![]() New in StreamSets Data Collector (SDC) 2.2.0.0 is the Spark Evaluator, a processor stage that allows you to run an Apache Spark application, termed a Spark Transformer, as part of an SDC pipeline. With the Spark Evaluator, you can build a pipeline to ingest data from any supported origin, apply transformations, such as filtering and lookups, using existing SDC processor stages, and have the Spark Evaluator hand off the data to your Java or Scala code as a Spark Resilient Distributed Dataset (RDD). Your Spark Transformer can then operate on the records, creating an output RDD, which is passed through the remainder of the pipeline to any supported destination.
New in StreamSets Data Collector (SDC) 2.2.0.0 is the Spark Evaluator, a processor stage that allows you to run an Apache Spark application, termed a Spark Transformer, as part of an SDC pipeline. With the Spark Evaluator, you can build a pipeline to ingest data from any supported origin, apply transformations, such as filtering and lookups, using existing SDC processor stages, and have the Spark Evaluator hand off the data to your Java or Scala code as a Spark Resilient Distributed Dataset (RDD). Your Spark Transformer can then operate on the records, creating an output RDD, which is passed through the remainder of the pipeline to any supported destination.
The Spark Evaluator is particularly suited for CPU-intensive tasks, such as sentiment analysis, or image classification, as it can partition batches of records and execute your code in several parallel threads. A new tutorial, Creating a StreamSets Spark Transformer, explains the details, and walks you through a simple example, computing the issuing network of a credit card given its number.
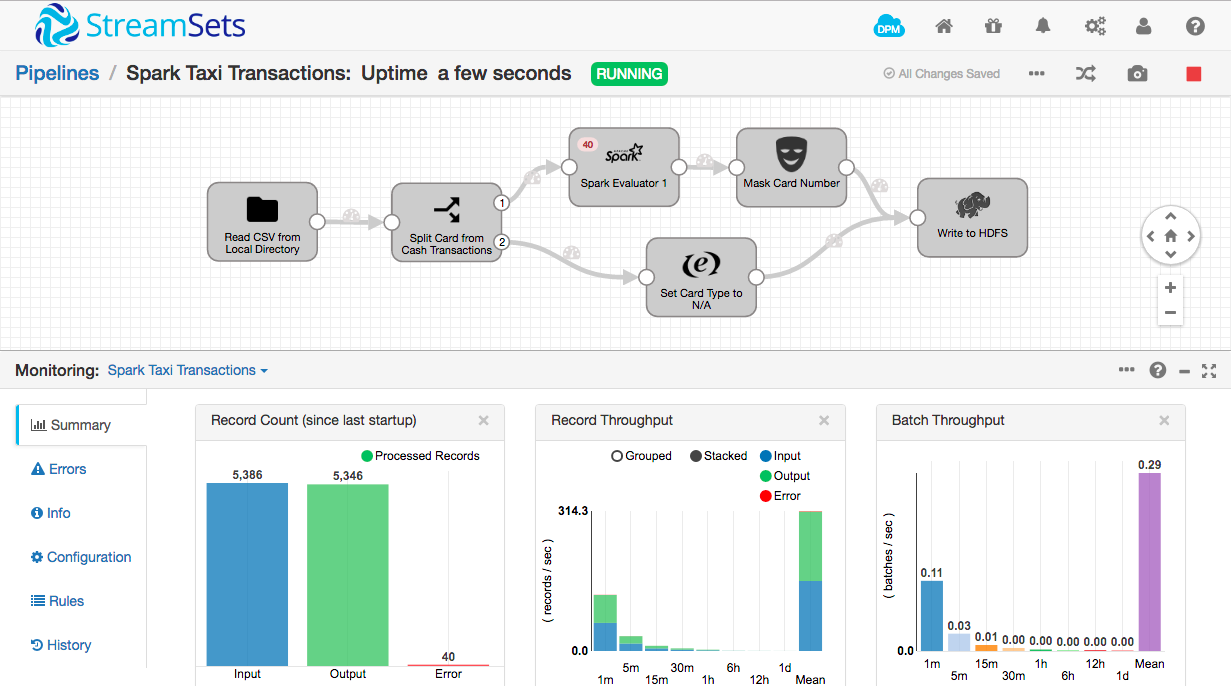
In this first implementation, SDC runs Spark in ‘local-mode’, within its own process, but we are working on a cluster-mode implementation. I recently presented a session, Building Data Pipelines with Spark and StreamSets, at Spark Summit Europe 2016. Watch the video to get a closer look at the Spark Evaluator in action, and our Spark roadmap: