Smart Data Pipelines: Tools,
Techniques, and Key Concepts
How data pipelines become smart and why savvy data engineers use smart data pipelines
What Is a Data Pipeline?
A data pipeline is the series of steps that allow data from one system to move to and become useful in another system, particularly analytics, data science, or AI and machine learning systems. At a high level, a data pipeline works by pulling data from the source, applying rules for transformation and processing, then pushing data to its destination.

What is the Purpose of a Data Pipeline?
There’s a lot of data out there. Each person creates 2.5 quintillion bytes of data per day according to current estimates, and there are 7.8 billion people in the world. Data pipelines transform raw data into data ready for analytics, applications, machine learning and AI systems. They keep data flowing to solve problems, inform decisions, and, let’s face it, make our lives more convenient.
Data pipelines are used to:
- Deliver sales data to sales and marketing for customer 360
- Link a global network of scientists and doctors to speed drug discovery
- Recommend financial services to help a business thrive
- Track COVID-19 cases and inform community health decisions
- Combine diverse sensor data with AI for predictive maintenance
With so much work to do, data pipelines can get pretty complicated pretty fast.
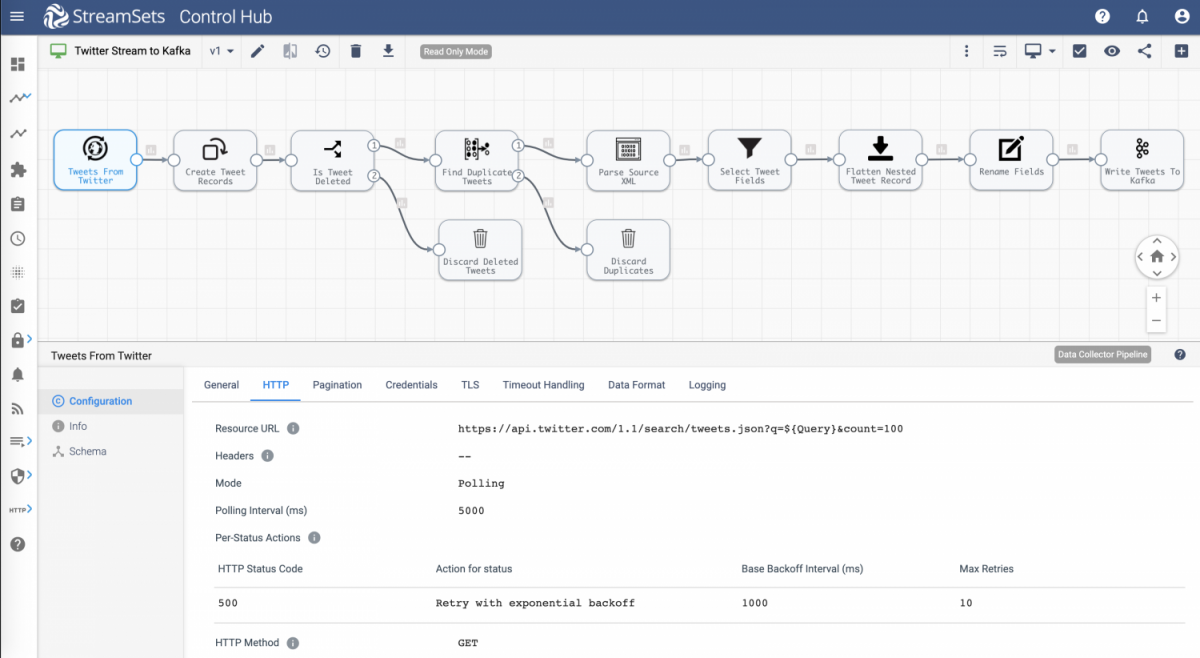
Benefits of Using Data Pipelines
Data pipelines done right have incredible advantages for companies and organizations, and the work they do.
Self-service Data
Data pipelines that can be created ad hoc by data scientists and business analysts unstick the IT bottleneck. That means when people have brilliant ideas, they can test them, fail fast, and innovate faster.
Accelerate Cloud Migration and Adoption
Data pipelines help you expand your cloud presence and migrate data to cloud platforms (yes, that’s with an s). Cloud computing helps you feed many new use cases at processing speeds, cost-effectiveness, and bursting capacity unheard of in traditional on-premises data centers. Plus your team can take advantage of rapid innovation happening on those cloud platforms such as natural language processing, sentiment analysis, image processing, and more.
Real-time Analytics and Applications
Real-time or near real-time functionality in consumer and business applications puts the pressure on data pipelines to deliver the right data, to the right place, right now. Streaming data pipelines deliver continuous data to real-time analytics and applications.

