type, format_number(SUM(AnnualRevenue),2) AS Total_Revenue FROM SF_ACCOUNTS WHERE Rating is not null and Type is not null GROUP BY Rating, Type
Summary
In this blog post, you’ve learned how to leverage Databricks COPY command via Databricks Delta Lake destination for bulk ingest into Delta Lake table.
Learn more about StreamSets for Databricks which is available on Microsoft Azure Marketplace and AWS Marketplace.

![]()