StreamSets platform provides an end-to-end enterprise solution to maximize the value of your Snowflake Data Cloud. The platform can ingest data into Snowflake (using batch, streaming and change data capture data pipelines). With the preview of the StreamSets Engine for Snowpark, we are excited to offer a new way to integrate StreamSets with Snowflake to run complex transformations within Snowflake.
Transformer for Snowflake
The StreamSets Engine for Snowflake is integrated into Snowpark to enable both the expressiveness and flexibility of Snowpark’s multi-language support, as well as the simplicity of data cloud operations that would normally be limited to SQL.
Snowpark enables data engineers, data scientists, and developers coding in languages like Scala, Java and Python to take advantage of Snowflake’s powerful platform. Instead of extracting data out of Snowflake to run complex transformations, data engineers and ETL developers can code in languages other than SQL.
In this blog, we will review how to use in-line or drop-in UDFs written in Java that are then leveraged in data pipelines on the upcoming StreamSets Engine for Snowpark to perform transformations directly on Snowflake.
Aside from UDFs we will also look at how to perform ETL workload across several tables in Snowflake using the StreamSets Engine for Snowpark.
User Defined Functions in Snowpark
Data engineers and developers can use IDEs and tools of their choosing to write User Defined Functions (UDFs) which can be bound and used, and Snowpark pushes all of those operations directly on Snowflake.
Some scenarios and use cases where loading UDFs are beneficial include:
- Loading trained models for scoring
- Scanning column values for anomalies and PII
- Deploying common (Java) libraries for developers across data team members
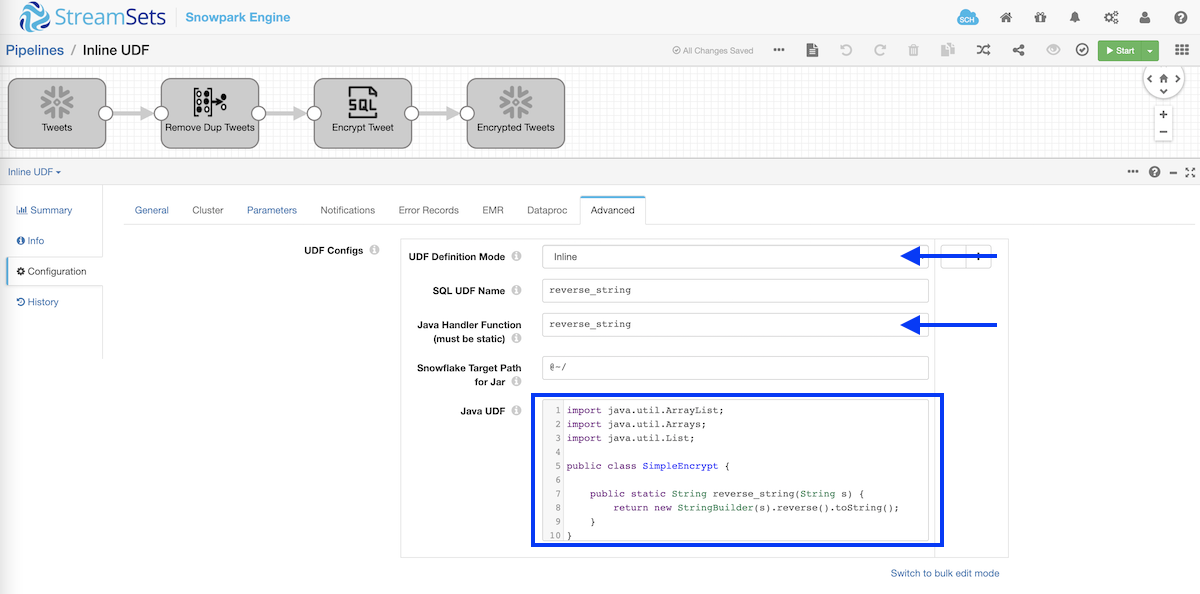
In-line UDF
In this example, the StreamSets Engine for Snowpark data pipeline is designed to read Twitter data from a table in Snowflake, perform some transformations like remove duplicate tweets and “encrypt” tweets using the in-line UDF and store those in a new table in Snowflake.
The in-line UDF comprises a Java class with one static method that takes a string as a parameter and returns the same string in reverse order as shown below.
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class SimpleEncrypt {
public static String reverse_string(String s) {
return new StringBuilder(s).reverse().toString();
}
}
This UDF can be dropped into the data pipeline as shown below.
