In this current age of data dominance, organisations are grappling with the influx of substantial amounts of real-time data. Data processing pipelines must manage high volume requirements while maintaining accuracy and performance standards, making the management of this data explosion a significant challenge. StreamSets, one of the top data integration platforms, provides a range of tools and methods to boost efficiency when working with big data sets.
A basic understanding of StreamSets will simplify your journey towards boosting performance in high data volume scenarios. StreamSets is an effective platform created to address the difficulties brought about by enormous amounts of data produced in real-time. It is a critical instrument in the big data era because of its simple, intuitive interface, which enables enterprises to efficiently ingest, transform and transmit data across various platforms. If you do not have prior knowledge, you can learn the basics about StreamSets from this simple tutorial. The next section will introduce you to how you can optimize StreamSets to make your job efficient.
How to optimise performance in high-volume data-streams using StreamSets
There are various approaches to optimizing data since it is also collected and stored in numerous formats. The following steps will help you improve your data optimization approach.
Understand Your Data and Requirements
The first step towards optimising performance is to understand your data requirements. Here are the considerations:
- Determine the features of your data and the specific requirements of your use case.
- Consider the capabilities of your storage systems.
- It’s also important to note that optimising a high-volume data stream is a recursive process. You may be required to test different methods before identifying the one that operates efficiently.
Identifying Performance Bottlenecks
This is another way of optimising performance and can be done using various tools and techniques on streamers such as:
Logging and Monitoring: StreamSets provides comprehensive logging and monitoring capabilities that allow you to track the performance of each stage in your pipeline. To understand about monitoring, you can read about it here.
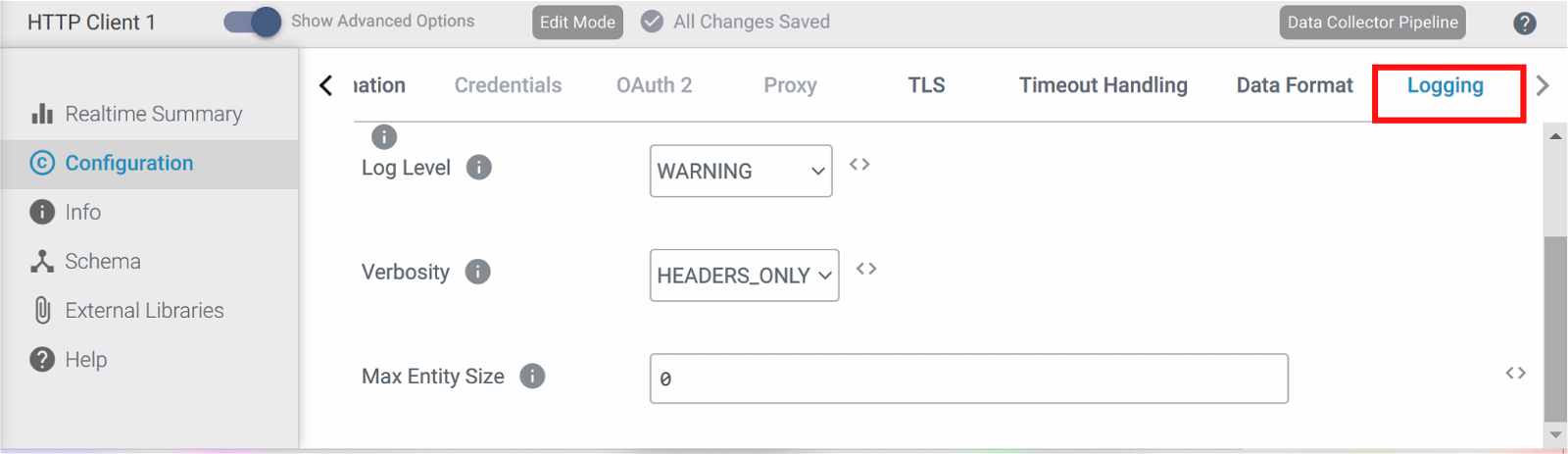
Profiling: Profiling tools can help you identify which stages of your pipeline are consuming the most CPU or memory resources.

