The Encrypt and Decrypt processor, introduced in StreamSets Data Collector 3.5.0, uses the Amazon AWS Encryption SDK to encrypt and decrypt data within a dataflow pipeline, and a variety of mechanisms, including the Amazon AWS Key Management Service, to manage encryption keys. In this blog post, I’ll walk through the basics of working with encryption on AWS, and show you how to build pipelines that encrypt and decrypt data, from individual fields to entire records.
Although the Encrypt and Decrypt processor uses the Amazon AWS Encryption SDK to actually encrypt and decrypt data, it offers flexibility in its key management. You can provide a base64-encoded key directly, use Data Collector’s credential functions to securely retrieve a key from a credential store such as CyberArk or Hashicorp Vault, or leverage Amazon’s AWS Key Management Service (KMS). Here I’ll focus on AWS KMS, but many of the principles apply to whichever key provider you use.
Encryption with AWS
When you create a customer managed key (CMK) in AWS KMS, the key management service generates an encryption key within a hardware security module (HSM) located in an Amazon data center. It’s important to note that the CMK never leaves the HSM, let alone the data center; you can send data to the HSM for encryption and decryption with the CMK, but it is not possible to retrieve the CMK itself. In fact, HSMs are designed to store keys securely, even if an attacker has access to the hardware; the FIPS 140-2 standard lays out the requirements in this area, and Amazon’s HSMs have been validated against the standard.
The AWS Encryption SDK uses a two stage process called envelope encryption to encrypt and decrypt data. Let’s illustrate this using the SDK’s command line interface. After creating a CMK using the AWS KMS console, we can encrypt the data in a file with the aws-encryption-cli tool – we just need to give it the CMK ID and a file containing our plaintext data:
$ echo 'Hello world!' > myPlaintextInput
$ aws-encryption-cli --encrypt --input myPlaintextInput \
--master-keys key=$MY_CMK_ID \
--output myEncryptedMessage \
--suppress-metadata
What actually happens here is that the SDK sends a message to AWS KMS requesting a data key. AWS KMS creates the data key, sends it to the HSM for encryption with the CMK, and returns both the plaintext (unencrypted) data key and the encrypted data key to the SDK.
The SDK encrypts the data from the input file using the data key, and bundles together the CMK key ID, encrypted data key and ciphertext into the output file:
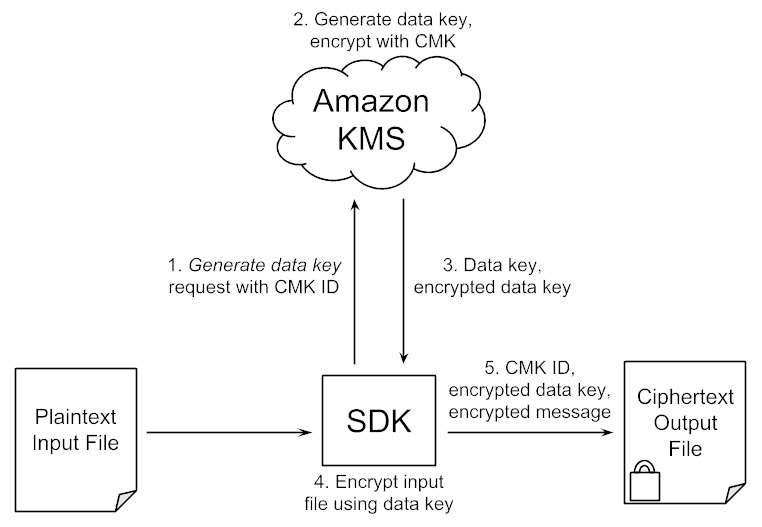
The AWS Encryption SDK documentation describes the message format in detail.
Note that the AWS Encryption SDK does not need to be running on an EC2 instance – the AWS KMS is accessible from anywhere, providing that the client app has authenticated to AWS as an authorized user.
We don’t need to provide the CMK ID to the decrypt command, since it is contained within the encrypted message:
$ aws-encryption-cli --decrypt --input myEncryptedMessage \
--output myPlaintextOutput \
--suppress-metadata
$ cat myPlaintextOutput
Hello world!
To decrypt the data, the SDK extracts the CMK ID and encrypted data key from the encrypted message and sends them to the AWS KMS, receiving the plaintext data key in response. The SDK can now decrypt the ciphertext.