Challenges to Using Data Pipelines
When your business depends on data, what happens when dataflow comes to a screeching halt? Or data takes a wrong turn and never reaches the intended destination? Or worse, the data is wrong with potentially catastrophic consequences?
Always Under Construction Data
Building and debugging data pipelines takes time. You have to align with the schema, set sources and destinations, check your work, find errors, and back and forth until you can finally go live, by which time the business requirements may have changed again. This is why so many data engineers have such a backlog of work.
Out of Order Data Pipelines
Even a small change to a row or a table can mean hours of rework, updating each stage in the pipeline, debugging, and then deploying the new data pipeline. Data pipelines often have to go offline to make updates or fixes. Unplanned changes can cause hidden breakages that take months of engineering time to uncover and fix. These unexpected, unplanned, and unrelenting changes are referred to as “data drift”.
Build It and They Will Come
Data pipelines are built for specific frameworks, processors, and platforms. Changing any one of those infrastructure technologies to take advantage of cost savings or other optimizations can mean weeks or months of rebuilding and testing pipelines before deployment.
Before we look at how to address these challenges to data pipeline development, we need to take a moment to understand how data pipelines work.
How Does a Data Pipeline Work?
When a data pipeline is deployed and running, it pulls data from the source, applies rules for transformation and processing, then pushes data to its destination.
5 Common Data Pipeline Sources
- JDBC
- Oracle CDC
- HTTP Client
- HDFS
- Apache Kafka
Data sources handle data in very different ways and might include applications, messaging systems, data streams, relational and NoSQL databases, cloud object storage, data warehouses, and data lakes. The data structure varies significantly, depending on the source.
Common Transformations
Transformations are the changes to data structure, format, or values as well as calculations and modifications to the data itself. A pipeline might have any number of transformations embedded to prepare data for use or route it correctly. A few examples:
- Masking PII (personally identifiable information) for protection and compliance
- Converting data type for fields
- Calculating based on a formula or expression
- Renaming fields, columns, and features
- Joining or merging datasets
- Converting data formats (JSON to Parquet, for example)
- Generating Avro Schema and other schema types on the fly
- Handling Slowly Changing Dimensions
5 Common Data Pipeline Destinations
- Apache Kafka
- JDBC
- Snowflake
- Amazon S3
- Databricks
Destinations are the systems where the data is ready to use, put directly into use, or stored for potential use. They include applications, messaging systems, data streams, relational and NoSQL databases, data warehouses, data lakes, and cloud object storage.
Most data pipeline engineering tools offer a library of connectors and integrations that are pre-built for fast pipeline development.
Data Engineer’s Handbook
Data Pipeline Architectures
Depending on the type of data you are gathering and how it will be used, you might require different types of data pipeline architectures. Many data engineers consider streaming data pipelines the preferred architecture, but it is important to understand all 3 basic architectures you might use.
Batch Data Pipeline
Batch data pipelines move large sets of data at a particular time or in response to a behavior or when a threshold is met. A batch data pipeline is often used for bulk ingestion or ETL processing. A batch data pipeline might be used to deliver data weekly or daily from a CRM system to a data warehouse for use in a dashboard for reporting and business intelligence.
Streaming Data Pipeline
Streaming data pipelines flow data continuously from source to destination as it is created. Streaming data pipelines are used to populate data lakes or as part of data warehouse integration, or to publish to a messaging system or data stream. They are also used in event processing for real-time applications. For example, streaming data pipelines might be used to provide real-time data to a fraud detection system and to monitor quality of service.
Change Data Capture Pipeline (CDC)
Change data capture pipelines are used to refresh data and keep multiple systems in sync. Instead of copying the entire database, only changes to data since the last sync are shared. This can be particularly useful during a cloud migration project when 2 systems are operating with the same data sets.