Load testing: Load testing can be used to simulate high-volume data streams and identify performance issues under load.
Finetuning Data Ingestion
The data ingestion stage is often the first concern in a data processing pipeline. To optimize data ingestion, consider the following techniques:
Handling Error Records: Set accurate measures for errors that may occur in your pipeline. Error messages help identify the inaccuracies in the data. Choosing an efficient error handling method optimises your data stream for scalability in real-time.
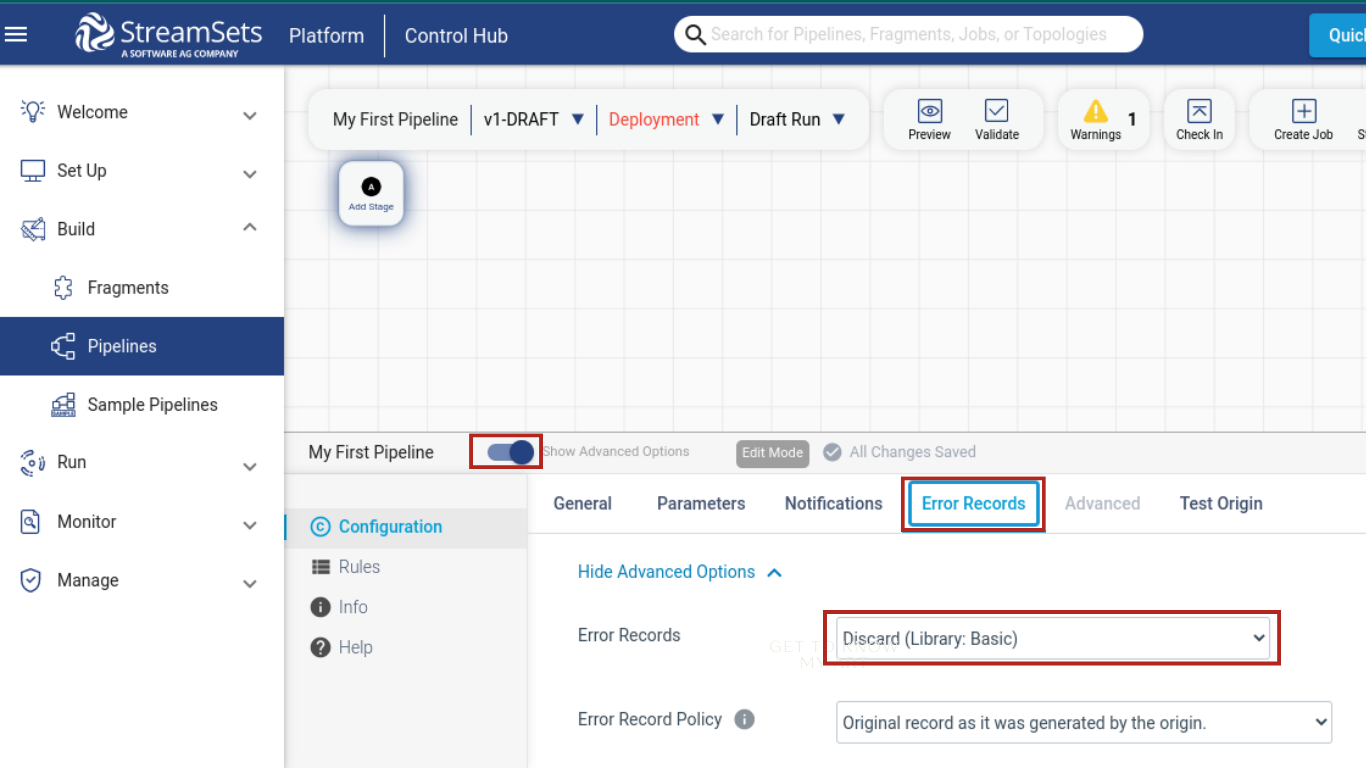
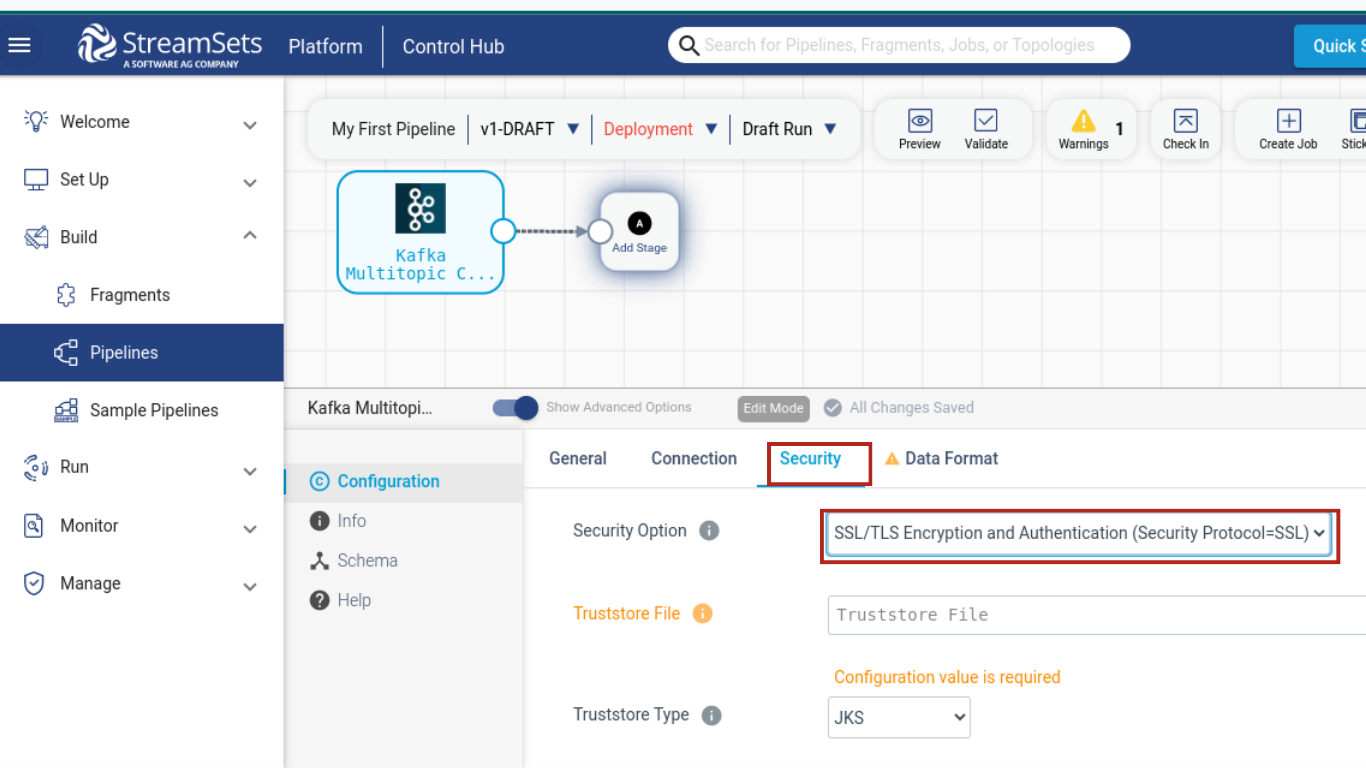
Use Efficient Data Sources: Choose data sources that are optimized for high-volume data ingestion, such as Kafka or Apache Flume. When utilising multiple data sources, confirm that each supports real-time streaming and encryption to safeguard sensitive information. A source like Kafka notifies you of the state of your pipeline and provides an update on the error state to your desired location.
