 MapR-DB is an enterprise-grade, high performance, NoSQL database management system. As a multi-model NoSQL database, it supports both JSON document models and wide column data models. MapR-DB stores JSON documents in tables; documents within a table in MapR-DB can have different structures. StreamSets Data Collector enables working with MapR-DB documents with its powerful schema-on-read and ingestion capability.
MapR-DB is an enterprise-grade, high performance, NoSQL database management system. As a multi-model NoSQL database, it supports both JSON document models and wide column data models. MapR-DB stores JSON documents in tables; documents within a table in MapR-DB can have different structures. StreamSets Data Collector enables working with MapR-DB documents with its powerful schema-on-read and ingestion capability.
With StreamSets Data Collector, I’ll show you how easy it is to stream data from MongoDB into a MapR-DB table as well as stream data out of the MapR-DB table into MapR Streams.
In the example below, I will use MongoDB to capture CDC data from the oplog, cleanse and enrich the data in the documents, and persist them in MapR-DB JSON table. I’ll also create another pipeline to read data from this JSON table and put the documents into a topic within MapR Streams for other downstream applications to consume.
Enabling oplog for CDC in MongoDB
To create a MongoDB database with CDC enabled, use a local instance of mongo and enable oplog for this standalone mongod server. To enable oplog, start mongo server with --master option as follows:
mongod --master --dbpath mongo_data
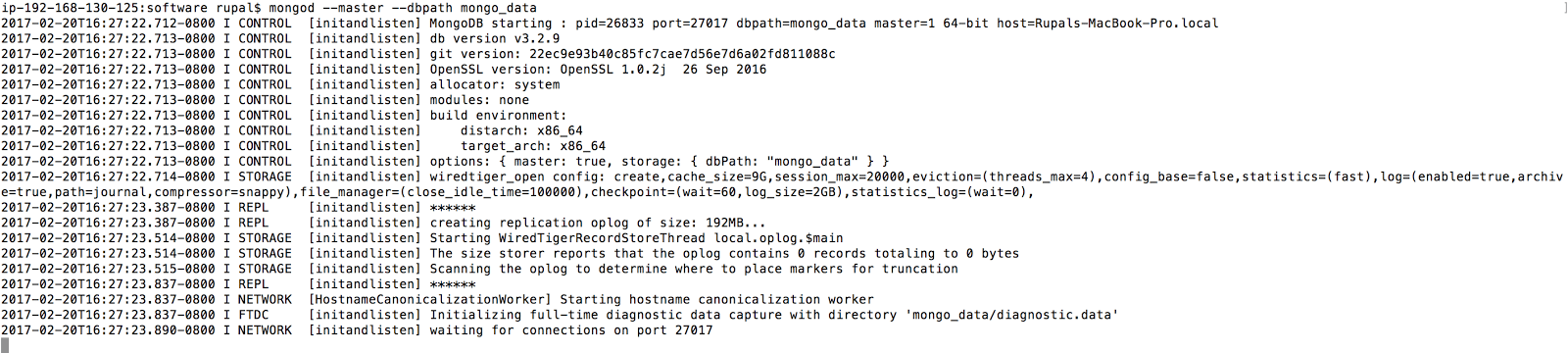
Open a terminal to work with the mongo server and create a database called retail_db:
mongo use retail_db

Create a capped collection called pos_data:
db.createCollection("pos_data",{"capped":true,"size":10000})
Create a new pipeline and drop in a MongoDB Oplog Origin and configured the values shown below in the MongoDB tab:
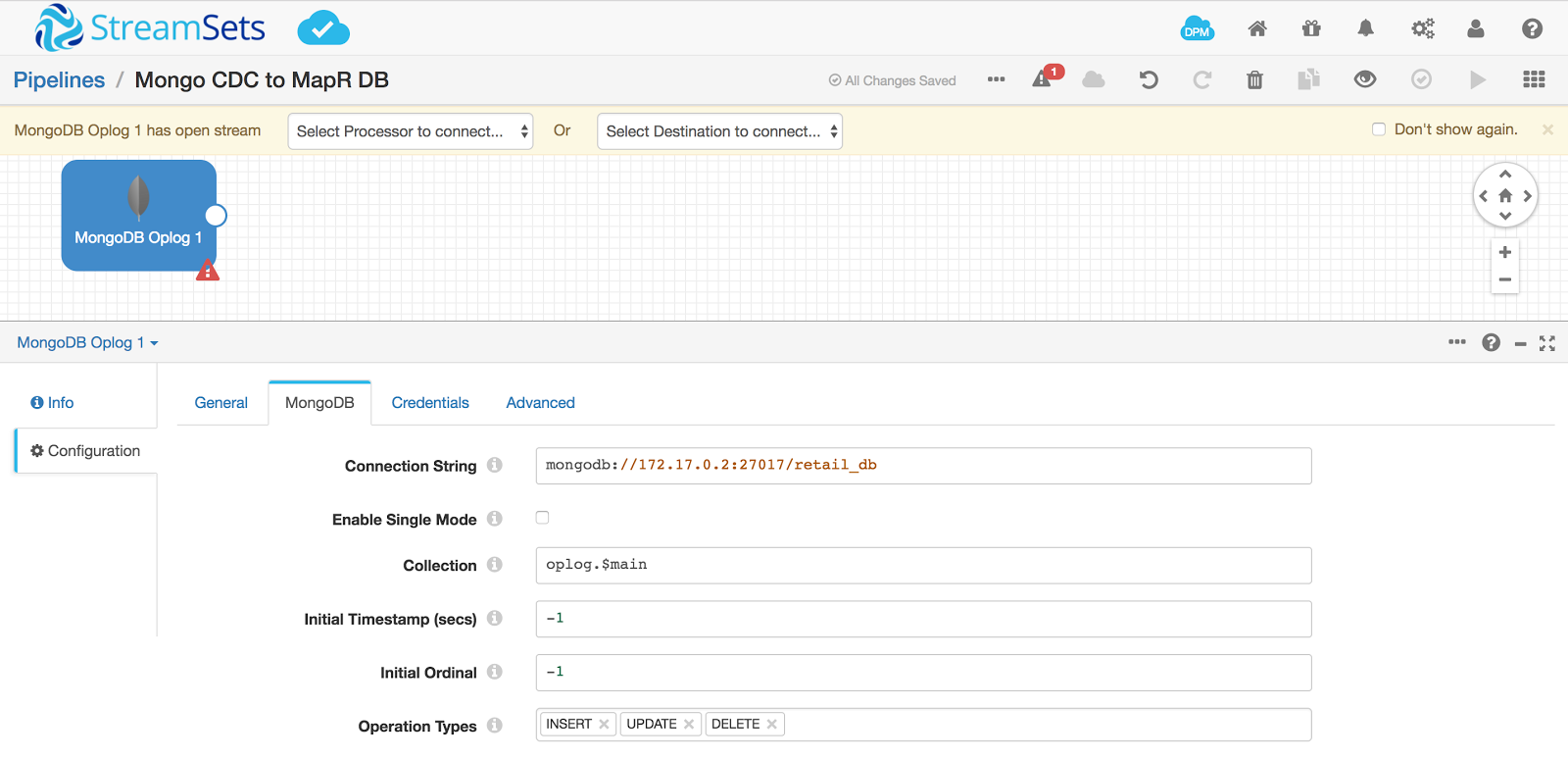
Writing JSON Data to MapR-DB
Next, add the destination by selecting MapR-DB JSON from the drop down list.
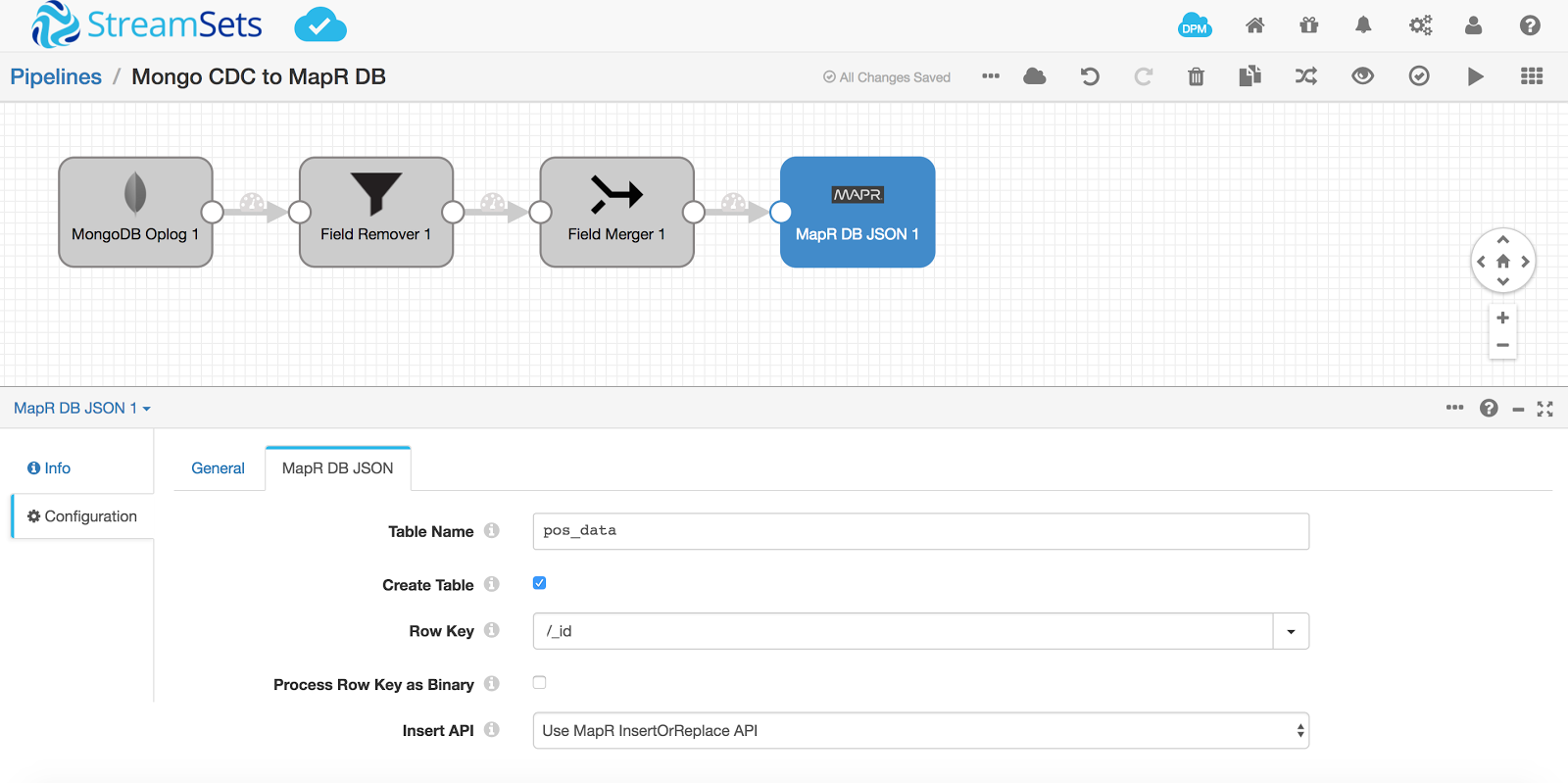
Provide the Table Name same as the collection name, that is pos_data.
Check the option to create the table if it doesn’t exist in MapR-DB.
Documents inside MapR-DB must have a unique identifier stored in the _id field. I’m using the _id generated by MongoDB when documents are created in the collection for the _id field in the MapR-DB table.

With the pipeline configured with the origin and destination, and error records sent to ‘Discard’, validate the pipeline. This checks that the connection string specified is valid and a successful connection can be made to the mongo server. It also validates that the MongoDB database has the oplog specified, meaning the database is enabled for CDC.
Open a terminal and run mapr dbshell to work with MapR-DB JSON tables:
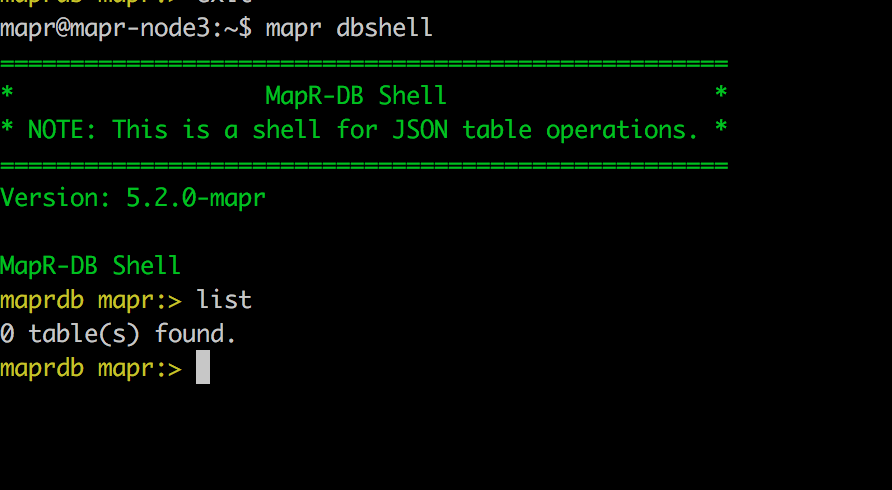
At this time, there is no data to preview in the pipeline since it’s a new collection, so we’ll just start the pipeline.

Insert a document into the pos_data collection in mongo:
db.pos_data.insert({"billing_address": {"address1": "478 Avila Village Apt. 671", "address2": "Suite 079", "country": "Niue", "company": "Wang, Day and Sanders", "city": "Heatherton"}, "buyer_accepts_marketing": false, "shopper": {"username": "george12", "name": "Lisa Jones", "birthdate": "1977-12-07", "sex": "F", "address": "14036 Corey Lake\nHendrixbury, OR 70750", "mail": "brianthompson@gmail.com"}, "cart_token": "d76d0e12-de1e-4d8b-980a-6ab892d57a5c", "fulfilment": {"fulfillable_quantity": 1, "total_price": 894.0, "grams": 306.51, "fulfillment_status": "fulfilled", "products": {"sku": "IPOD-342-N", "vendor": "Apple", "product_id": "6981718224312", "title": "IPod Nano", "requires_shipping": 1, "name": "IPod Nano - Pink", "variant_id": 4264112, "variant_title": "Pink", "quantity": 7.498855850621649}, "fulfillment_service": "amazon", "id": "7111705632496"}, "credit_card": {"card_expiry_date": "07/17", "description": "Carlson Group", "transaction_date": "11/29/2016", "purchase_amount": 894.0, "card_security_code": "346", "card_number": "4144406331250819"}})

Check the pipeline in StreamSets Data Collector. It picks up the document from the oplog and inserts it into MapR-DB.
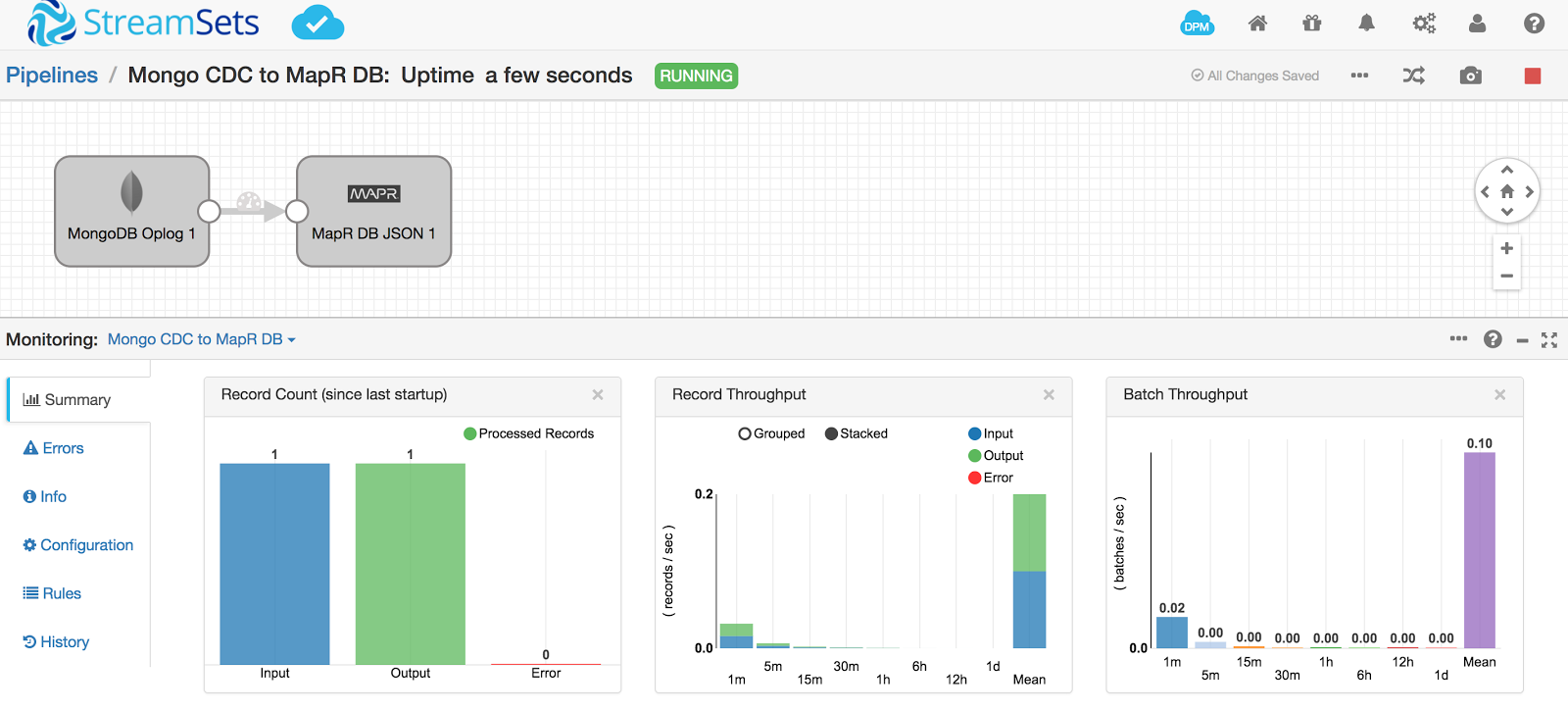
Now, list the tables in mapr dbshell, and you can see that SDC created pos_data table and also inserted the document.
