Set Up and Run Data Pipelines
How to get the most out of the StreamSets data integration platform.
Run Your First Pipeline in Minutes
All the data integration functionality our users love is now available in a fully managed, cloud-native platform.
- Log in to StreamSets.
- Launch a deployment with a Data Collector or Transformer engine.
- Build a pipeline by defining endpoints and processing requirements.
- Define and configure a job to run your first pipeline.
- Monitor the health and performance of your job, and system consumption.
Need Help Getting Started?
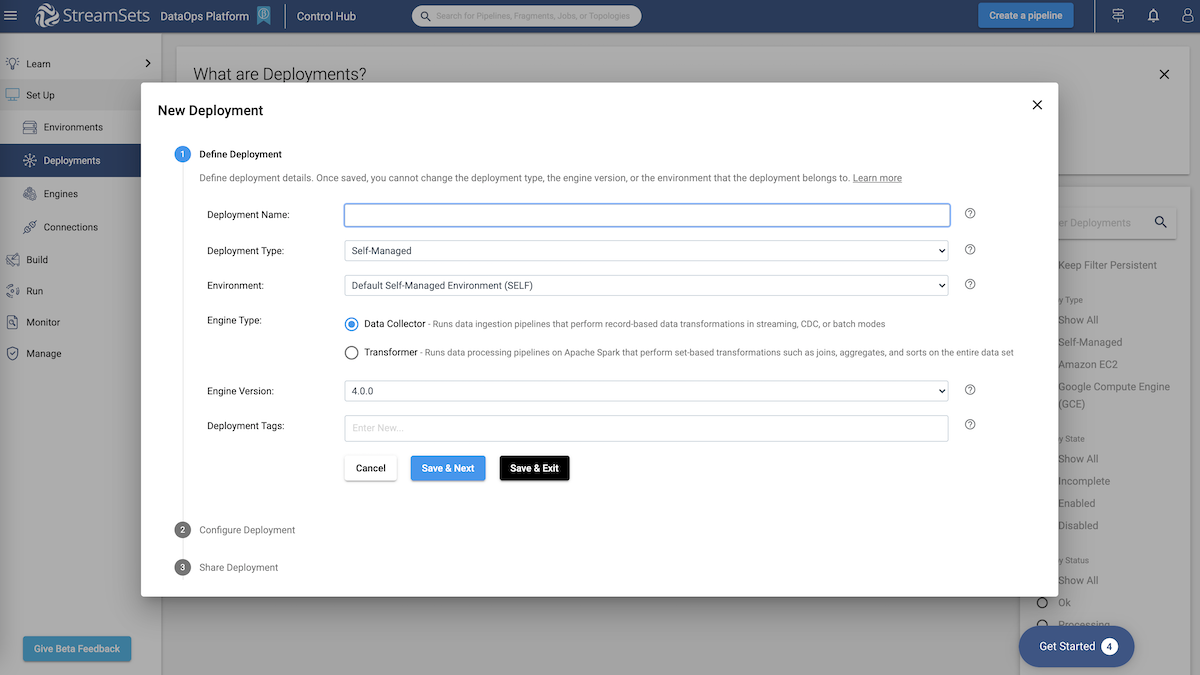
How to launch a deployment and define your StreamSets engine, version, and configuration.
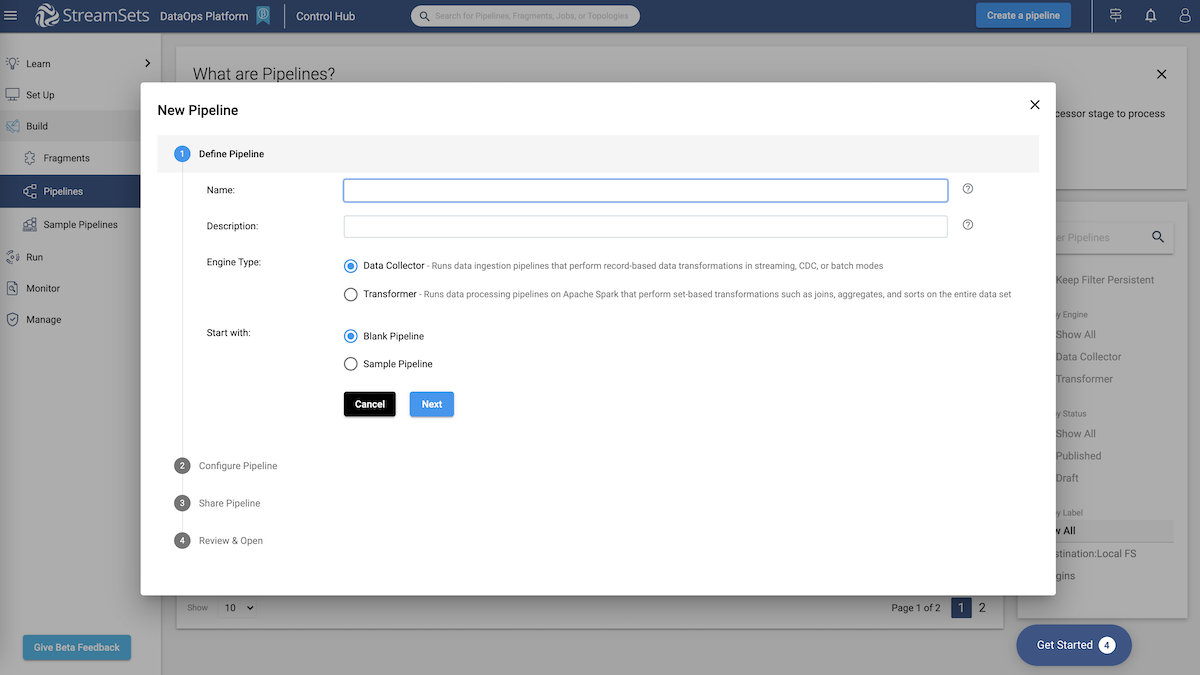
Easy as 1-2-3, just drag and drop commonly used endpoints and pre-built processors.
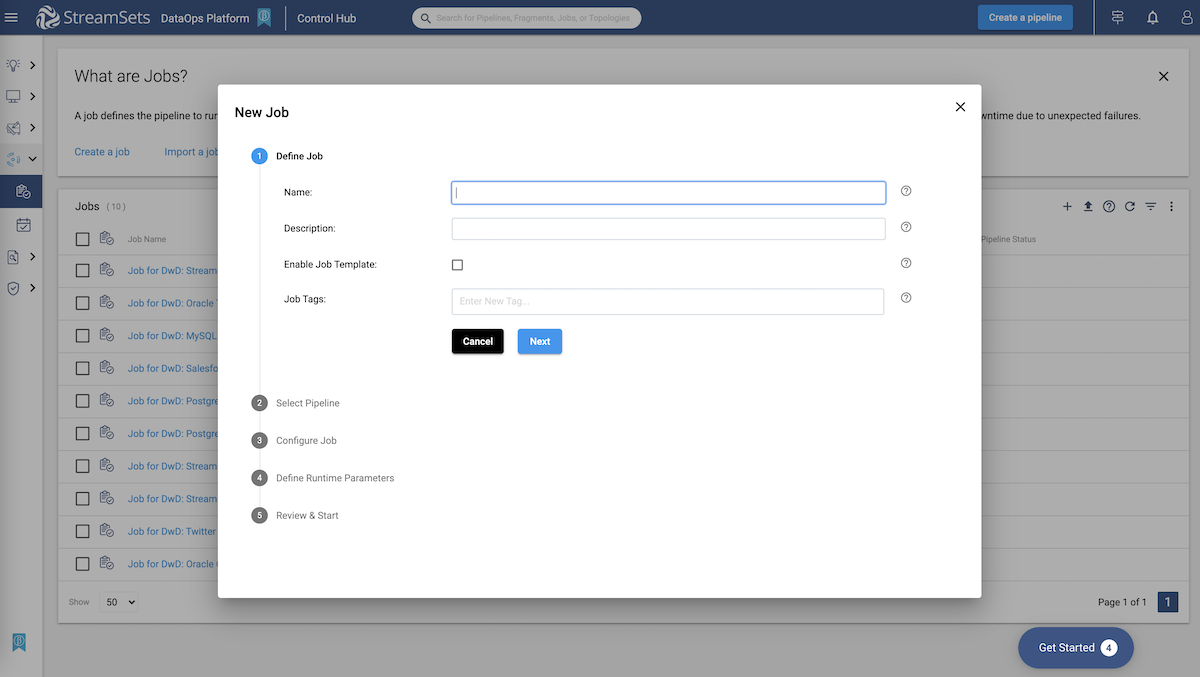
Ready, set, go! Preview your pipeline and configure a job to start processing.
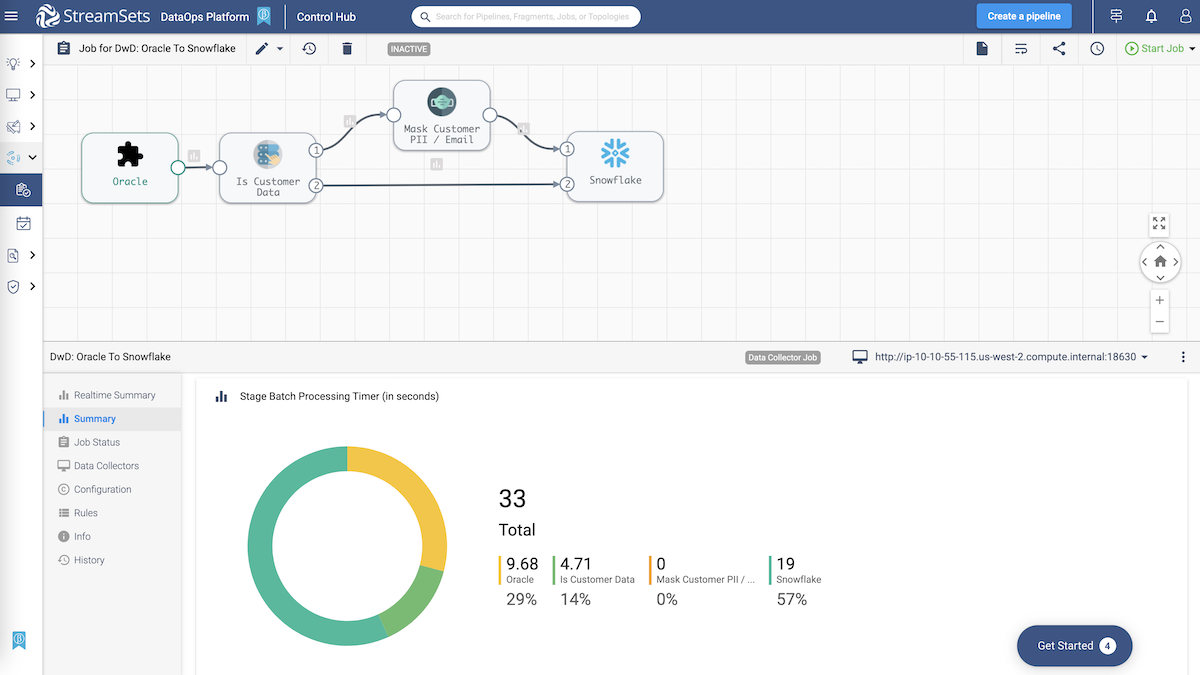
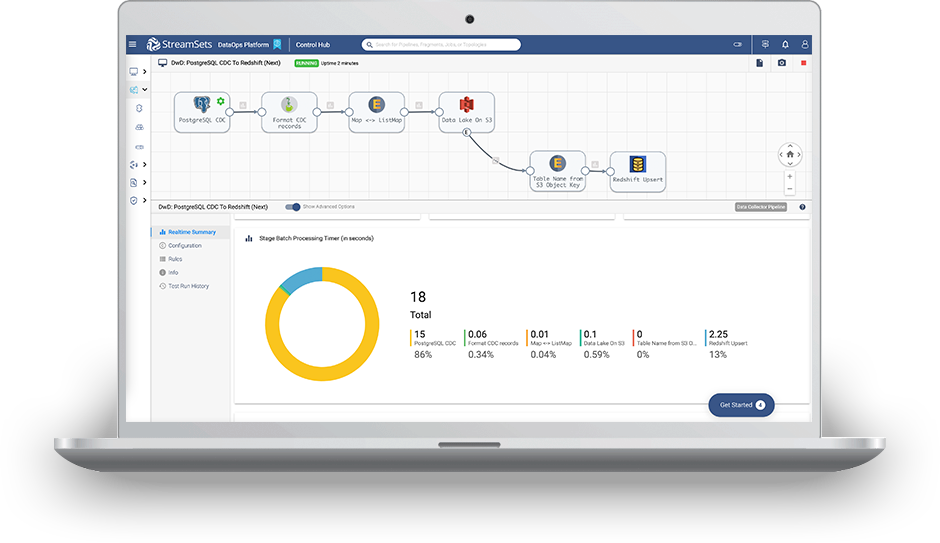
What happened? Check the status, monitor and troubleshoot jobs.
Looking for more demos? Subscribe to SteamSets Live! In these monthly 45 min sessions, see live demos of StreamSets DataOps Platform.
Connect With an Expert
We’re continuing to develop all the high quality tutorials, sample pipelines, and 5-star documentation you have come to expect from StreamSets. Need one-on-one help.
From Greenbelt to Blackbelt
If you’ve got some experience under your belt and are ready to take it to the next level, explore all the tools you need to becoming a power user.