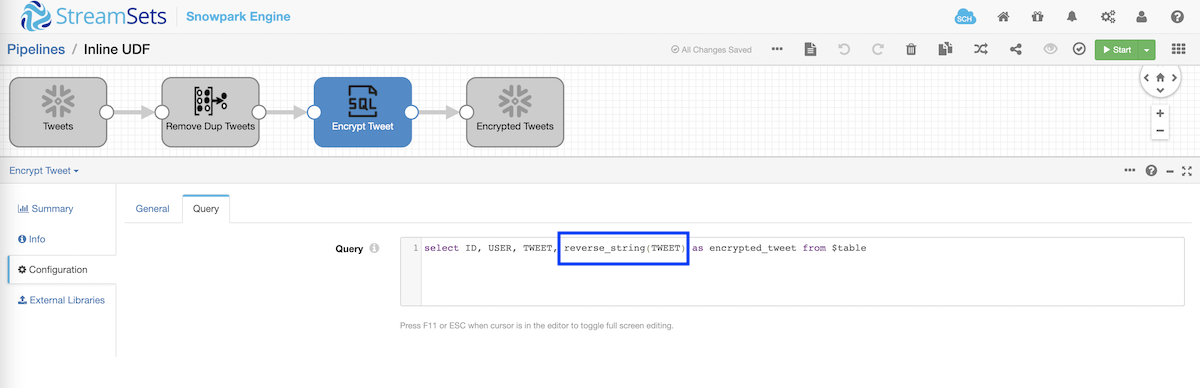
And the UDF reverse_string can then be called from SQL to perform the transformation as shown below.
select ID, USER, reverse_string(TWEET) as encrypted_tweet from $table
Running this data pipeline results in the table being automatically created on Snowflake, if it doesn’t already exist, and the data being inserted into it as per the SQL query described above.
Looking at Transformer for Snowflake logs also shows the in-line UDF being automatically created or replaced and registered in Snowflake.
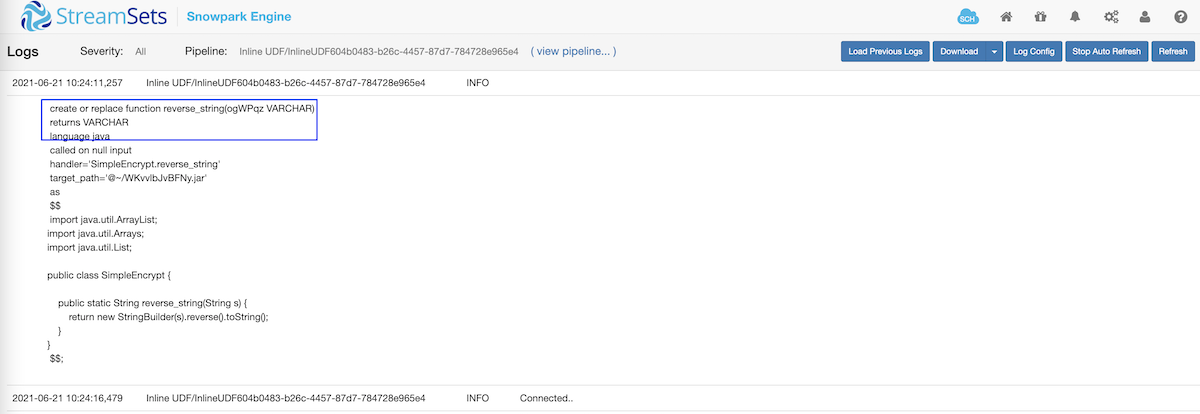
create or replace function reverse_string(NJbCbG VARCHAR)
returns VARCHAR
language java
called on null input
handler='EncryptString.encrypt_string'
target_path='@~/CXtSzaVPFLaH.jar'
as
$$
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class EncryptString {
public static String encrypt_string(String s) {
return new StringBuilder(s).reverse().toString();
}
}
$$;
UDFs in a JAR
Now let’s look at another example where instead of writing the UDF code in-line we include a JAR file with one or more (static) methods that can be invoked as functions in the data pipeline.
This data pipeline in Transformer for Snowflake is designed to read Twitter data from a table in Snowflake, perform transformations like removing duplicate tweets, scoring tweets (1 = positive, -1 = negative, or 0 = neutral), “encrypt” tweets, and write tweet records to two different tables in Snowflake based on condition if tweet “score” is != 0 — with all execution occurring within Snowflake.