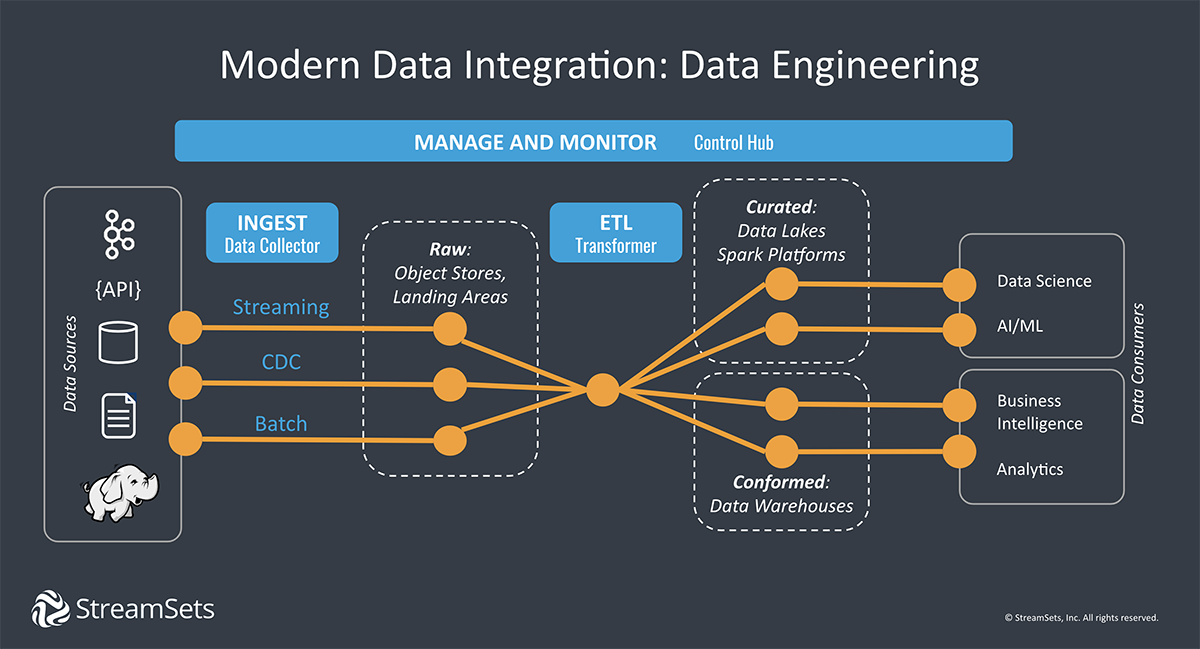
Data Pipeline Tools
Building a single pipeline for a single purpose at a given time is no problem. Grab a simple tool for setting up a data pipeline or hand code the steps. But how do you scale that process to thousands of data pipelines to support increasing demand for data across your organization over months or years? When considering data pipeline tools, it is important to think about where your data platform is headed.
- Are you grabbing data from one place to put it somewhere else? Or do you need to transform it to fit the downstream analytics requirements?
- Is your data environment stable and fully under your control? Or is it dynamic and pulling data from outside systems or apps?
- Will the pipeline move data once, for a short-term analysis project? Or will the pipelines you build need to be operationalized to handle data flows over time?
Data Ingestion and Data Loading Tools
Data ingestion and data loading tools that make data pipelines easy to set up, easy to build, and easy to deploy solve the “under construction” issue, but only if you can count on your data scientists to do the data prep work later. These tools only support the most basic transformations and work best for simply copying data. Instead of being intent-driven, these data pipelines are rigid and embedded with the specifics of data structure and semantics. Instead of adapting to change when data drift happens, they have to be rebuilt and deployed again.
Traditional Data Integration Platforms
More complex data integration or ETL software may have a solution for every possible scenario with hundreds of connectors, integrations, and transformations. But these platforms were designed for an era when data drift was rare. At the first hint of change, these data pipelines break and require massive rework. The demands for digital transformation are moving fast and planning for every possible outcome may not be possible.
Modern Data Integration and Transformation Platforms
Today’s dynamic infrastructure and massive datasets call for data integration solutions built for hybrid and multi-cloud architectures. A modern data integration platform lets you build data pipelines insulated from unexpected change.
Instead of being perpetually under construction, out of order, or limited to a single platform, these data pipelines allow you to move fast with confidence that your data will continue to flow with little to no intervention. These cloud platforms allow you to:
- Design and deploy data pipelines with an easy-to-use GUI
- Simplify building and maintaining complex transformations in Snowflake and other data platforms
- Build in as much resiliency as possible to handle changes
- Adopt new platforms (add Azure alongside AWS, for example) by pointing to them, a task that takes just minutes
Smart Data Pipeline Examples
Batch, streaming and CDC data pipeline architectures can be applied to business and operational needs in a thousand different ways. Here are a few examples of smart data pipelines used to ingest, transform, and deliver data.
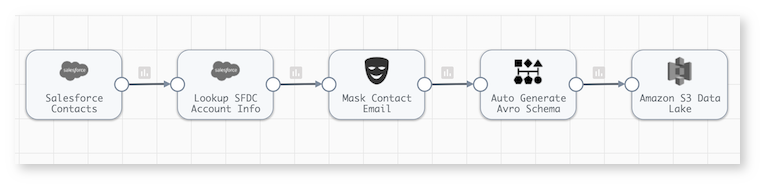
Bulk Ingestion from Salesforce to a Data Lake on Amazon
This bulk ingestion data pipeline would be ideal for archiving Salesforce contacts with some account information in Amazon S3. A Salesforce data ingestion pipeline might run in batch mode for periodic archiving or in real-time to constantly offload customer data. The destination could be any cloud storage platform.