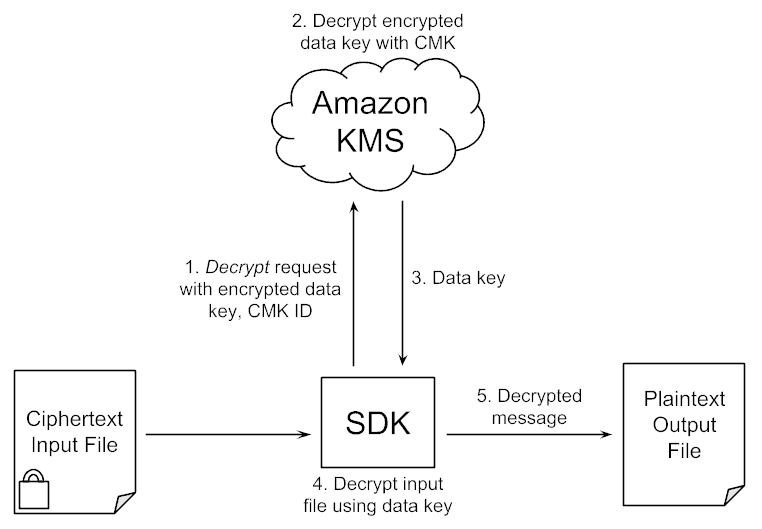
Using a fresh data key for every message is a security best practice, but there is a trade-off here: there is a cost associated with each API call to AWS KMS as well as rate limits on AWS KMS API calls. To reduce costs and stay within limits, the SDK can cache data keys and reuse them to encrypt multiple messages. This post on the AWS blog explains the trade-off and how to configure data key caching in some detail.
Let’s continue the AWS theme by combining the AWS Encryption SDK and Amazon Kinesis command line interfaces to encrypt and send a few messages to populate a Kinesis stream. Of course, we could alternatively write the encrypted data to Apache Kafka, a relational database, or any other destination.
$ for i in {1..5}
do
echo "Message $i" | \
aws kinesis put-record --stream-name pat-test-stream \
--partition-key 123 --data $( \
aws-encryption-cli --encrypt --input - \
--master-keys key=$MY_CMK_ID \
--output - \
--suppress-metadata |
openssl base64 -A \
)
done
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49591218663743518961071693279098947444369483209197486082"
}
...
Note that we need to base64-encode the binary output from aws-encryption-cli, since the AWS Kinesis command requires text input.
To read the stream and decrypt the data, we can use the same CLI tools, plus jq (an excellent command-line JSON processor), to iterate through the messages waiting in the Kinesis stream, decrypting each one in turn. Note that we need to ‘double decode’ the messages from the stream, since aws kinesis get-records base64-encodes the already base64-encoded raw message data to return it in a JSON object.
$ aws kinesis get-records --shard-iterator $( \
aws kinesis get-shard-iterator --shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--stream-name pat-test-stream |
jq -r .ShardIterator \
) | \
jq -r '.Records[]|[.Data] | @tsv' |
while IFS=$'\t' read -r data; do
echo $data | \
openssl base64 -d -A | \
openssl base64 -d -A | \
aws-encryption-cli --decrypt --input - --output - --suppress-metadata
done
Message 1
Message 2
Message 3
Message 4
Message 5
That’s as far as we’ll go with bash script; it’s useful to be able to plug CLI tools together for quick tests and examples, but, as you can see above, it can get pretty clumsy very quickly!
Encrypting Data with StreamSets Data Collector
Now that we’ve seen how to encrypt and decrypt data with the AWS Encryption SDK, and how to send and receive encrypted messages via AWS Kinesis, let’s start building dataflow pipelines.
My input data is a set of CSV files containing names, social security numbers and email addresses – sensitive data that I need to encrypt for transmission. To get started, I’ll just encrypt the name field, and send the ciphertext to the Kinesis stream. Here’s the pipeline:
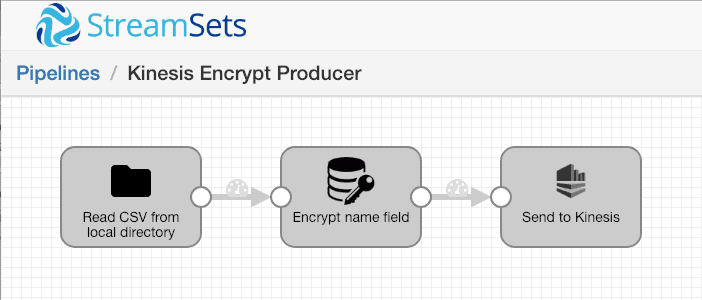
Let’s look at the Encrypt and Decrypt processor’s ‘Action’ configuration – we simply set the mode to ‘encrypt’, and specify the /name field.

The Key Provider configuration is a little more involved:
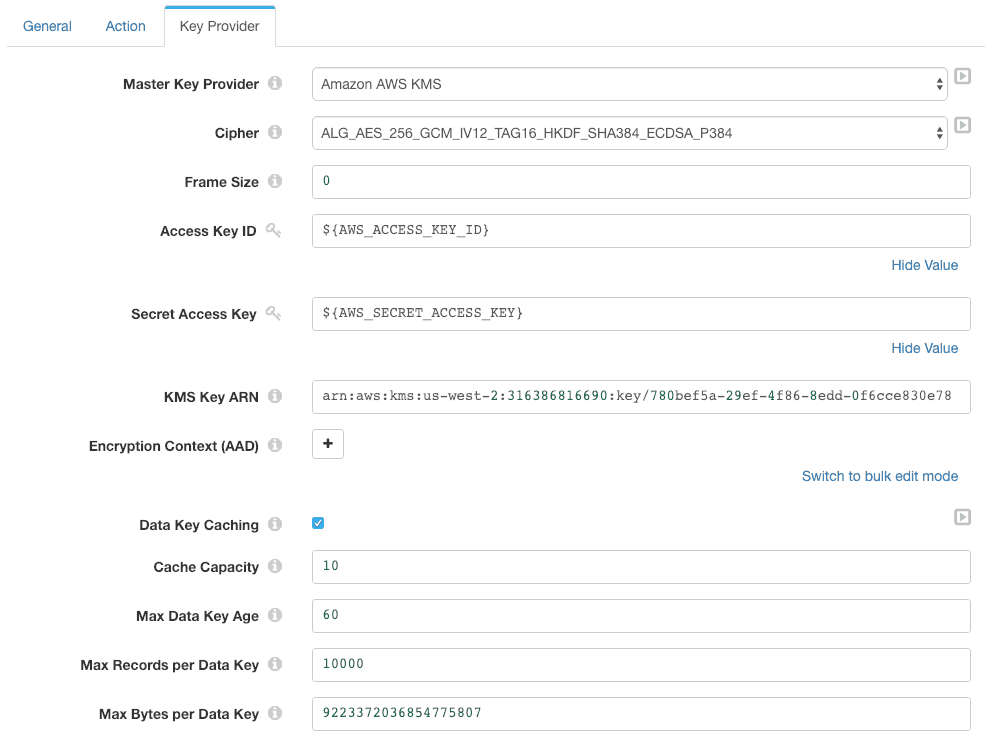
Let’s look at each configuration item in turn:
- Master Key Provider specifies that we are using the Amazon AWS KMS
- Cipher specifies the cryptographic algorithms that will be used to encrypt and (optionally) sign the message. The default selection,
ALG_AES_256_GCM_IV12_TAG16_HKDF_SHA384_ECDSA_P384, is an abbreviation for “AES 256-bit encryption with the Galois/Counter mode, a 12 byte initialization vector, 16 byte authentication tag, using the HKDF key derivation function with a SHA-384 hash and the ECDSA with P-384 and SHA-384 signature algorithm”. This suite of algorithms is recommended in the AWS Encryption SDK documentation, though you can choose alternatives. - Frame Size allows you to specify whether the data is to be split into frames for encryption, and the size of the frame – see the AWS Encryption SDK message format documentation for more detail. We set the frame size to zero here, indicating that we are sending unframed data.
- Access Key ID and Secret Access Key allow the processor to authenticate to AWS. You can leave these fields blank when using IAM roles with IAM instance profile credentials. I’m using runtime parameters here since I’m running the pipeline on my laptop, and I want to reference the same credentials in the Kinesis Producer destination.
Note: SDC-10722 prevented the Encrypt/Decrypt Processor from working with IAM instance profile credentials. This issue is fixed in StreamSets Data Collector version 3.7.1 and above. - KMS Key ARN is the Amazon resource name for the key. Note that you must provide the full ARN URI, rather than just the bare key ID.
- Encryption Context allows you to specify a series of key-value pairs that contain arbitrary non-secret data, such as metadata.