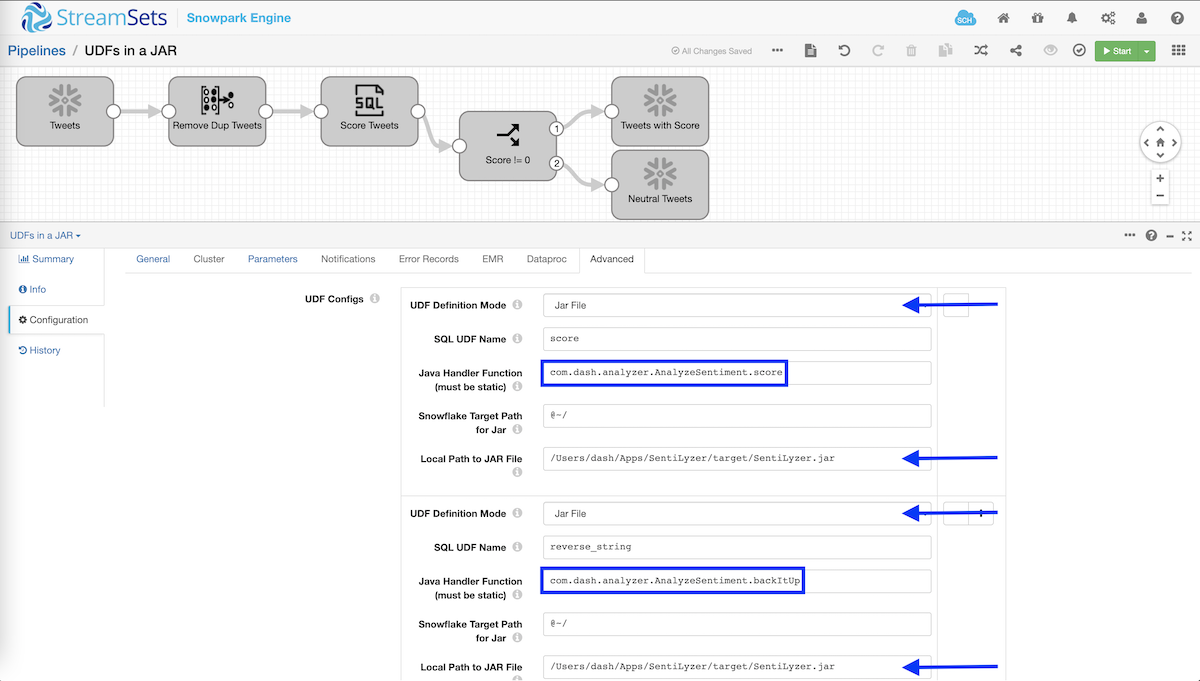
The pipeline is configured to use and invoke two functions from the same JAR as shown above, but you just easily load functions from different JARs. Also note that in this example, I’ve used a dead-simple logic of “scoring” tweets based on the existence of certain “positive” and/or “negative” words, and thanks to Marcin for compiling and providing a great list of those words, but you can imagine loading a trained model like CoreNLP instead for deriving advanced linguistic annotations. UPDATE as of 10/26/2021: I’ve updated my Java project on GitHub and have exposed a new static method sentiment_analysis() that uses CoreNLP.
Then the UDFs score_tweet and reverse_string can be used in the SQL query as shown below.
select ID, USER, TWEET, score_tweet(TWEET) as score, reverse_string(TWEET) as reverse_tweet from $table
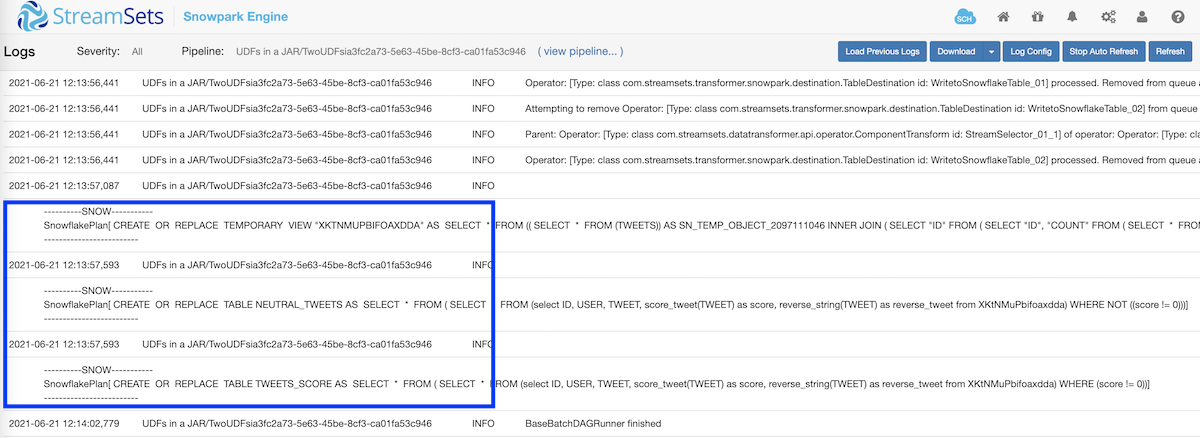
Looking at the StreamSets Engine for Snowpark logs also shows the tables being automatically created or replaced in Snowflake.