Migration to Databricks Delta Lake with Change Data Capture
Many organizations are moving data lakes from on-premises to the cloud to take advantage of pay-as-you-go pricing, higher performance, bursting capabilities, and new technologies. This change data capture pipeline tracks changes in the data source and transfers them to the destination to keep the systems in sync after the initial load.
Combine Multiple Kafka Message Streams to Amazon S3
Apache Kafka is a distributed event streaming platform used for streaming analytics. This streaming data pipeline handles large amounts of data from multiple upstream applications writing to multiple Kafka topics. You can send Kafka messages to S3 and scale vertically by increasing the number of threads, transforming the data and delivering it to an Amazon S3 data lake.
MLflow Integration Pipeline for Model Experiments
Machine learning models are only as good as the quality of data and the size of datasets used to train the models. Experimentation requires data scientists to create models in a rapid, iterative manner using subsets of trusted datasets. This MLflow integration pipeline on Databricks allows for tracking and versioning of model training details, plus tracking versions so data scientists have fast access to training data and can move into production more easily.
Data Pipelines for Multiple Use Cases and Personas
Sometimes your data has to do 2 things at once. This Spark ETL data pipeline collects sales revenue data, calculates totals by region, then delivers it to multiple destinations in the right formats to satisfy the business needs of 2 different departments in a single pipeline. Data is delivered to a Spark platform in Parquet on Azure HDInsight and to a Microsoft Power BI as SQL data. Everyone’s happy.
In addition to the resources above, you can always jumpstart your pipeline design with these ready-to-deploy sample data pipelines. Simply, duplicate and update the sources and destinations to run.
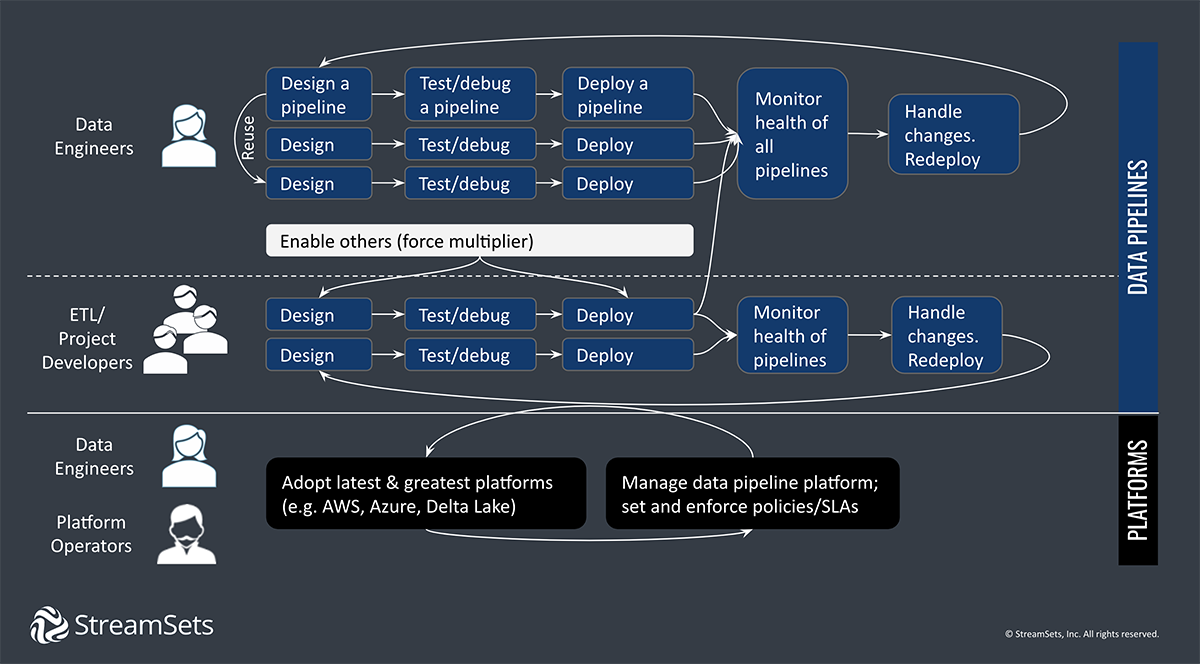
What Is a Smart Data Pipeline?
If a car can drive itself and a watch can notify your doctor when your blood pressure goes up, why are data engineers still specifying schemas and rebuilding pipelines? A smart data pipeline is a data pipeline with intelligence built in to abstract away details and automate as much as possible, so it is easy to set up and operate continuously with very little intervention. As a result, smart data pipelines are fast to build and deploy, fault tolerant, adaptive, and self healing.
The 2020 global pandemic made it abundantly clear that companies have to be able to respond to changing conditions quickly. The StreamSets data engineering platform is dedicated to building the smart data pipelines needed to power DataOps across hybrid and multi-cloud architectures. You can build your first data pipeline with StreamSets for free.