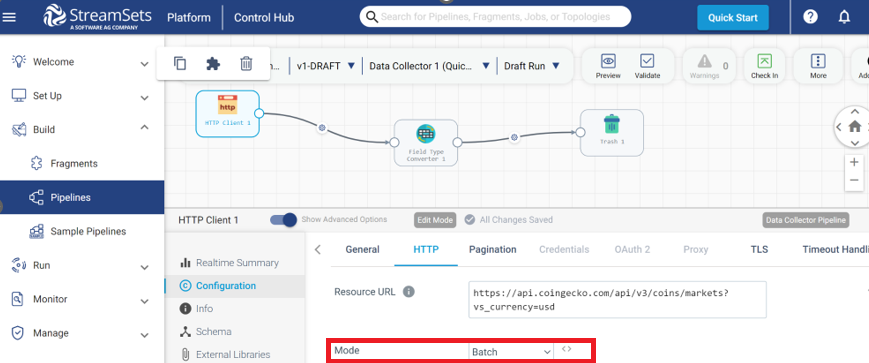
Processing and Processor: Batch processing is suitable for scheduled high-volume data tasks, such as report generation. Batch processing has higher latency, while streaming and polling offer lower latency, resulting in quicker responses. The choice depends on the specific use case: batch processing is efficient for large computations, streaming provides real-time updates, and polling is utilised when real-time updates are unavailable.
Data compression: Compressing data before ingestion can reduce the amount of data that needs to be transferred and processed. Through StreamSets, you can optimise data streaming performance through compression.
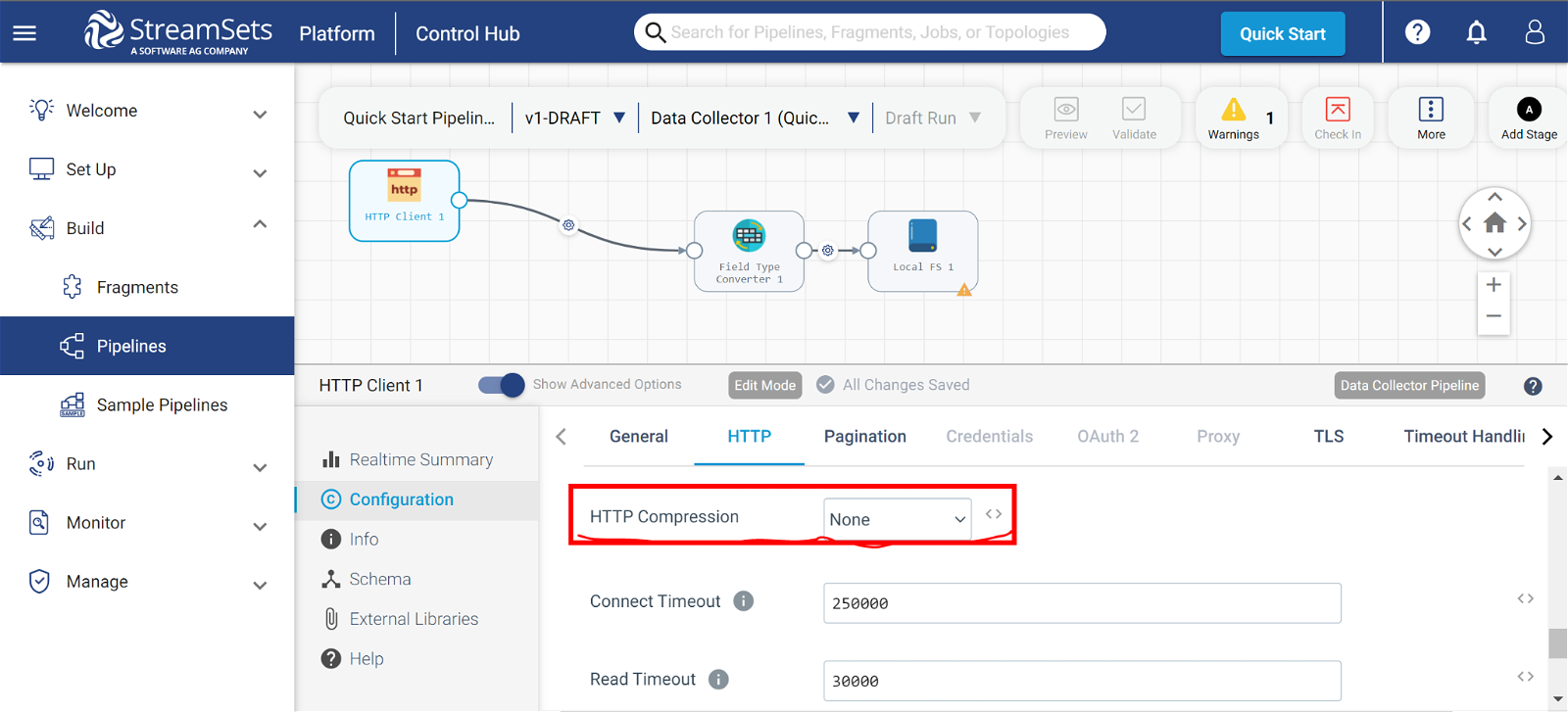
Optimizing Data Transformation
Data transformation can be a resource-intensive process. To optimize data transformation, apply the following techniques:
Push-Down Processing: This technique reduces the amount of data that needs to be transferred by pushing the transformation logic down to the data source. By doing this, only the processed data is transmitted, which enhances efficiency. This approach is effective in scenarios where bandwidth is a concern, as it optimises data transfer by minimizing the amount of transmitted data through pre-processing at the source. To achieve push-down processing in StreamSets practically, you can follow these steps:
To push down processing using a predicate:
- Include a filter stage in your pipeline.
- To filter the data appropriately, configure the predicate.
Push down processing using a push-down processor:
- Add a push-down processor stage to your pipeline.
- Configure the Push-Down Processor stage to execute the specified processor on the source system.
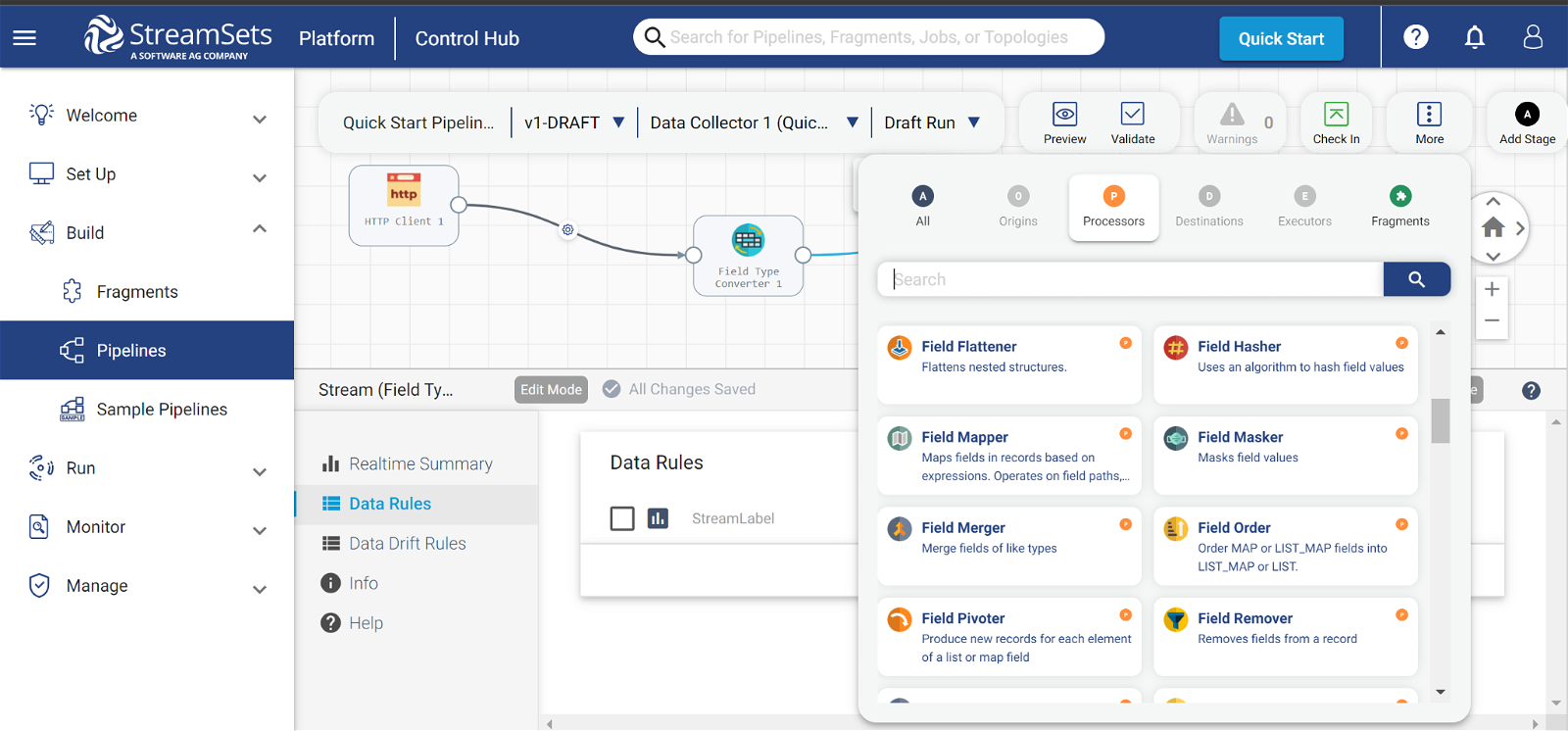
Transformation Processing: Using transformation processors, you can increase performance by performing specific operations on several data elements at once. Transformation processors empower you to manipulate and shape your data into meaningful formats for analysis and downstream applications. The following are a few operations you can perform using transformation processors.