- Data Key Caching provides access to the data key cache security thresholds.
The Kinesis Producer destination is configured to simply send the /name field in binary format as the output message:

Let’s run this pipeline on a delimited data set created by Data Collector’s Data Generator origin:
$ head data1000.csv name,ssn,email Lord Cafferen,541-04-8682,ole.bosco@gmail.com Malcolm,062-46-8588,penelope.denesik@yahoo.com Martyn Lannister,085-66-2635,rosalia.crona@gmail.com Jaehaerys II Targaryen,018-10-2479,general.abbott@yahoo.com Farlen,551-77-5548,britney.heathcote@gmail.com Lymond Mallister,533-68-1123,van.vandervort@hotmail.com Jon Hollard,360-08-2781,gregg.eichmann@yahoo.com Tristifer IV Mudd,041-48-4588,brendon.okuneva@gmail.com Myria Jordayne,566-29-4951,garnet.bradtke@gmail.com
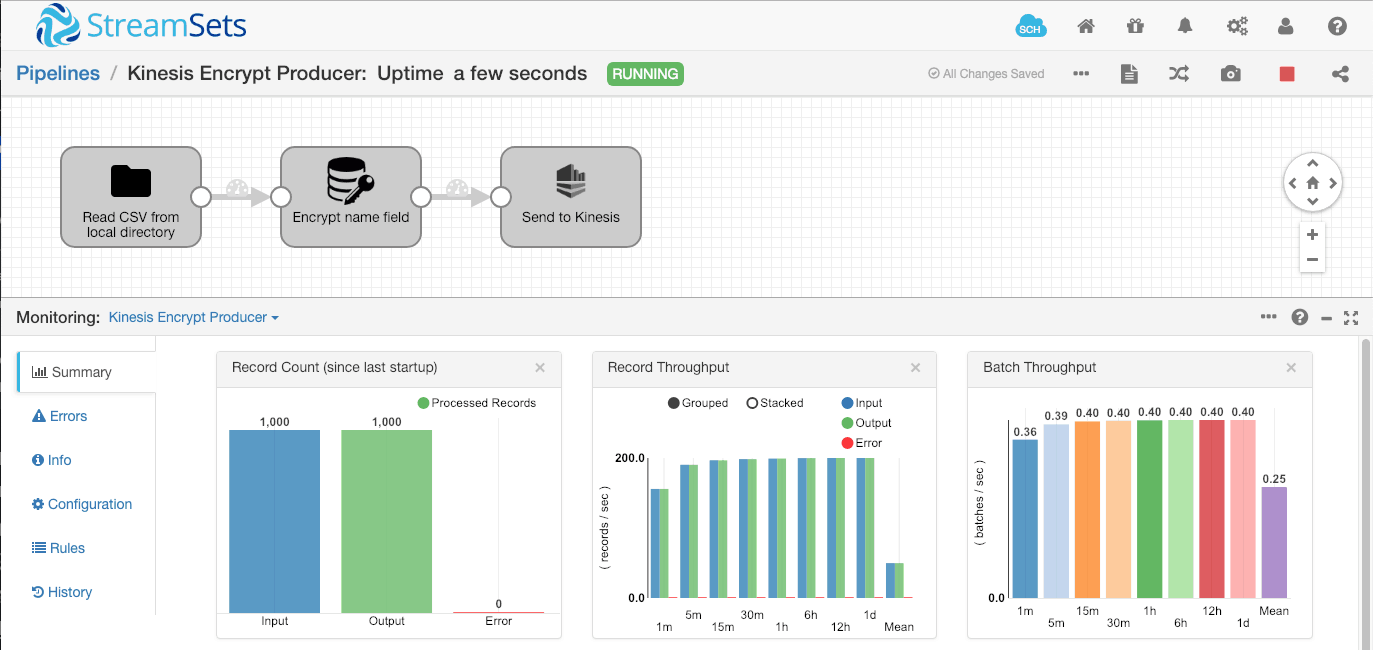
We can run a slightly modified version of the earlier shell command to retrieve and decrypt the records from Kinesis. This version only does a single base64 decode, since the Kinesis Producer destination is configured to send binary data to Kinesis:
$ aws kinesis get-records --shard-iterator $( \
aws kinesis get-shard-iterator --shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--stream-name pat-test-stream |
jq -r .ShardIterator \
) | jq -r '.Records[]|[.Data] | @tsv' | \
while IFS=$'\t' read -r data; do \
echo $data |
openssl base64 -d -A > tempfile
aws-encryption-cli --decrypt --input tempfile \
--output - --suppress-metadata \
--caching capacity=1 max_age=3600
echo
done
Lord Cafferen
Malcolm
Martyn Lannister
Jaehaerys II Targaryen
Farlen
Lymond Mallister
Jon Hollard
Tristifer IV Mudd
Myria Jordayne
Our pipeline successfully interoperates with the Amazon AWS CLI tools! Now let’s modify the pipeline to send the entire record. Since the Encrypt and Decrypt processor operates on string or binary data, we need to use the Data Generator processor to serialize the record to a suitable format, such as JSON or Avro:
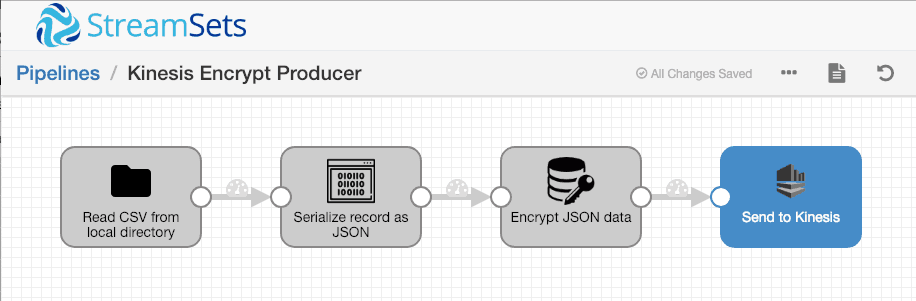
The Data Generator is configured to serialize the entire record to the /json field as JSON-formatted string data:


We also need to reconfigure the Encrypt and Decrypt processor and the Kinesis Producer destination to operate on the /json field.
Now we can empty the the Kinesis stream by deleting and recreating it, reset the pipeline origin, and rerun the pipeline. The CLI consumer shows the entire JSON-formatted record:
{"name":"Lord Cafferen","ssn":"541-04-8682","email":"ole.bosco@gmail.com"}
{"name":"Malcolm","ssn":"062-46-8588","email":"penelope.denesik@yahoo.com"}
{"name":"Martyn Lannister","ssn":"085-66-2635","email":"rosalia.crona@gmail.com"}
{"name":"Jaehaerys II Targaryen","ssn":"018-10-2479","email":"general.abbott@yahoo.com"}
{"name":"Farlen","ssn":"551-77-5548","email":"britney.heathcote@gmail.com"}
{"name":"Lymond Mallister","ssn":"533-68-1123","email":"van.vandervort@hotmail.com"}
{"name":"Jon Hollard","ssn":"360-08-2781","email":"gregg.eichmann@yahoo.com"}
...
Since the sending pipeline uses the AWS access key ID and secret access key, it does not need to run on EC2. In fact, while I was writing this blog post, I ran the pipeline and CLI tools on my laptop.
Decrypting Data with StreamSets Data Collector
Now let’s turn to the receiving pipeline. This pipeline will run on EC2, reading encrypted records from Kinesis, decrypting them, and writing the decrypted data to MySQL running on Amazon RDS.
Before starting the EC2 instance, I created an AWS IAM role with 2 policies:
- Allow KMS decryption with the CMK I created earlier
- Allow access to Kinesis as a consumer. There are several permissions that must be granted for a Kinesis consumer – they are listed in the Kinesis documentation. Note that you must grant permissions in DynamoDB as well as Kinesis.
I then started an Ubuntu EC2 instance with the IAM role, downloaded and extracted the StreamSets Data Collector tarball, started Data Collector and created my pipeline:
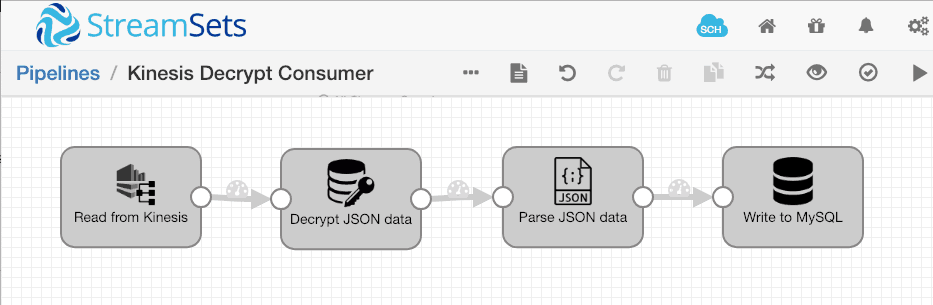
Because I started the EC2 instance with an IAM role, I could leave the access key ID and secret access key blank in the Kinesis Consumer configuration. The Kinesis Consumer will receive the permissions I assigned to the IAM role:
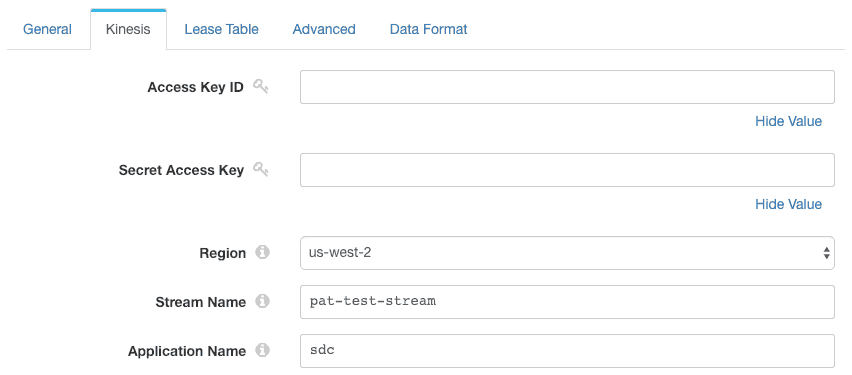
I configured the Kinesis Consumer to read binary data:
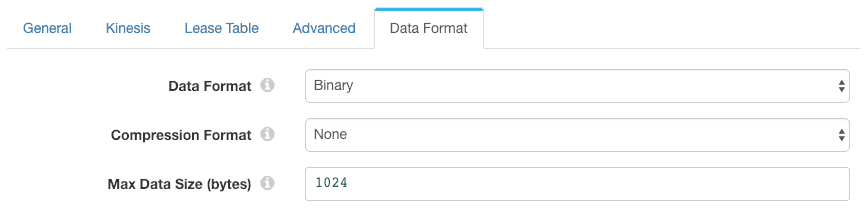
The Encrypt and Decrypt processor is set to decrypt the root field:

Again, we leave the access key ID and secret access key blank, so the processor will leverage the IAM role:
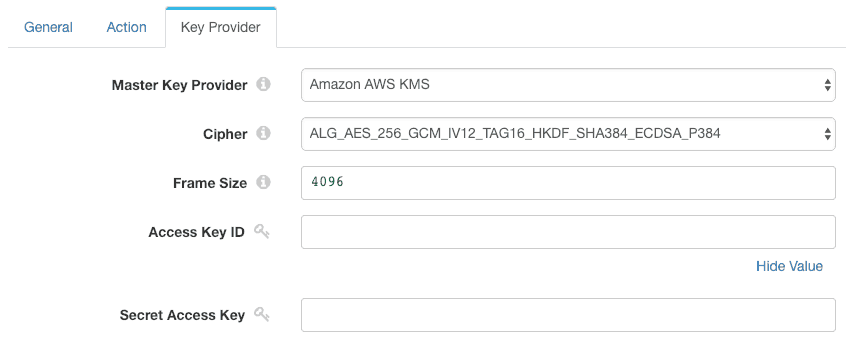
As mentioned earlier, SDC-10722 prevented the Encrypt/Decrypt Processor from working with IAM roles. This issue is fixed in StreamSets Data Collector version 3.7.1 and above.
