A key aspect of StreamSets Data Collector Engine is its ability to parse incoming data, giving you unprecedented flexibility in processing data flows. Sometimes, though, you don’t need to see ‘inside’ files – you just need to move them from a source to one or more destinations. The StreamSets Platform will include a new ‘Whole File Transfer’ feature for data ingestion In this blog entry I’ll explain everything you need to know to be able to get started with Whole File Transfer, today!
Downloading and Installing Nightly Builds
Update: No more nightly builds! You can now access all versions of StreamSets Data Collector by creating a free StreamSets Account.
Downloading and installing a nightly SDC builds is easy. The latest nightly artifacts are always at http://nightly.streamsets.com/latest/tarball/ and, currently, streamsets-datacollector-all-1.6.0.0-SNAPSHOT.tgz contains all of the stages and their dependencies.
Installing the nightly is just like installing a regular build. In fact, since this is a nightly build, rather than a release that you might be putting into production, you will probably want to just use the default directory locations and start it manually, so all you need to do is extract the tarball, cd into its directory and launch it:
$ tar xvfz streamsets-datacollector-all-1.6.0.0-SNAPSHOT.tgz x streamsets-datacollector-1.6.0.0-SNAPSHOT/LICENSE.txt x streamsets-datacollector-1.6.0.0-SNAPSHOT/NOTICE.txt x streamsets-datacollector-1.6.0.0-SNAPSHOT/ ... $ cd streamsets-datacollector-1.6.0.0-SNAPSHOT/ $ bin/streamsets dc Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256m; support was removed in 8.0 objc[13032]: Class JavaLaunchHelper is implemented in both /Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/bin/java and /Library/Java/JavaVirtualMachines/jdk1.8.0_73.jdk/Contents/Home/jre/lib/libinstrument.dylib. One of the two will be used. Which one is undefined. Running on URI : 'http://192.168.56.1:18630'
Whole File Transfer Data Ingestion