Sample Java Project on GitHub
If you’d like to check out or expand upon the Java project I built for this demo in IntelliJ, it can be found here in GitHub. UPDATE as of 10/26/2021: I’ve updated my Java project on GitHub and have exposed a new static method sentiment_analysis() that uses CoreNLP.
Watch StreamSets Transformer for Snowflake Demo
ETL Workloads
Aside from using the StreamSets Engine for Snowpark to register, bind and use UDFs, the engine is also built for implementing complex end-to-end ETL workloads. As an example, data engineers can use the engine to denormalize and aggregate data across several tables in Snowflake.
Denormalization and Aggregations
In the following example, the data pipeline is designed to join across master-detail tables, Orders and Order Items respectively, and also with foreign key constraints Products and Customers using multiple Join processors. And because the resulting denormalized records would include redundant columns like CUSTOMER_ID from Orders table and Customers table, for example, a Field Remover processor is injected into the pipeline to remove such columns.
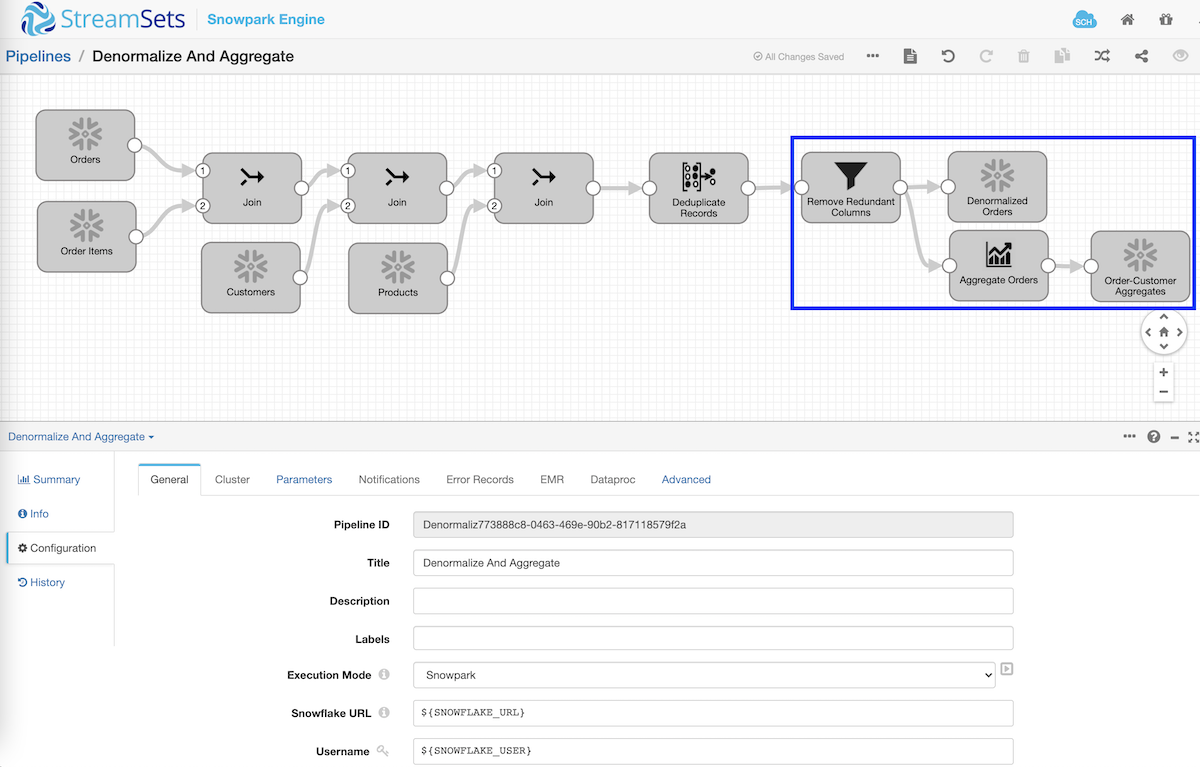
Also note that the data pipelines can have multiple destinations as shown above. A good example of this would be to perform different transformations on the same data being read once in the same pipeline. In this case, it’s performing aggregations to calculate the total order amount per order per customer from information that’s coming in from three different tables — ORDERS, ORDER_ITEMS, and CUSTOMERS.
NOTE: If the destination tables don’t already exist on Snowflake, they are created automatically during pipeline execution.
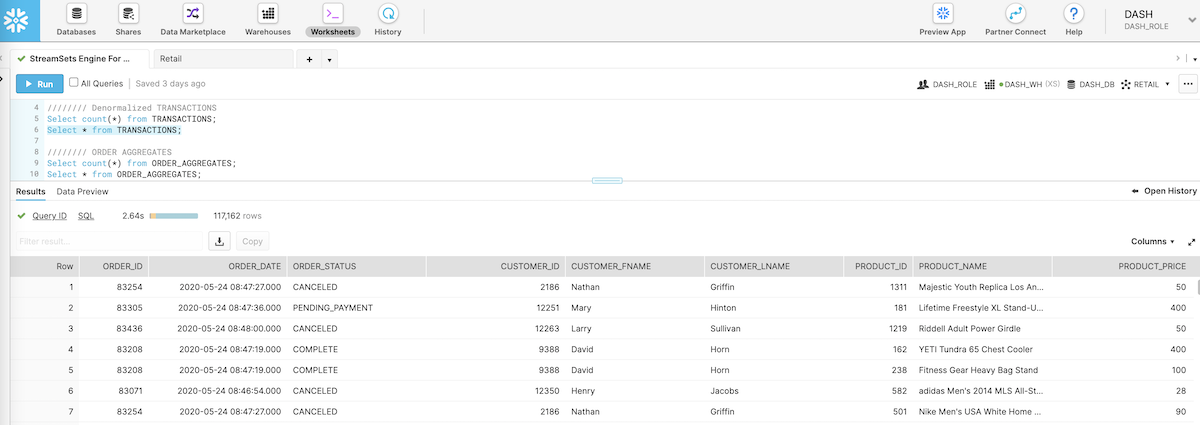
Query Denormalized Transactions In Snowflake
Here are the denormalized transactions in Snowflake as generated by the data pipeline.
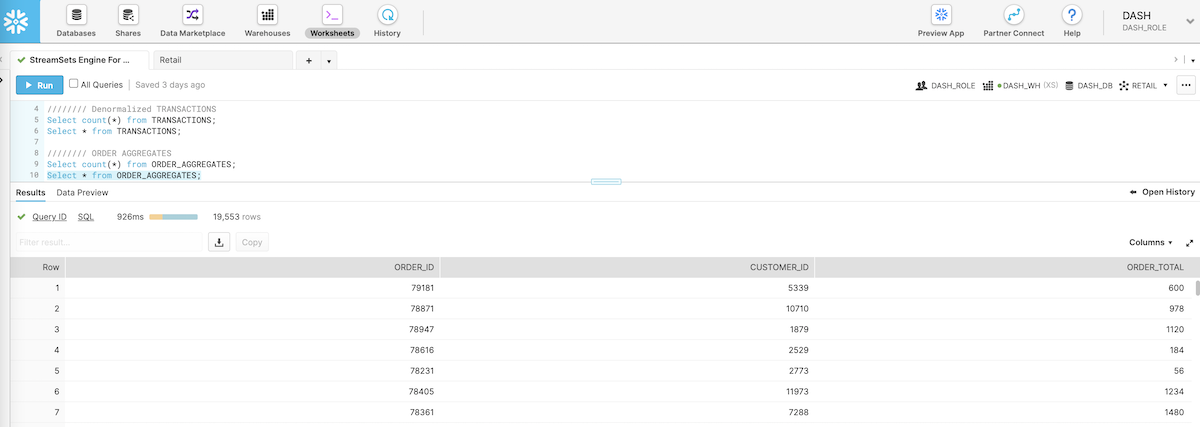
Query Order Aggregates In Snowflake
Here are the order aggregates for each customer per order in Snowflake as generated by the data pipeline.
Summary
With this new integration, data engineers can go further than SQL to express powerful data pipeline logic with the StreamSets Platform. In addition, Transformer for Snowflake provides all the benefits of StreamSets Platform with built-in version control, monitoring and orchestration of complex data pipelines at scale in the cloud.
If you’d like to see a live demo, contact trysnowpark@streamsets.com.