To keep things simple, I created a table in MySQL matching the record structure – this allowed me to avoid configuring any field-column mappings in the JDBC Producer:
mysql> DESCRIBE contact; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | name | varchar(32) | YES | | NULL | | | ssn | varchar(16) | YES | | NULL | | | email | varchar(64) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec)
Running the pipeline, we can see the 1000 records in the Kinesis stream being read, decrypted, and written to MySQL:
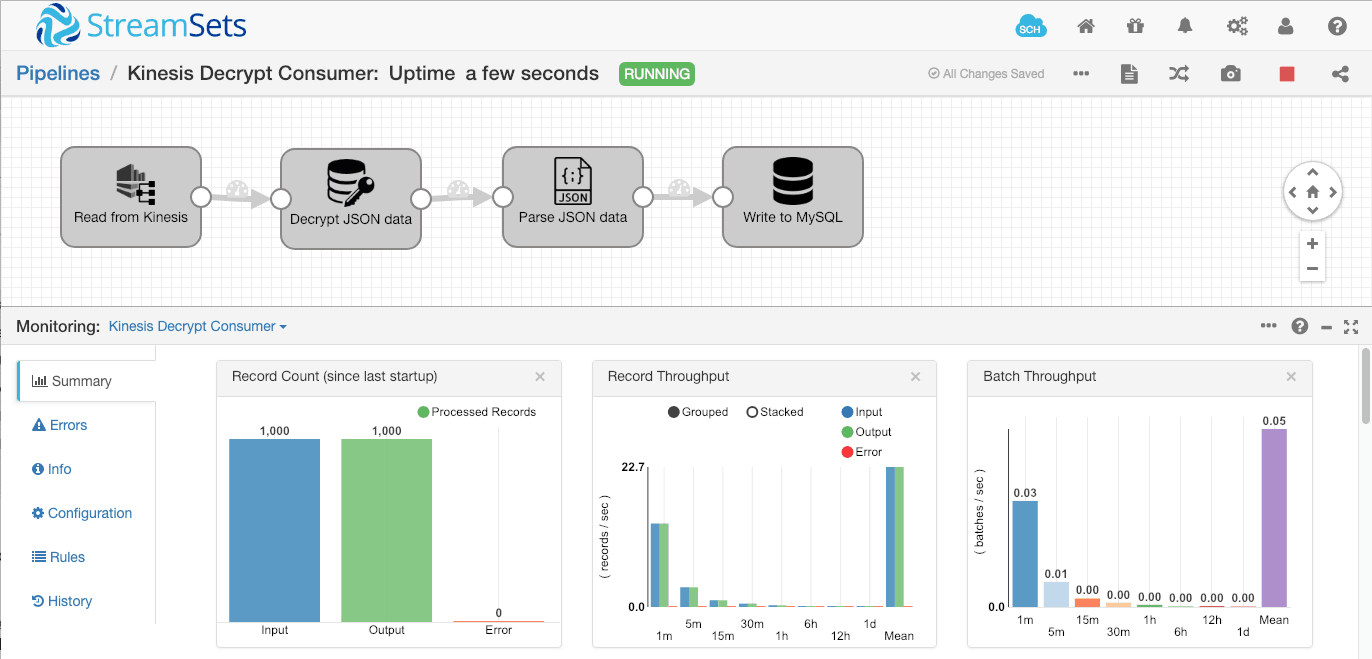
And looking in the database, we can see that the data was, indeed written:
mysql> select count(*) from contact; +----------+ | count(*) | +----------+ | 1000 | +----------+ 1 row in set (0.00 sec) mysql> select * from contact limit 10; +------------------------+-------------+-----------------------------+ | name | ssn | email | +------------------------+-------------+-----------------------------+ | Lord Cafferen | 541-04-8682 | ole.bosco@gmail.com | | Munciter | 586-96-9116 | hugh.bahringer@hotmail.com | | Jon Vance | 178-68-0573 | manuel.kihn@yahoo.com | | Malcolm | 062-46-8588 | penelope.denesik@yahoo.com | | Albett | 559-27-6376 | frida.rau@yahoo.com | | Martyn Lannister | 085-66-2635 | rosalia.crona@gmail.com | | Jaehaerys II Targaryen | 018-10-2479 | general.abbott@yahoo.com | | Farlen | 551-77-5548 | britney.heathcote@gmail.com | | Lymond Mallister | 533-68-1123 | van.vandervort@hotmail.com | | Jon Hollard | 360-08-2781 | gregg.eichmann@yahoo.com | +------------------------+-------------+-----------------------------+ 10 rows in set (0.00 sec)
The consumer pipeline running on Amazon EC2 successfully read our 1000 records from Kinesis, decrypted them, and wrote them to MySQL on Amazon RDS.
Conclusion
It’s straightforward to build pipelines with StreamSets Data Collector’s Encrypt and Decrypt processor. The processor uses the Amazon AWS Encryption SDK and integrates seamlessly with the Amazon AWS Key Management Service. You can use the processor with individual fields, or generate a JSON or Avro representation of the entire record, and send encrypted data to any destination.
Download StreamSets Data Collector today and try out the Encrypt and Decrypt processor – Data Collector is open source and available in a number of binary formats.