Whole File Transfer can read files from the Amazon S3 and Directory sources, and write them to the Amazon S3, Local FS and Hadoop FS Destinations. In this mode, files are treated as opaque blobs of data, rather than being parsed into records. You can transfer PDFs, text files, spreadsheets, whatever you like. SDC processors can act on the file’s metadata – its name, size, etc – but not the file content.
As an example, let’s imagine I have some set of applications writing a variety of files to an S3 bucket. I want to download them, discard any that are less than 2MB in size, and write the remainder to local disk. I want PDF files to be written to one directory and other content types written to another. Here’s how I built an SDC pipeline to do just that.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Reading Whole Files From Amazon S3
Configuring an S3 Origin for Whole File Transfer was almost identical to configuring it for reading records – the only difference being the Data Format: Whole File.
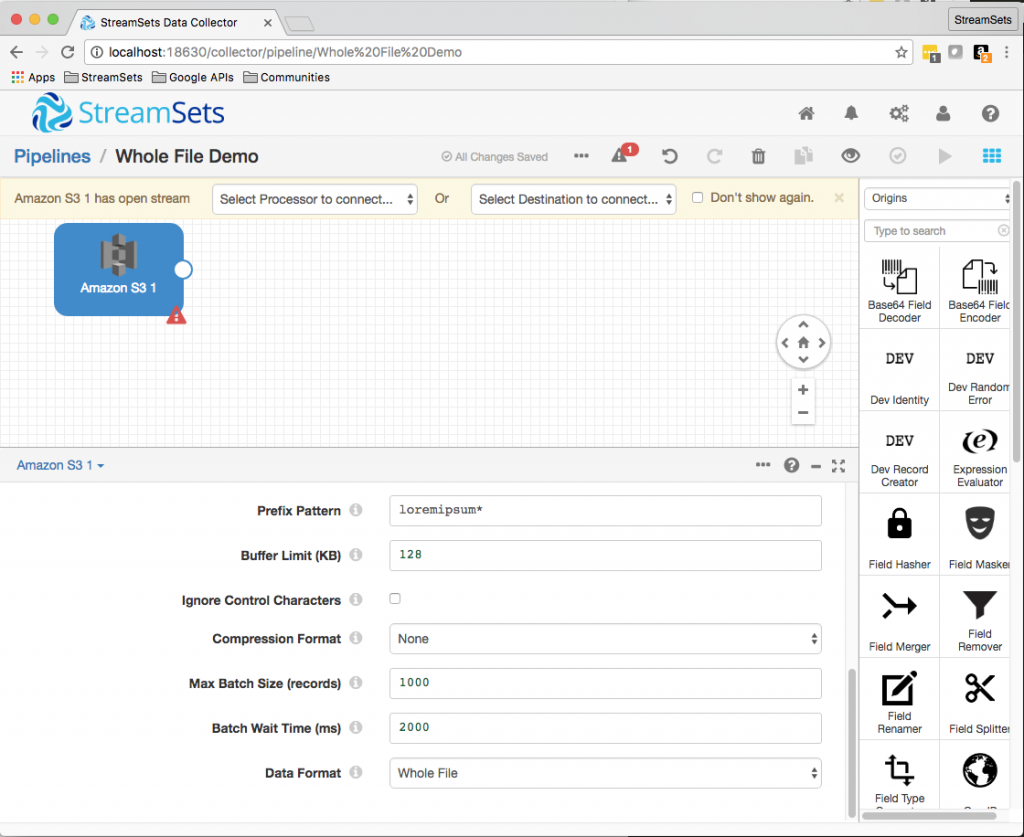
A quick preview revealed that the origin creates fileRef and fileInfo fields:
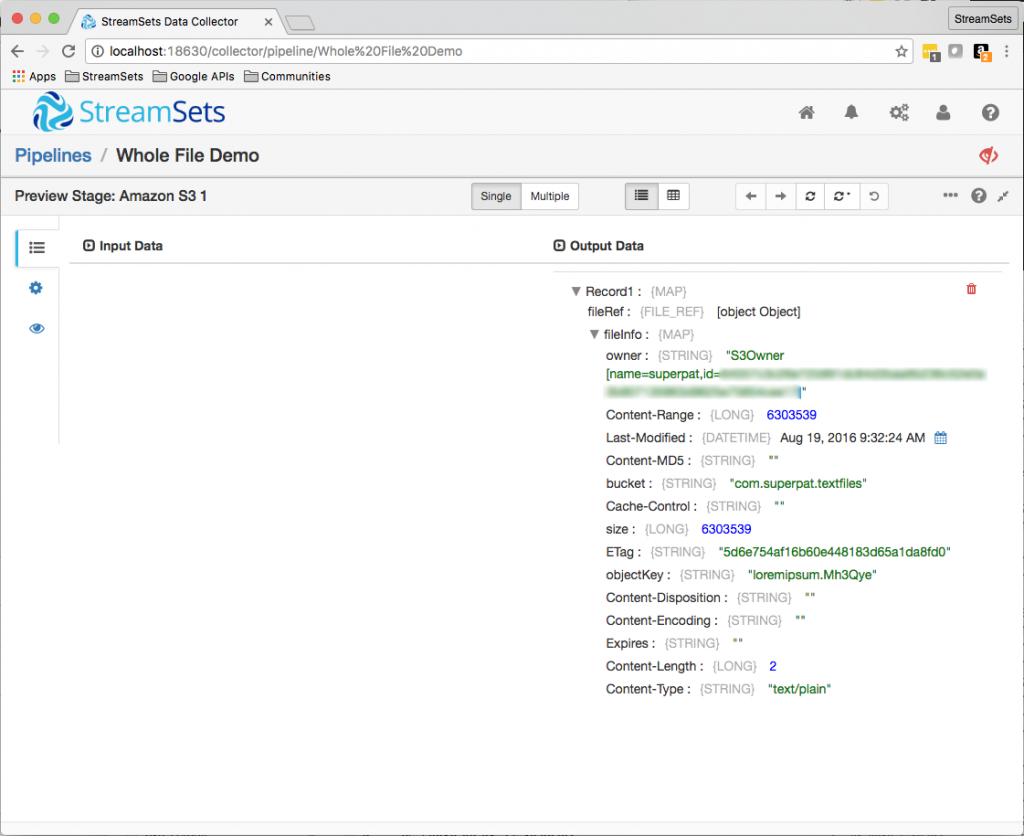
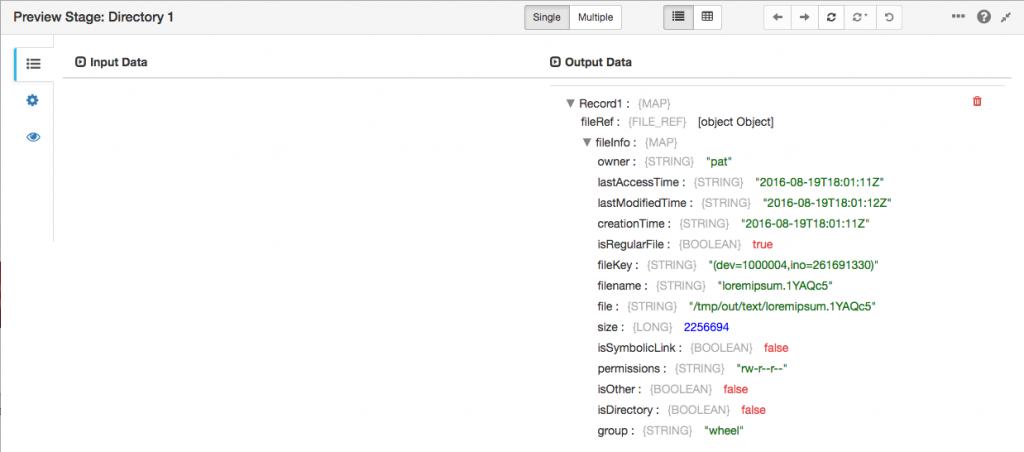
/fileRef contains the actual file data, and is not currently accessible to stages, except for being passed along and written to destinations. /fileInfo contains the file’s metadata, including its name (in the objectKey subfield), size and content type. Note that different origins will set different fields – the Directory origin uses filename, rather than objectKey, and provides a number of other filesystem-specific fields:
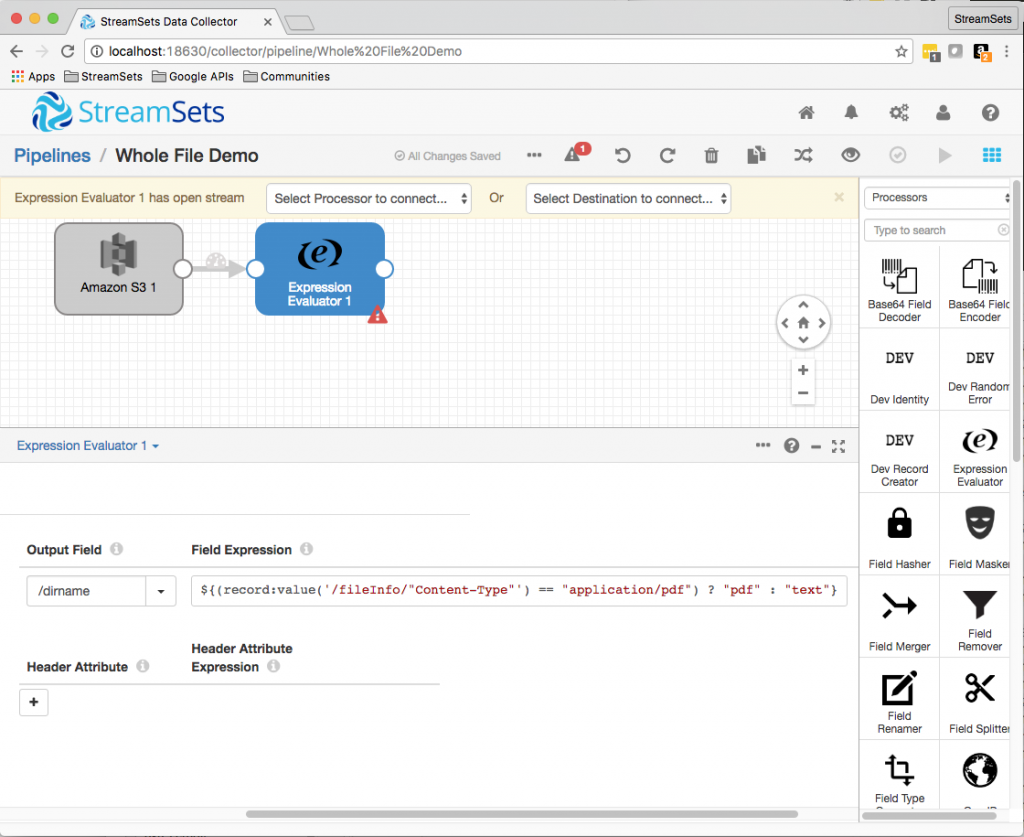
Processing Whole Files with StreamSets Data Collector
Processors can operate on any of the file’s fields, with the exception of fileRef. I used an Expression Evaluator to set a /dirname field to pdf or text depending on the value of /fileInfo/"Content-Type":
