Guest post by Jeff Evans, Senior Software Engineer, StreamSets.
The Field Mapper processor, introduced in Data Collector version 3.8.0, provides a flexible and powerful way to manipulate fields en masse in your records. It operates in one of three modes:
- Field paths: The location within the context of the entire record and is useful for moving fields around the record, grouping, aggregating, etc.
- Field names: Within a containing parent MAP field and is useful for stripping out special characters from field names, changing case, etc.
- Field values: When performing an operation on every field value, such as initializing nulls with a default, changing the type, stripping characters or trimming a string, etc.
When it runs, the Field Mapper processor traverses every field in the record and applies some mapping expression to modify the field’s path, name, or value depending on the mode chosen. In addition, a filter expression can be provided so that only certain fields are processed. Finally, an aggregation expression can be specified to handle the case where multiple fields are mapped to the same path.
Perhaps the best way to explain how the processor works is to draw an analogy to Java 8 streams. Consider the following code snippet:
fields.stream().filter(
f -> f.getType() == Field.Type.STRING
).map(f -> f.getValue() + "_updated").collect(Collectors.toList())
This code creates a stream from a collection of fields. Then, it filters items out of that stream, keeping only those whose type is STRING. Next, for those items that satisfy the filter, it maps them to a new value, by appending _updated to the current value. Finally, it collects the modified items into a single result, by building a list.
In the Field Mapper processor, there is an analog for each component of the code snippet above.
- The Filter function is specified with the Conditional Expression
- The Map function is specified with the Mapping Expression
- The Collect function is specified with the Aggregation Expression
The Field Mapper can perform many of the operations currently provided by other processors, such as the Field Replacer or Field Renamer, but with one advantage—the full set of input paths doesn’t need to be known or specified up front. However, its capabilities go much further.
Use Case: length of the longest string field
There are some simple examples outlined in the documentation. But you can also chain together multiple mappers in order to achieve more complex behaviors. For example, if you want to determine the length of the longest string field in your record. That can be achieved by a sequence of three Field Mapper processors described as follows:
1) One operating on field names, to create a new copy (via the preserve paths option) of each STRING type field with the _length suffix.
2) Another operating on the value of each of the new _length suffixed fields created in the previous step. It replaces the STRING value with its length, an INTEGER.
3) A final one operating on the paths of each of the new _length suffixed fields. It changes the path to a single new output field, with an aggregation expression that calculates the max value of the lengths.
You can see how the record changes after each of these processor stages through this sequence of preview screenshots.
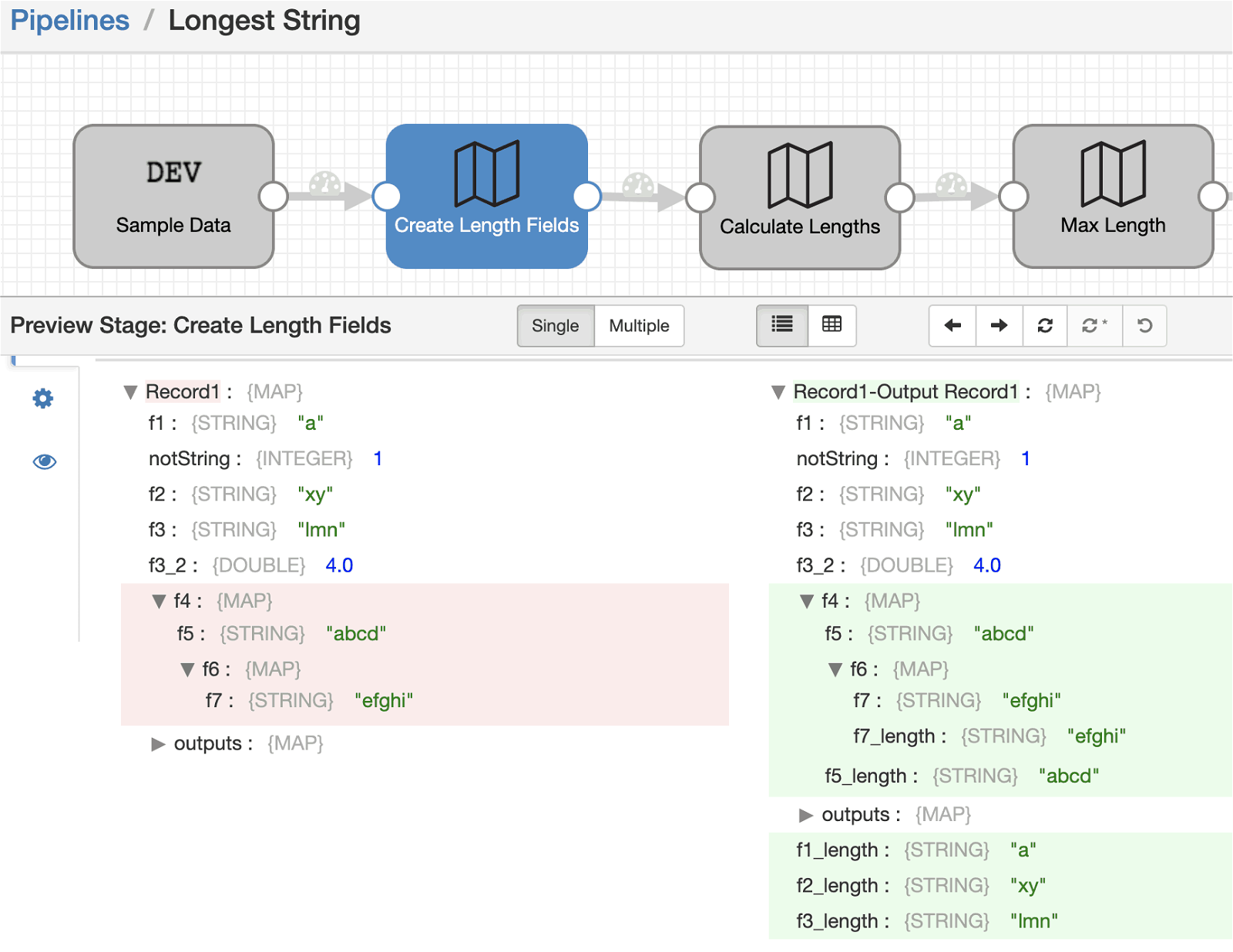
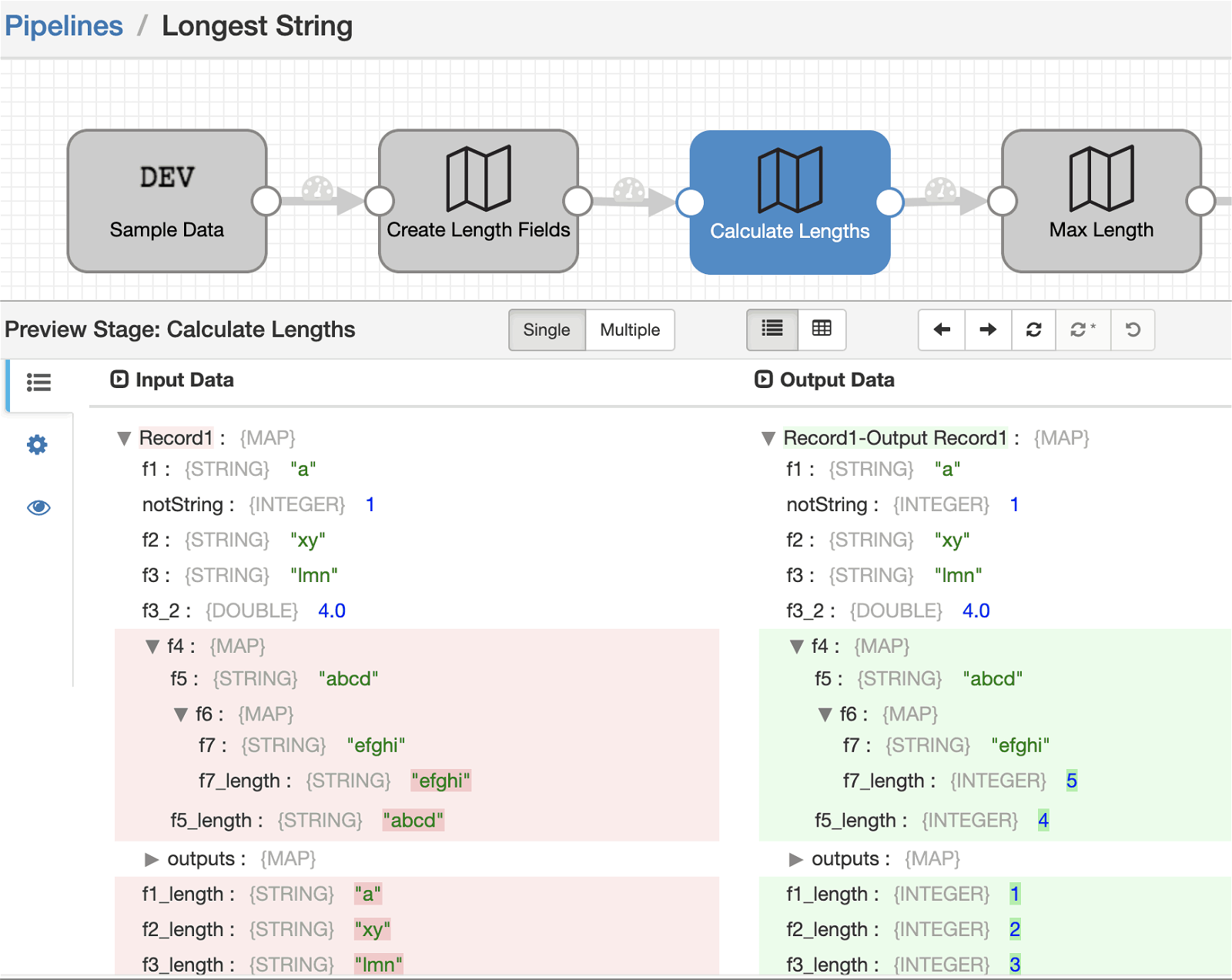
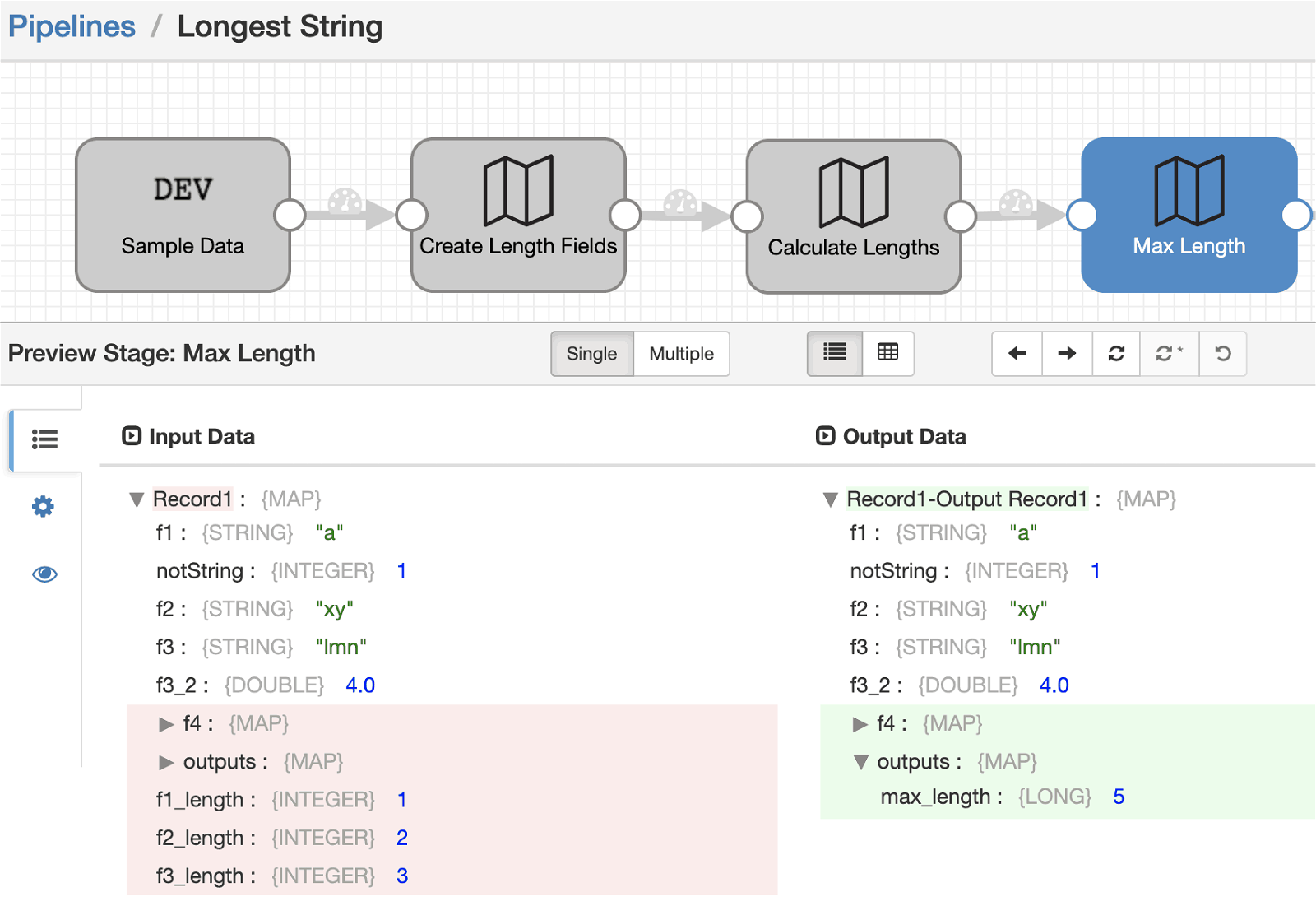
Try it out
To see this in action, import the pipeline into your Data Collector (version 3.8.0 or later) instance and run a preview.
Use Case: converting specific field attributes
Consider another use case of converting specific field attributes to new “sibling” fields. This can be useful in cases where you want to capture certain attributes from all fields. Similarly to the previous case, we can chain together a sequence of Field Mapper processors to accomplish the task at hand.
1) One operating on field paths, to create a new copy (via the preserve paths option) of each field having the desired attribute with the _myattr suffix.
2) Another operating on the value of each of the new _myattr suffixed fields created in the previous step, replacing the field value with the attribute value.
Try it out
Import the pipeline into your Data Collector (version 3.8.0 or later) instance and run a preview.
Summary
As you can see, the Field Mapper processor is a useful tool for manipulating your record fields, regardless of their structure. But we’re not finished yet. Stay tuned!
Note that currently, if you are rewriting field paths, you will need to ensure that the target path is reachable. That means that there are MAP fields already in place for all parent components of the path. For example, if a field’s path is mapped to /a/b/c, then there must be a root level MAP field, with a child MAP field named A, with a child MAP field named B. There is an open enhancement request to relax this restriction. Support for operating on field attributes is also being considered. Finally, we are also open to adding more functions for use in the aggregation expression.
StreamSets Data Collector is open source, under the Apache v2 license. To download for free, visit Download page.