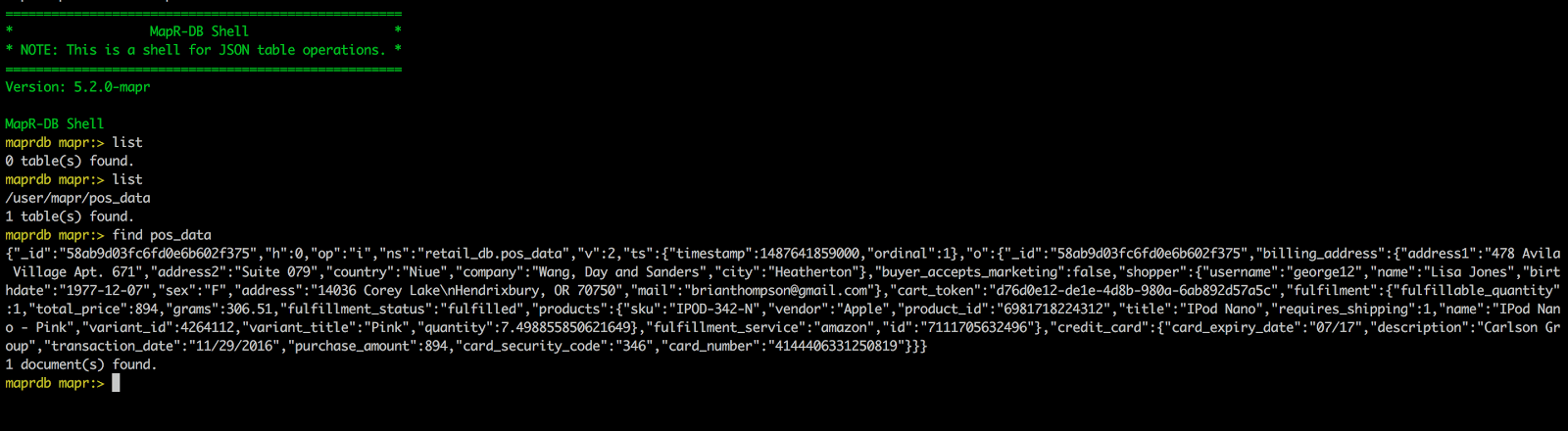
The document inserted is the full transaction log. I only want to insert the original document that is captured in the o attribute. The transaction type is defined by op – it will be automatically handled by the MapR-DB JSON table property ‘Use MapR InsertOrReplace API’. If the same _id is encountered, SDC will replace the document in MapR-DB JSON table, otherwise it will insert the document.
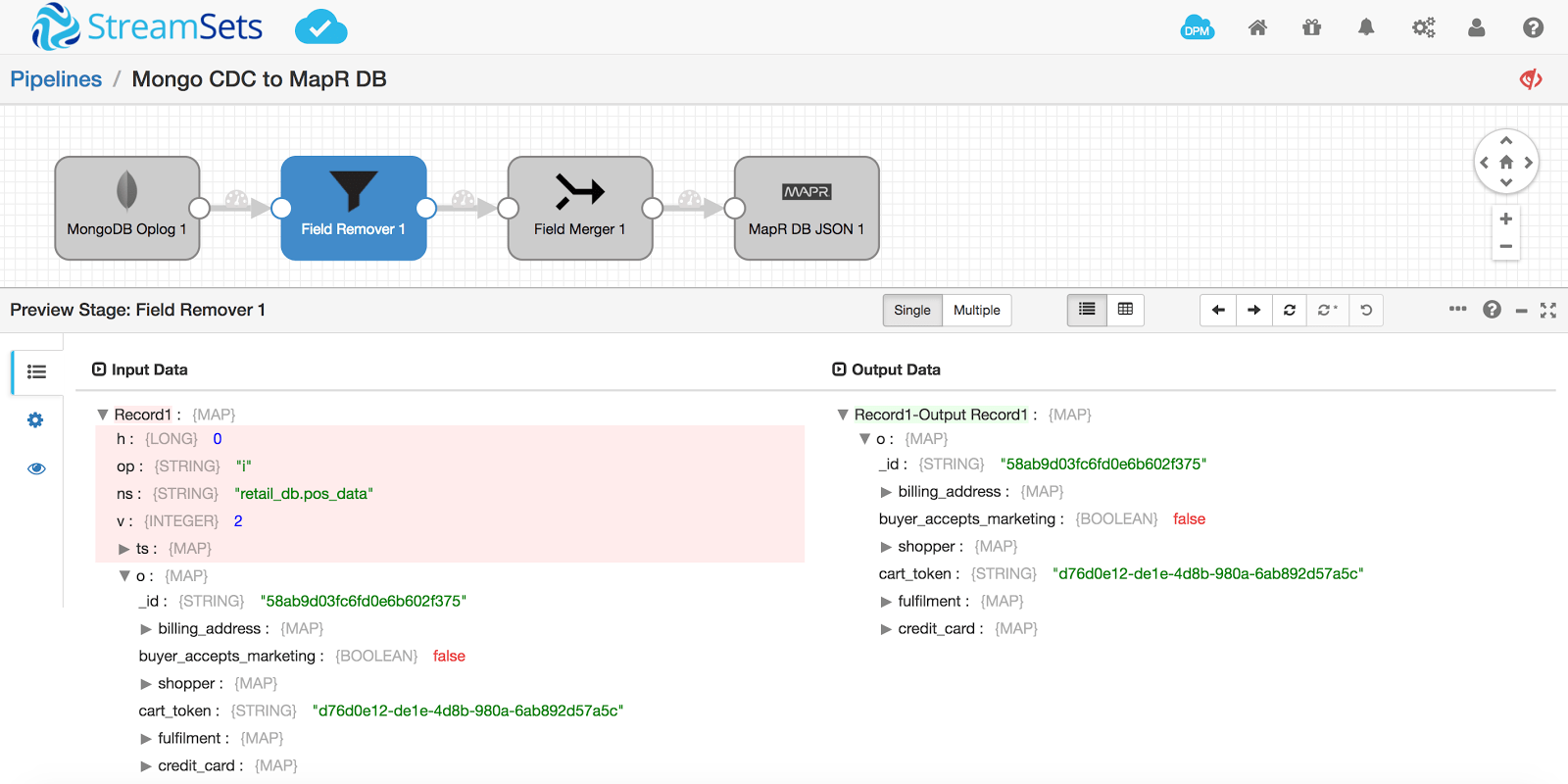
To capture the original document o to insert into the table, add a Field Remover in the pipeline to only keep o as follows:

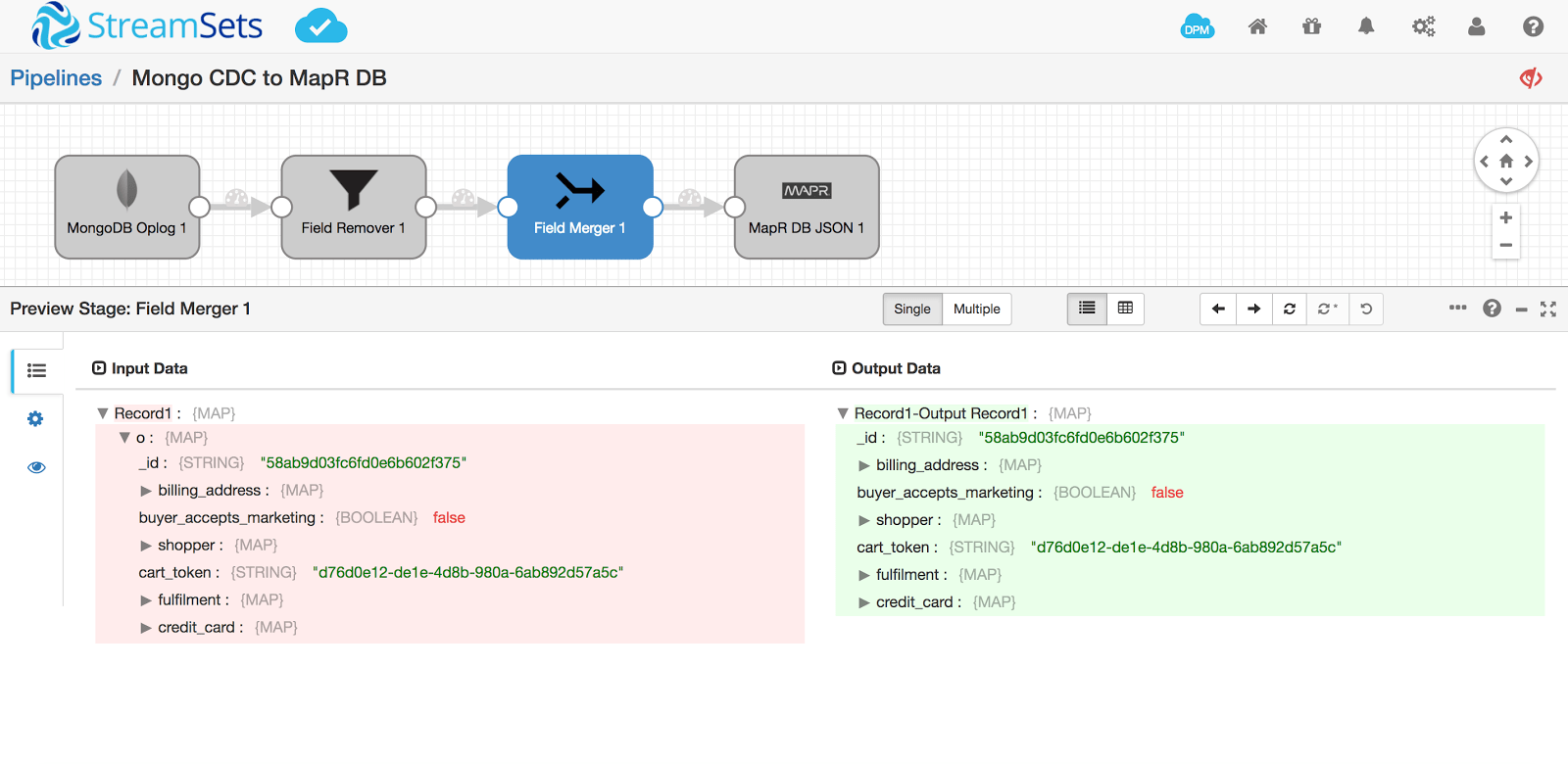
I also added a Field Merger because I don’t want the document to be named o, but instead be the main document.