If I was working with more than two content types, I could have used a Static Lookup, or even one of the scripting processors, to do the same job.
Stream Selector allowed me to send files to different destinations based on their size:
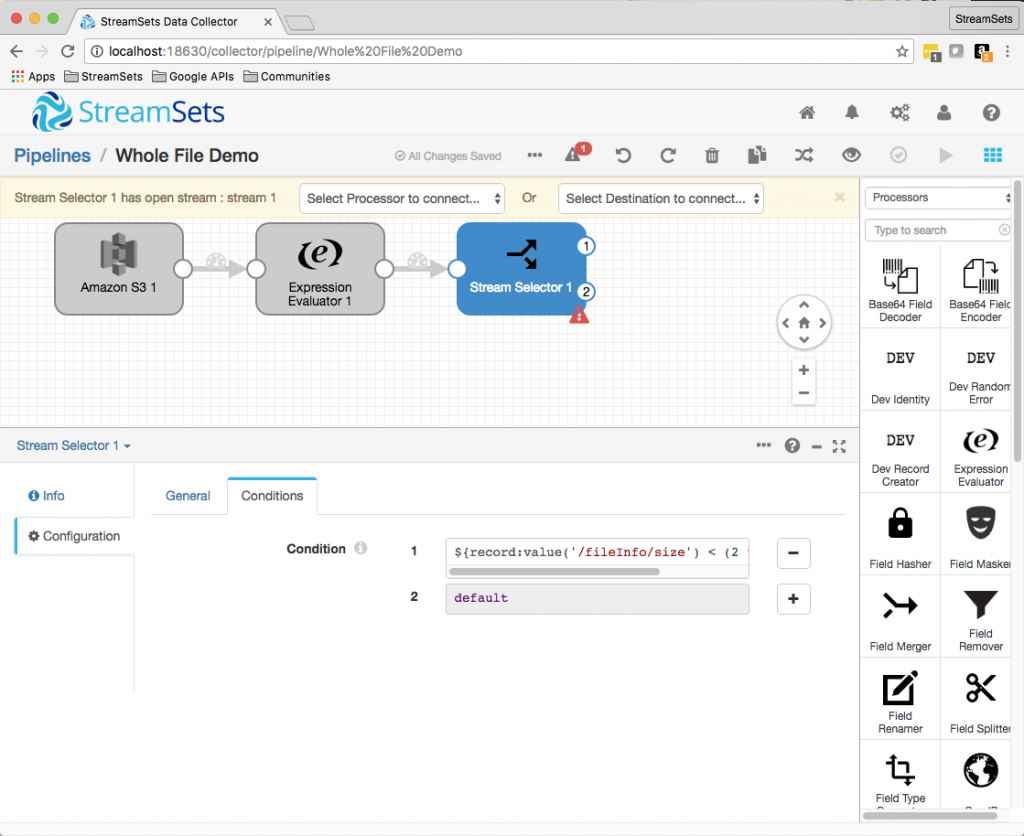
Writing Whole Files to a Destination
I could have written files to S3 or HDFS, but, to keep things simple, I wrote them to local disk. There are some rules to configuring the destination for Whole File Transfer:
- Max Records in File must be 1 – the file is considered to be a single record
- Max File Size must be 0 – meaning that there is no limit to the size of file that will be written
- Idle Timeout must be -1 – files will be closed immediately their content is written
I used the /dirname field in the Local FS destination’s Directory Template configuration to separate PDFs from text files:
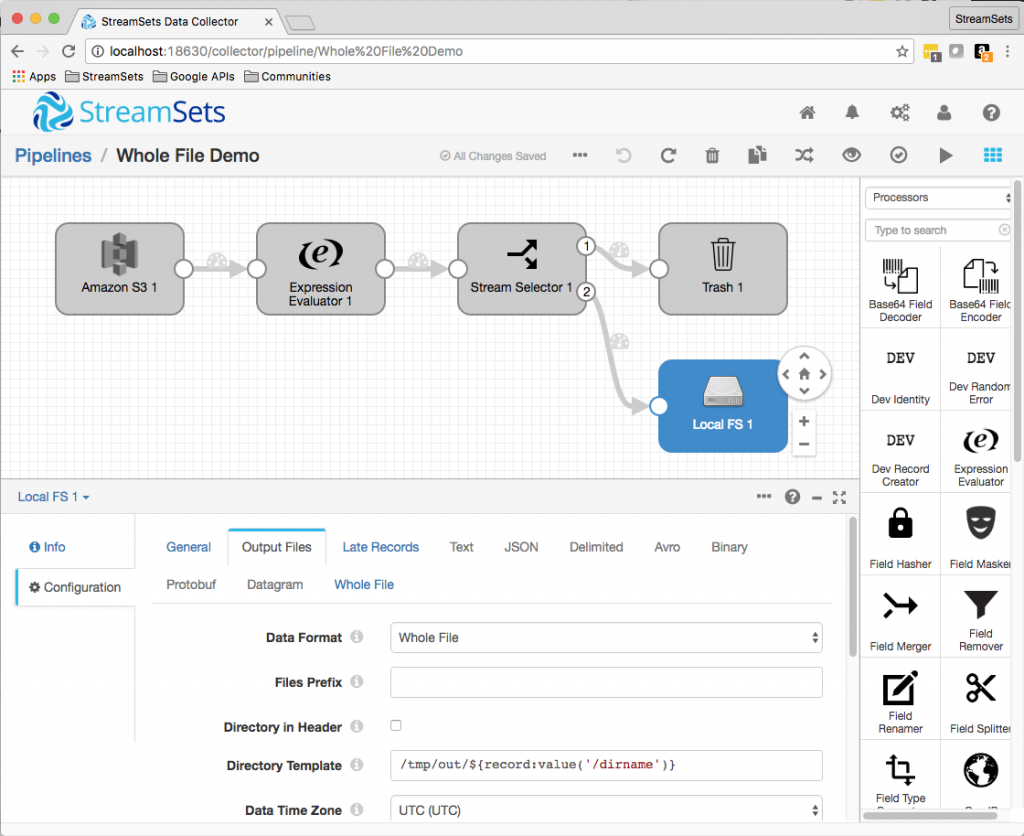
In the new Whole File tab, I set File Name Expression to ${record:value('/fileInfo/objectKey')} to pass the S3 file name on to the file on disk.
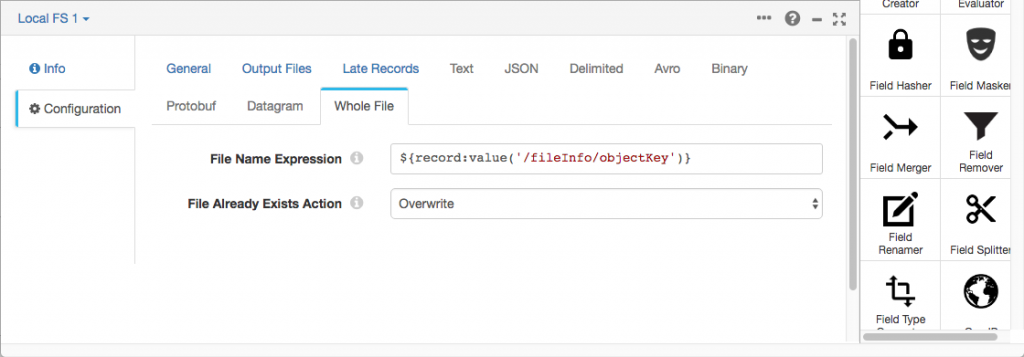
Running a Whole File Transfer Pipeline
Now it was time to run the pipeline and see files being processed! Once the pipeline was running, clicking on the Stream Selector revealed the number of ‘small’ files being discarded, and ‘big’ files being written to local disk.
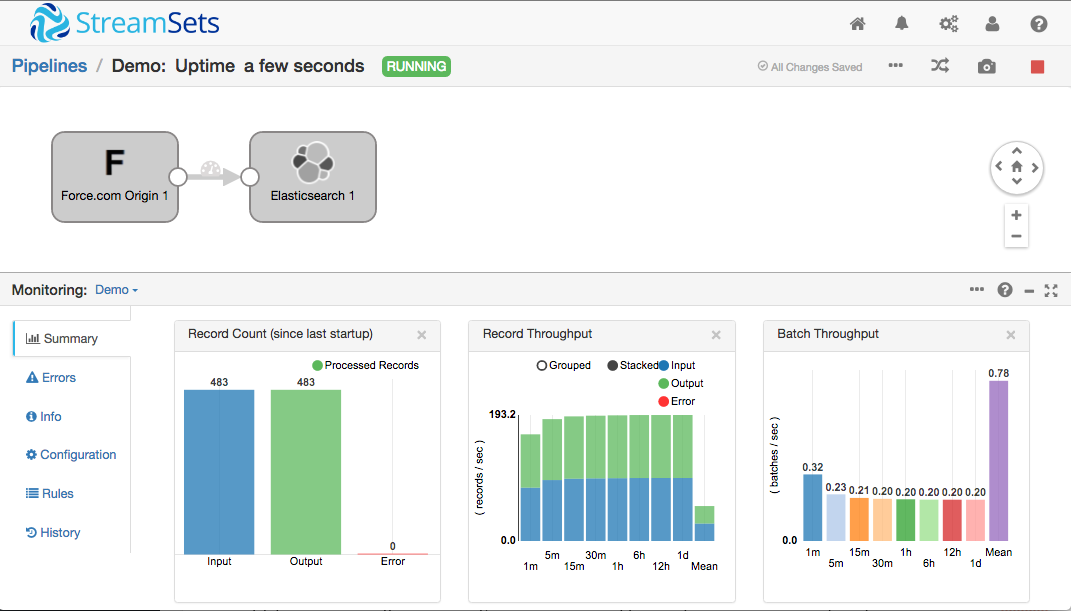
Clicking the Local FS destination showed me the new File Transfer Statistics monitoring panel:
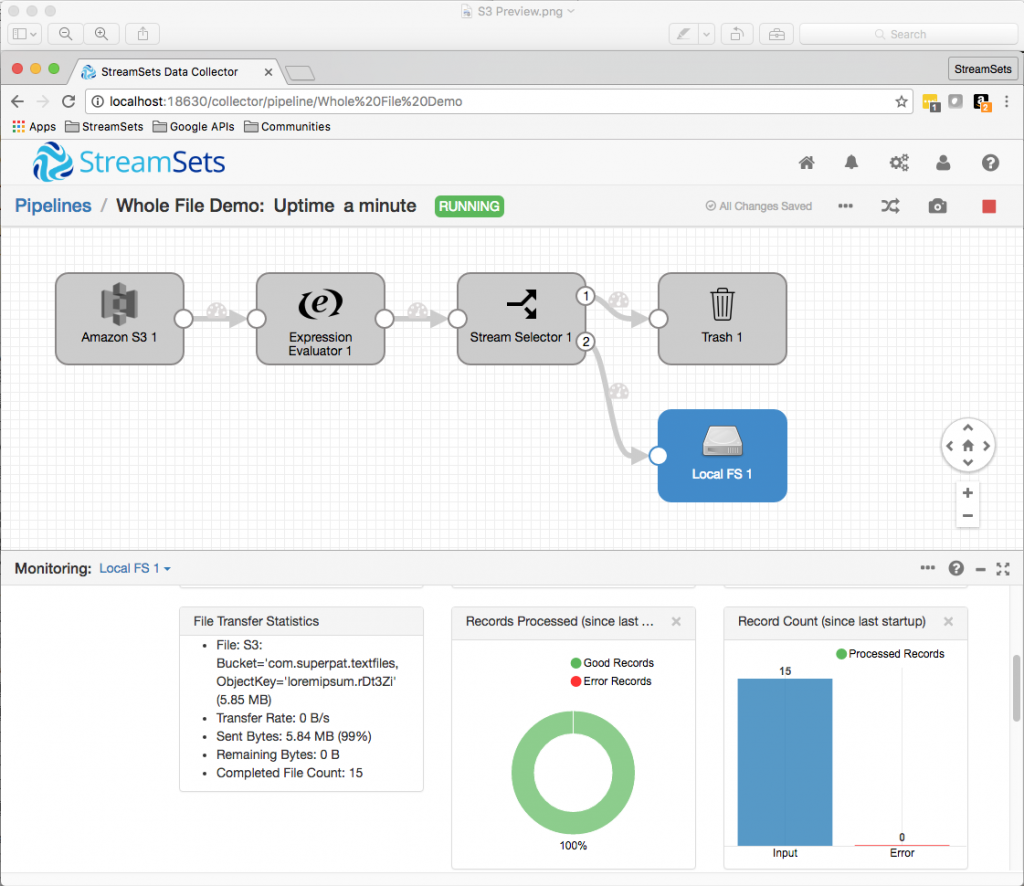
Checking the output directory:
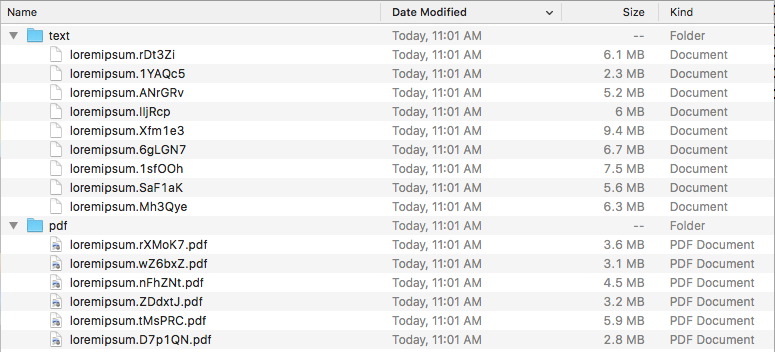
Success! Since Data Collector runs pipelines continuously, I was even able to write more files to the S3 bucket and see them being processed and written to the local disk.
Conclusion
StreamSets Data Collector Engines’s new Whole File Transfer feature allows you to build pipelines to transfer opaque file data from S3 or Local FS origins to S3, Local FS or Hadoop FS destinations. File metadata is accessible to processor stages, enabling you to build pipelines that send data exactly where it is needed. Create an account and try it out!