- Join: When you use more than one origin in a pipeline, you can use the Join processors to join the data read by the origins. Join processors enable you to merge data from multiple sources based on common fields, creating a unified dataset. An example of a processor that is used to join multiple data sets is the Field Merger.
- Apply Functions: You can use processors for general-purpose function applications, including mathematical, string, date/time, conditional, logical, and custom functions. Below are a few processors that can help you achieve this;
- Field Mapper: For basic value transformations and simple field-to-field mappings.
- Expression Evaluator: Used for complex expressions with numerous fields and variables, as well as conditional logic.
Common Function Examples:
- Mathematical: ADD, SUBTRACT, MULTIPLY, DIVIDE
- String: CONCAT, UPPER, LOWER, TRIM, REPLACE, SUBSTRING
- Date/Time: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND
- Conditional: IF, CASE, COALESCE
- Logical: AND, OR, NOT, IN, BETWEEN
Slowly Changing Dimensions (SCDs): The technique of Slowly Changing Dimensions (SCDs) is a data modelling approach that is utilised to handle dimensional data changes (such as customer, product, and location) over time while maintaining historical accuracy for reporting and analysis. StreamSets provides the SCD Processor to implement SCD logic within pipelines. The following are the key steps to applying SCD.
Key Steps:
- Master Origin: Specify the source of the master dimension data.
- SCD Type: Select the chosen SCD type.
- Key Fields: Identify fields used to match records for updates.
- Change Fields: Specify fields that trigger updates when changed.
- History Fields: Define fields to store historical values (Type 2).
Caching: Caching frequently accessed data can reduce the amount of data that needs to be read from disk or other sources. This can be done in two ways:
- In-memory caching: This is the default caching in StreamSets. This stores data in the memory of the StreamSets Data Collector. Although this caching method is quick and effective, it is constrained by the data collector’s memory capacity.
- Persistent caching: This type of caching stores data on disk or in a distributed cache, such as Redis. Persistent caching is slower than in-memory caching, but it can store more data and is more resilient to failures.
To enable caching in StreamSets, it is necessary to add a cache stage to your pipeline. While it can be placed anywhere within the pipeline, the cache stage typically follows a stage that handles data in batches. Enabling caching allows the storage of the previous stage’s output. The Cache stage inspects the cache for new data; if it finds any, it skips processing and forwards the data to the next stage. If it doesn’t find any new data, it processes the data and caches it.
Handling Batch and Real-Time Data: When you select your data origin or destination, StreamSet provides three (3) options where you can choose between batch, polling or streaming while also supporting varieties of batch data sources.
Monitor And Scale the Pipeline: Leveraging the StreamSets inbuilt features, you can monitor and scale your pipeline. StreamSets presents visuals about the data which makes the it easy to understand.
Conclusion
StreamSets stands out as a robust tool for processing and scaling high-volume data. By meticulously following the steps outlined above, you can fine-tune your StreamSets pipelines to effortlessly manage the most challenging data workloads. These strategic measures guarantee that your StreamSets pipelines are not only capable but exceptionally efficient in processing and scaling high-volume data.