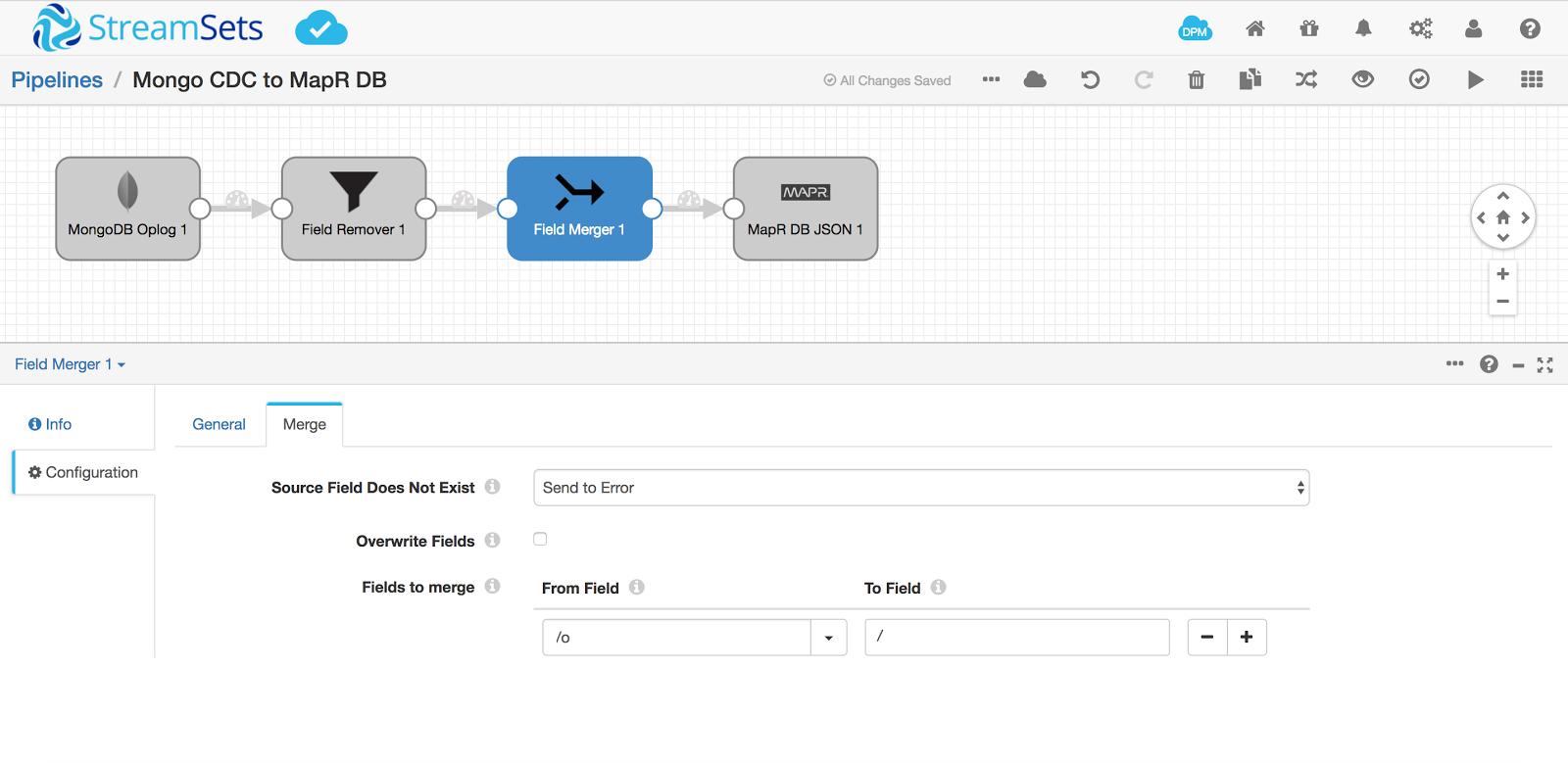
Update the Row Key in the destination to now be /_id as we’ve removed the parent document o
Run a Preview to see what it will look like:
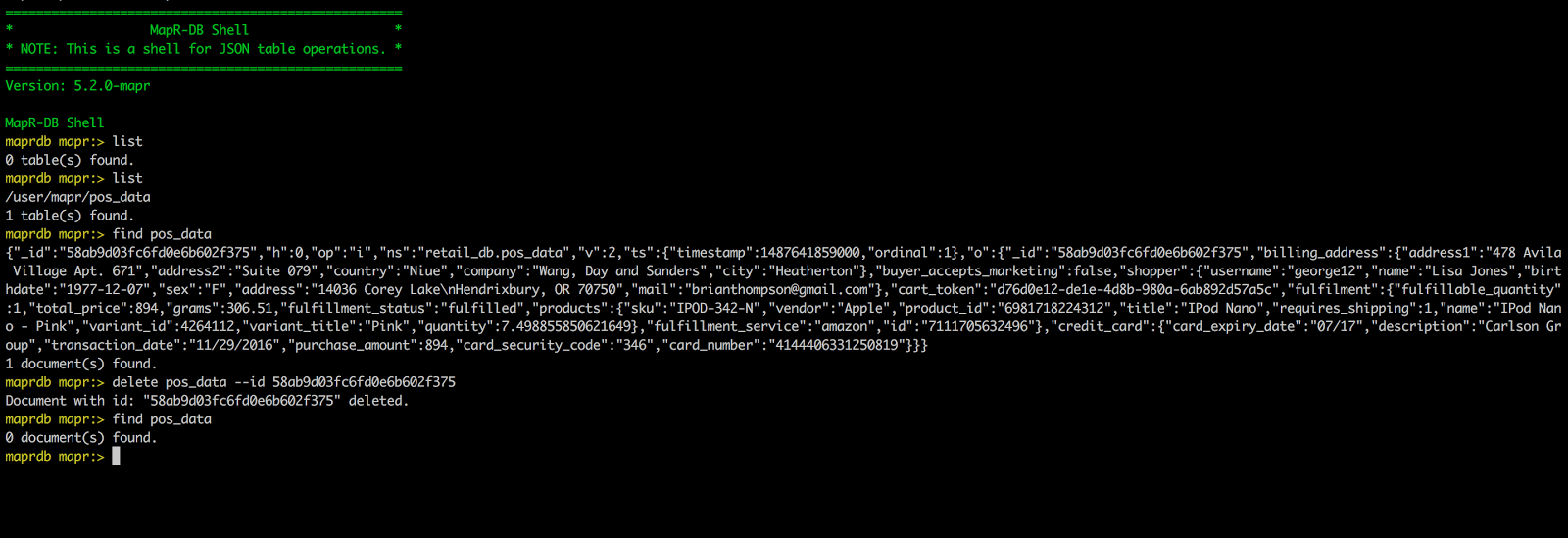
Delete the document from the pos_data table in MapR-DB:
Reset the Origin in the pipeline so that original record is processed again:
Start the pipeline and we should see that one record flowing through.

Query the pos_data table in mapr dbshell and notice how the document is inserted now

Now lets add 3 more documents to the mongo collection pos_data:
db.pos_data.insert({"billing_address": {"address1": "967 Jay Canyon", "address2": "Suite 111", "country": "Singapore", "company": "Bell PLC", "city": "South Kyle"}, "buyer_accepts_marketing": true, "shopper": {"username": "ashleyrussell", "name": "Miguel Cline", "birthdate": "1977-06-01", "sex": "M", "address": "9751 Myers Drive Apt. 650\nScottberg, OH 91053-5987", "mail": "tylerhughes@gmail.com"}, "cart_token": "c03b2b44-a7a8-4670-a411-d5772dcf3e33", "fulfilment": {"fulfillable_quantity": 1, "total_price": 479.31, "grams": 248.47, "fulfillment_status": "fulfilled", "products": {"sku": "IPOD-342-N", "vendor": "Apple", "product_id": "9502805730614", "title": "IPod Nano", "requires_shipping": 1, "name": "IPod Nano - Pink", "variant_id": 4264112, "variant_title": "Pink", "quantity": 3.4824490937721935}, "fulfillment_service": "manual", "id": "4719367439632"}, "credit_card": {"card_expiry_date": "06/17", "description": "Campbell, Kennedy and Lewis", "transaction_date": "11/29/2016", "purchase_amount": 479.31, "card_security_code": "729", "card_number": "5296253772628936"}})
db.pos_data.insert({"billing_address": {"address1": "55581 Swanson Loop Apt. 626", "address2": "Apt. 645", "country": "Guinea-Bissau", "company": "Green, Sullivan and Haney", "city": "Stevensview"}, "buyer_accepts_marketing": false, "shopper": {"username": "gloriacardenas", "name": "Marcus Sanchez", "birthdate": "1996-07-09", "sex": "M", "address": "440 Sanchez Park\nSouth Heidimouth, NE 57720", "mail": "manningdevon@yahoo.com"}, "cart_token": "7893ad04-5b51-4629-b54a-80dd2ed64b28", "fulfilment": {"fulfillable_quantity": 1, "total_price": 48.8, "grams": 412.43, "fulfillment_status": "fulfilled", "products": {"sku": "IPOD-342-N", "vendor": "Apple", "product_id": "0613704736870", "title": "IPod Nano", "requires_shipping": 1, "name": "IPod Nano - Pink", "variant_id": 4264112, "variant_title": "Pink", "quantity": 9.250352450141936}, "fulfillment_service": "manual", "id": "3891348777849"}, "credit_card": {"card_expiry_date": "09/24", "description": "Sweeney, Walsh and Berry", "transaction_date": "02/20/2017", "purchase_amount": 48.8, "card_security_code": "693", "card_number": "5579105578886415"}})
db.pos_data.insert({"billing_address": {"address1": "046 Duncan Knoll Suite 541", "address2": "Apt. 543", "country": "Andorra", "company": "Warren Inc", "city": "Williamshaven"}, "buyer_accepts_marketing": true, "shopper": {"username": "justin56", "name": "Darrell Nguyen", "birthdate": "1995-04-18", "sex": "M", "address": "728 Moore Squares\nPort Danafurt, AZ 93202", "mail": "thomasroberts@yahoo.com"}, "cart_token": "d0989da5-cf6a-4ca2-bcbc-714ff0039128", "fulfilment": {"fulfillable_quantity": 1, "total_price": 190.34, "grams": 383.64, "fulfillment_status": "fulfilled", "products": {"sku": "IPOD-342-N", "vendor": "Apple", "product_id": "4410352990489", "title": "IPod Nano", "requires_shipping": 1, "name": "IPod Nano - Pink", "variant_id": 4264112, "variant_title": "Pink", "quantity": 8.428226968389547}, "fulfillment_service": "fedex", "id": "2771204627833"}, "credit_card": {"card_expiry_date": "02/25", "description": "Johnson, Garcia and Melendez", "transaction_date": "02/20/2017", "purchase_amount": 190.34, "card_security_code": "9523", "card_number": "349693032739718"}})
Have a look at the running pipeline to see the counts increase :
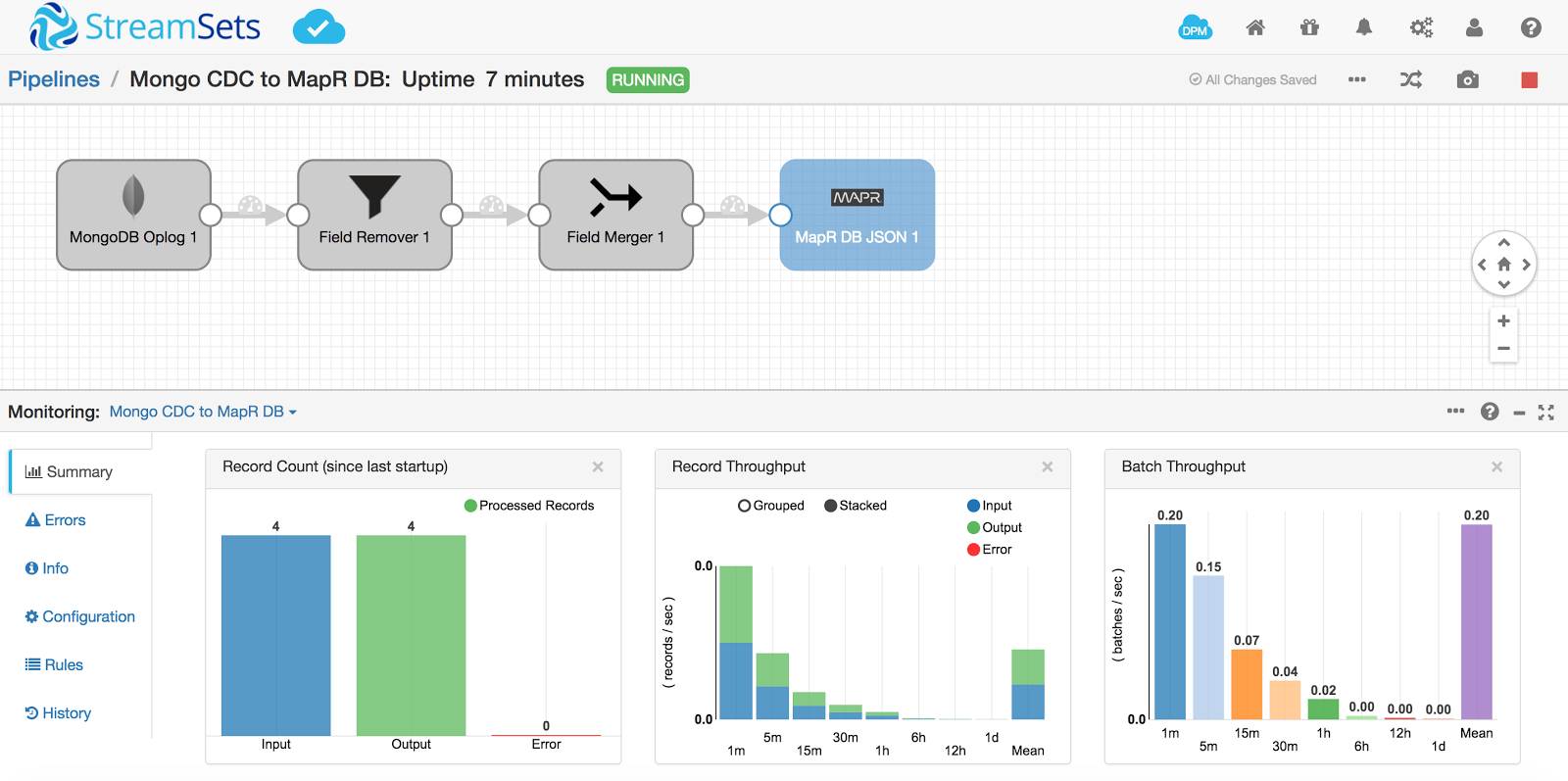
Validate all 4 documents are in the MapR-DB table:
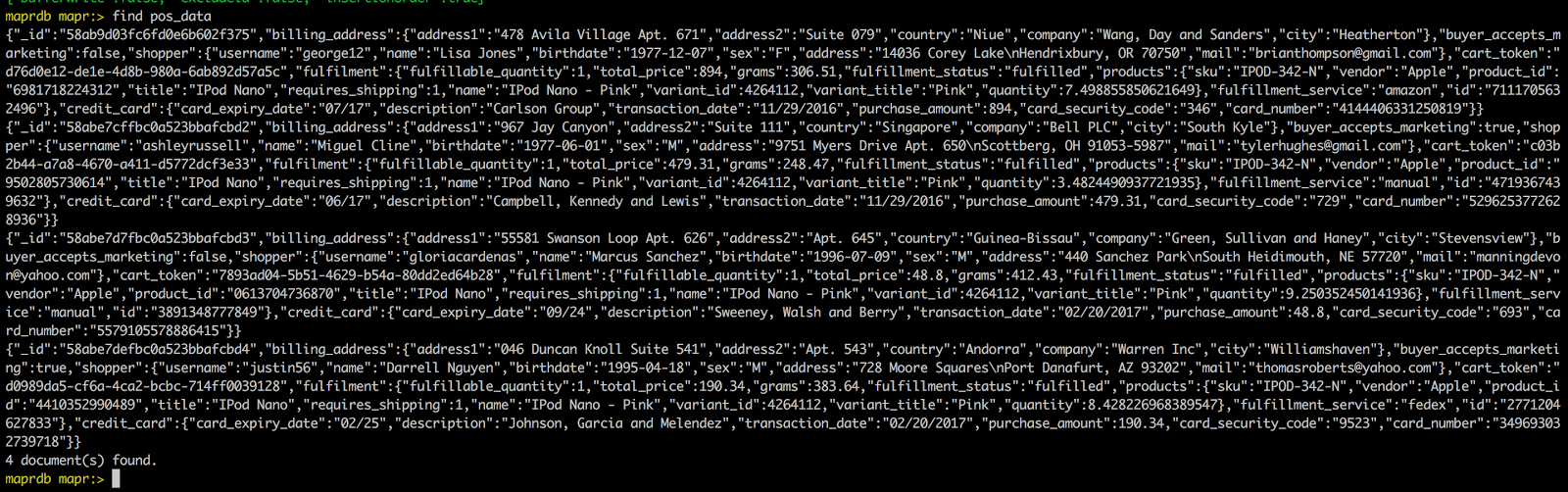
Now, let’s update an existing document in mongo:
db.pos_data.update({"_id":"58abe7cffbc0a523bbafcbd2"},{name: "Rupal", rating: 1},{upsert: true})

Once again, glance at the pipeline to see that the update is also picked up:
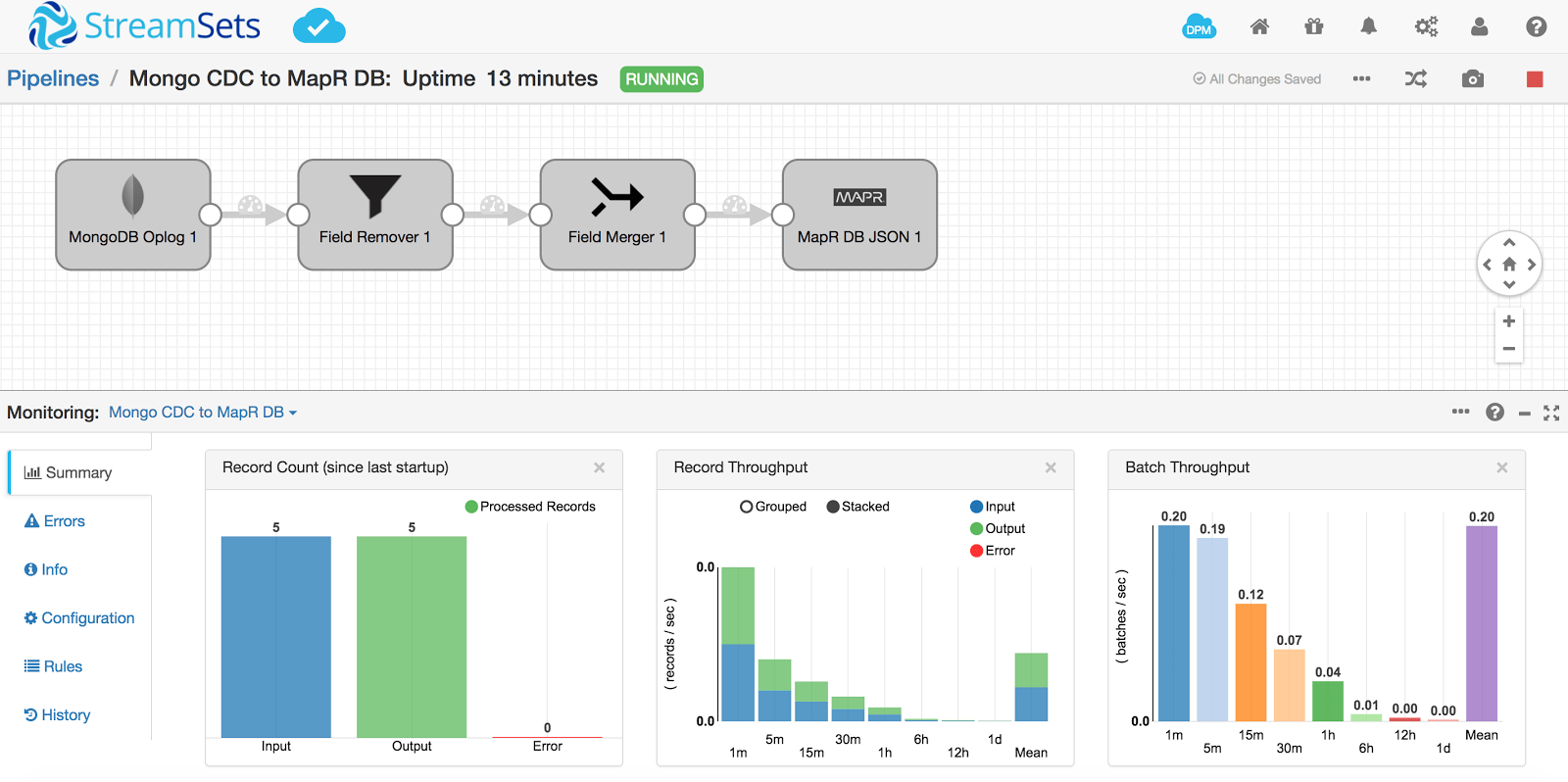
Query MapR-DB table for the same _id, 58abe7cffbc0a523bbafcbd2

The output verifies the Replace logic for the same id without having to do any lookup in the pipeline. The MapR-DB JSON destination handles the check for an existing id.
Tracking all MongoDB databases and collections in a single pipeline
MongoDB oplog captures CDC data for all collections in all the databases. Hence, one can easily create a MapR-DB table per database and per collection by just parameterizing the output table name. The oplog captures the name of the database and collection in the field attribute ns. Replacing the table name in the destination with ${record:value('/ns')} will ensure that each transaction log is routed to the corresponding MapR-DB table matching the database and collection name, keeping both MongoDB and MapR-DB tables in sync.
Adding MapR Streams Destination
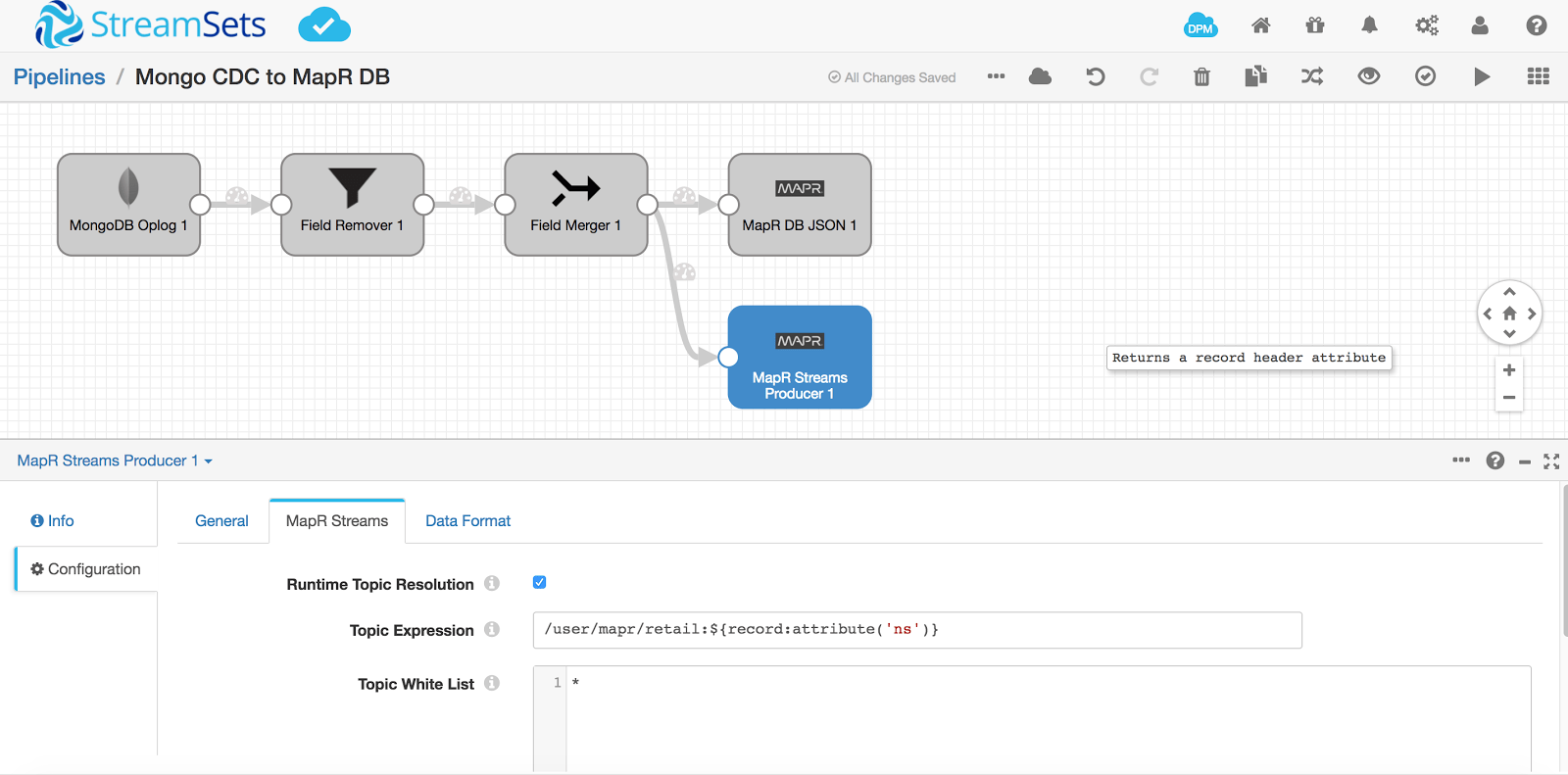
With the above use case, you could also just add a MapR Streams destination so that the same data flows through a topic for downstream processes. The topic name can also be parameterized to correspond to the MongoDB database and collection name as ${record:attribute('ns')}
Reading from a MapR-DB table
Let’s assume that there is an existing MapR-DB table that is being fed by one or more processes and we now want to consolidate this data from the table for other processes downstream. We can easily create a pipeline to read from a MapR-DB JSON table. Here I’ll use the same pos_data table as an example. To query pos_data, add a MapR-DB JSON origin in the pipeline and specify the table name as pos_data.
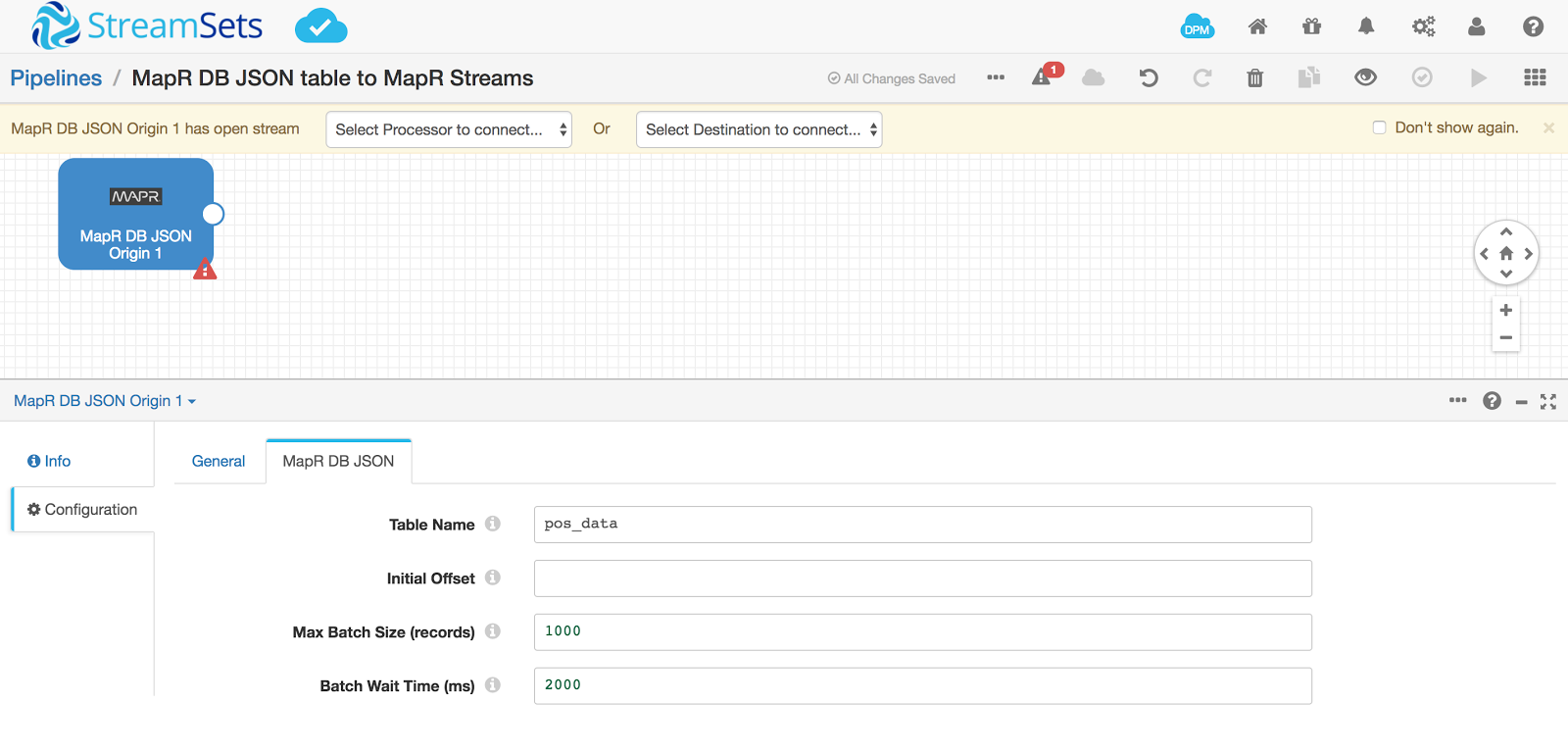
Now we are going to route all this data to MapR Streams so that any downstream applications can get real time data from the pos_data table. To create a MapR Stream, open a terminal that has a MapR client configured for the cluster you want to work with. Issue the following commands to create a stream and a topic:
maprcli stream create retail_stream -path /user/mapr/retail -produceperm p -consumeperm p -topicperm p maprcli stream topic create -topic pos_data -path /user/mapr/retail
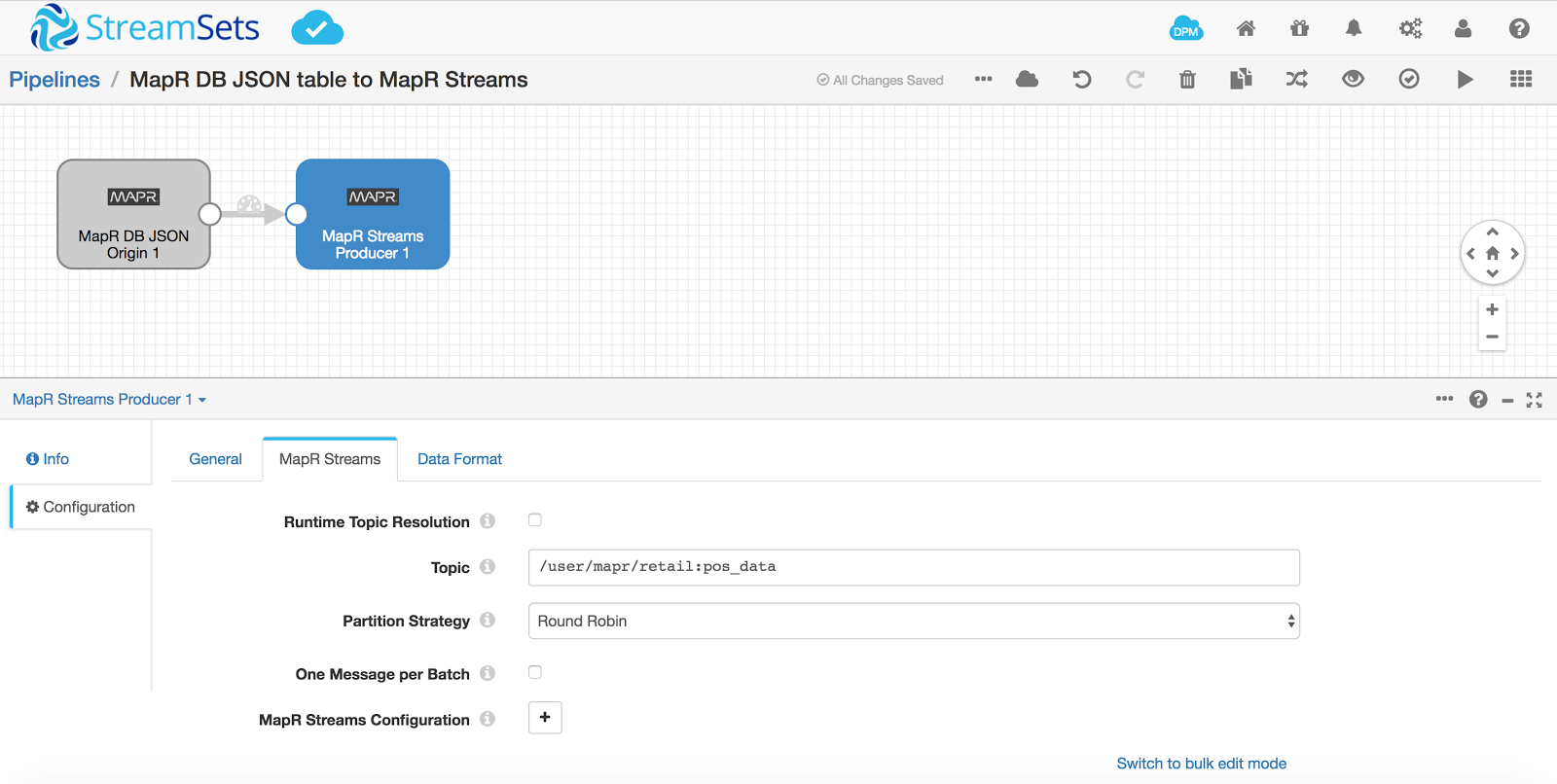
Configure MapR Streams Producer in StreamSets Data Collector pipeline as follows and validate the pipeline:
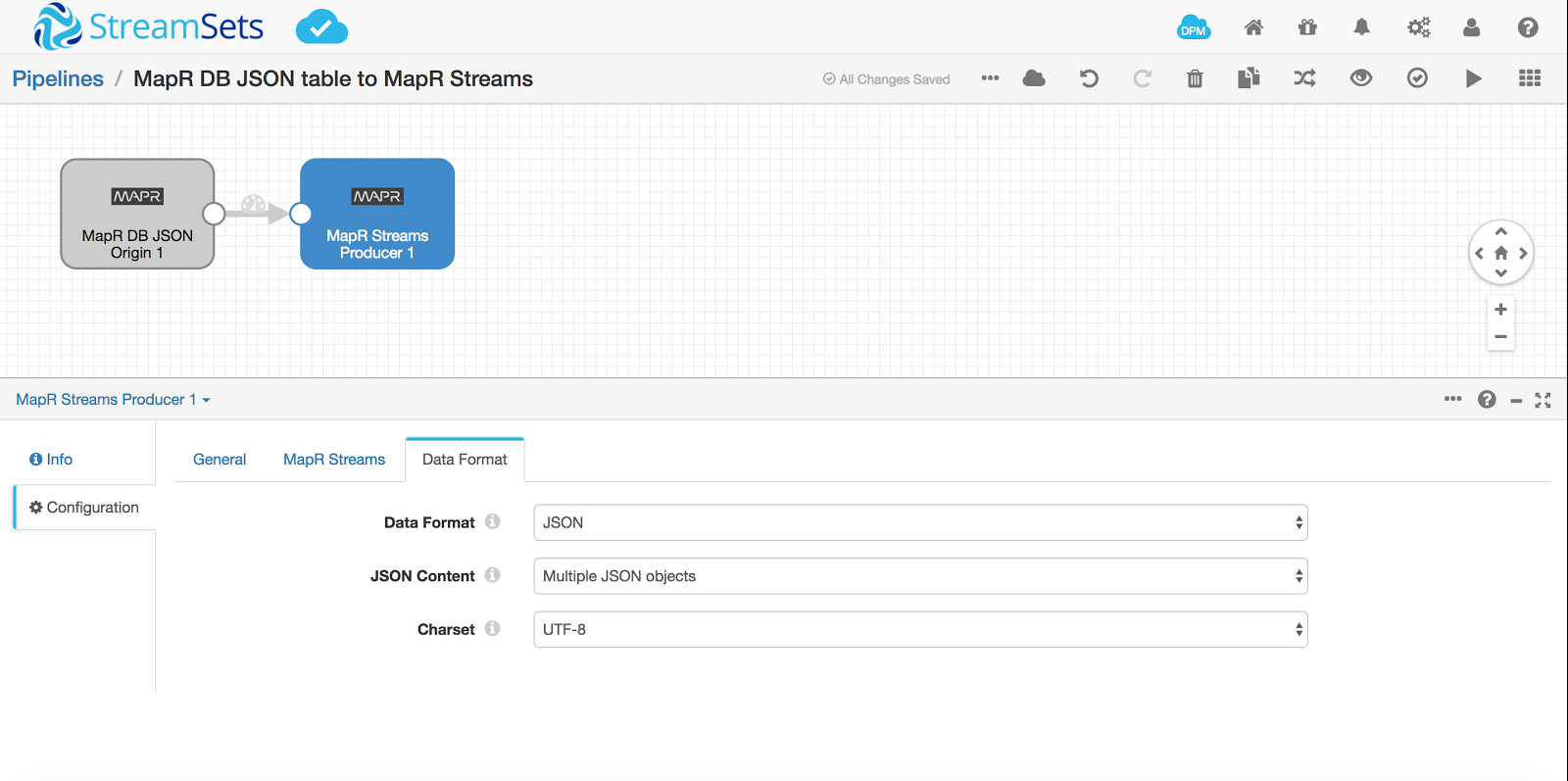
You can choose to write the data in any data format in MapR Streams topic. Here we have selected JSON as the data format
Run a preview to ensure we’re getting data from the table:
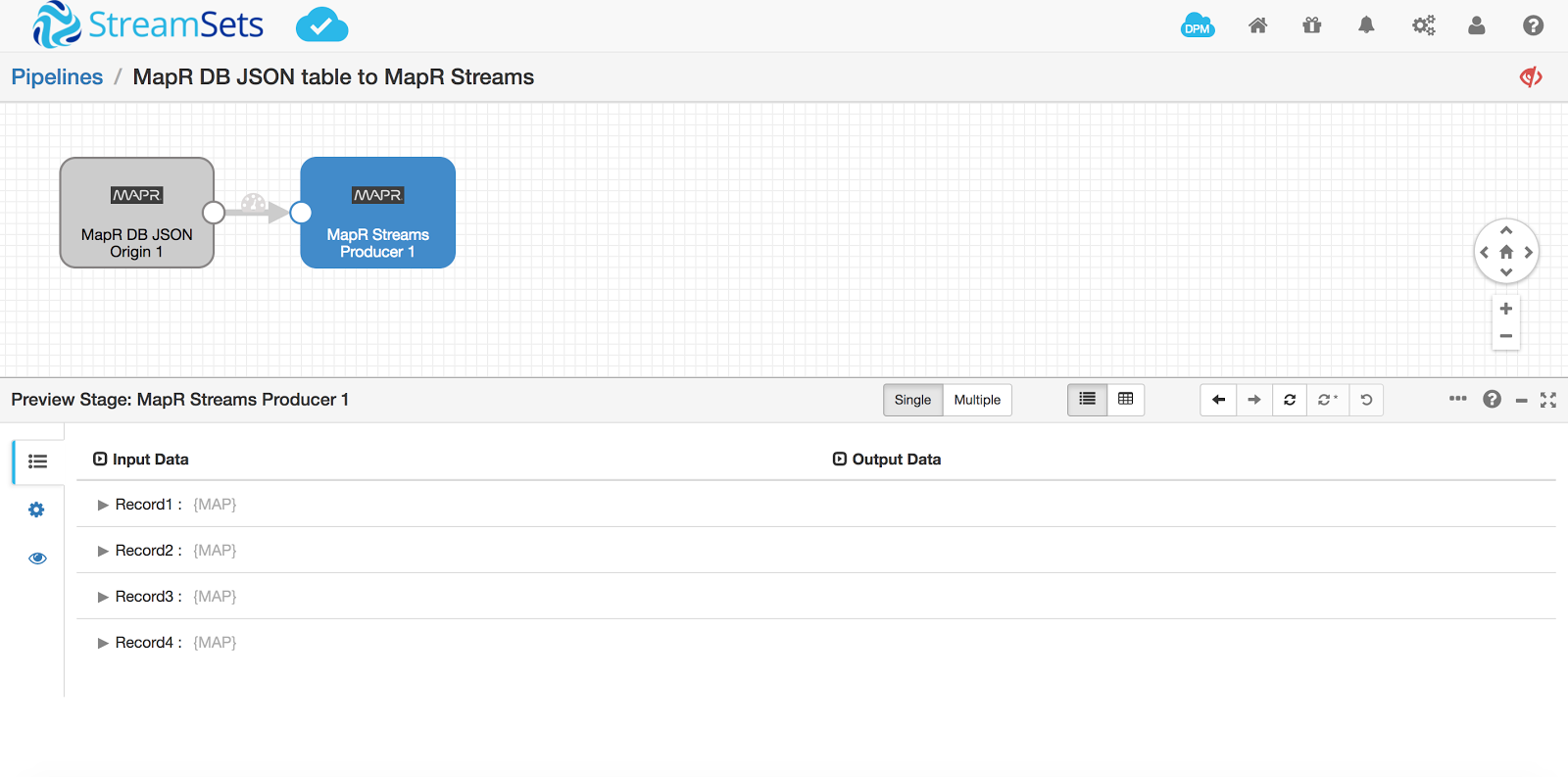
All looks good so I start the pipeline and see all 4 records streaming through
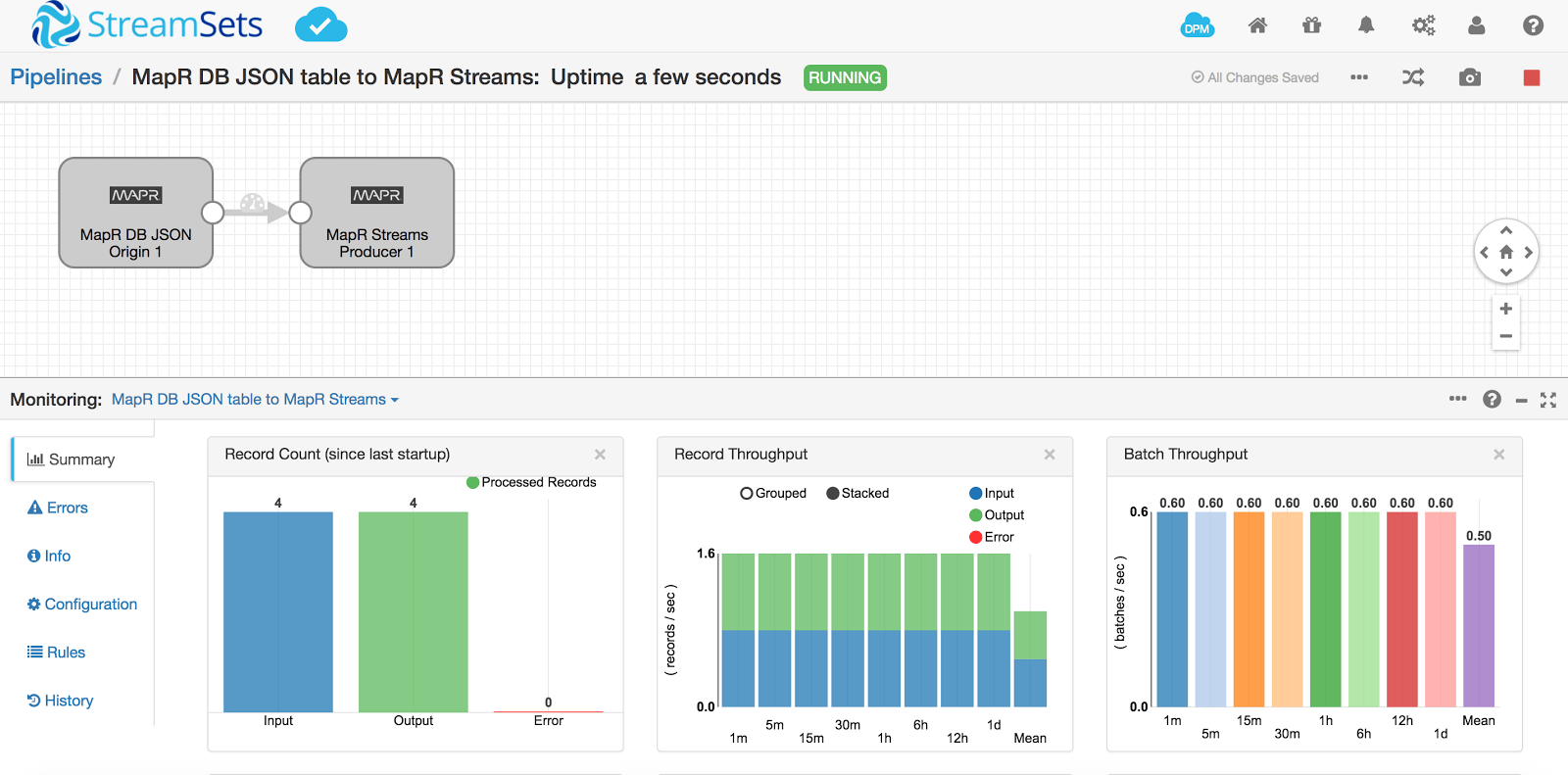
To validate the records in MapR Streams for pos_data topic, issue the following command:
mapr streamanalyzer -path /user/mapr/retail -topics pos_data

Conclusion
StreamSets Data Collector makes it easy to ingest data both from any source into MapR-DB document store and out of the MapR-DB document store for downstream applications without writing a single line of code. It also allows easy ingestion from external document stores keeping the document store in the MapR Hadoop system in sync.
StreamSets Data Collector is fully open source. Feel free to try this out for yourself using a MapR Sandbox or even with your own MapR cluster. Click here to learn more about StreamSets and MapR integration.