In this post, we will take a look at best practices for integrating StreamSets Data Collector Engine (SDC), a fast data ingestion engine, with Kafka. Then, we’ll dive deep into the details of connecting Kafka to Amazon S3. But first, it’ll help to have an overview of Kafka, S3, and StreamSets Data Collector.
Kafka, Amazon S3 and SDC
Apache Kafka is an open-source, distributed event streaming platform used by thousands of companies for streaming analytics and for other mission-critical applications.
Kafka enables organizations to ingest data from a variety of sources which Kafka stores in “topics.” Kafka Producers ingest data from a source into Kafka Topics which are then read and transferred to your desired data store (like Amazon S3) by Kafka Consumers.
S3 is Amazon’s cloud-based storage service which has highly scalable capacity for data and metadata from many data sources. S3 allows you to transfer data to S3 buckets using APIs, connectors, ETL tools, and more.
In the context of, StreamSets Data Collector acts as the Kafka Consumer. It reads data from your Kafka Topics and transfers it to Amazon S3.
Connecting Kafka to S3 using Confluent’s built-in Kafka S3 Connector
It is possible to connect Kafka to S3 using Kafka Connect, which is a part of Apache Kafka. You can use the open-source S3 connector and deal with the manual configuration. But in the sections that follow, we’ll explain how you can connect and send Kafka Messages to Amazon S3 the easier way with SDC.
Send Kafka Messages to Amazon S3 | Kafka Consumer
In some scenarios an organization may already have an existing data pipeline bringing messages to Kafka. In this case, SDC can take on the role of a consumer and handle all of the logic for taking data from Kafka to wherever it needs to go. For example, you could deliver data from Kafka message to Amazon S3/HDFS/Elasticsearch or whatever destination you choose without writing any code. With the use of StreamSets Kafka origin you can take Kafka messages and batch them together into appropriately sized and push them to desired destination.
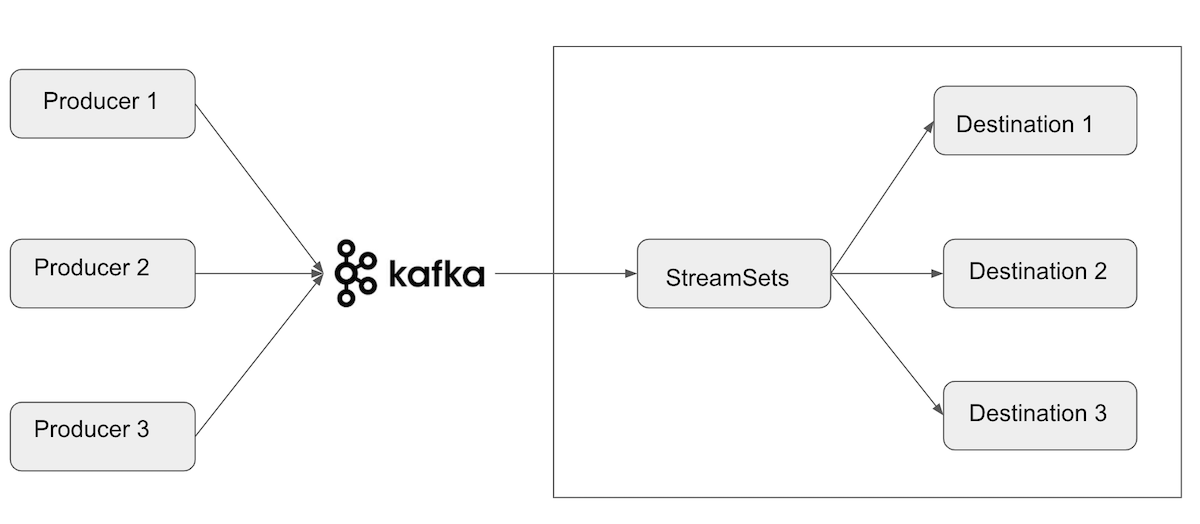 Kafka messages consumer origins:
Kafka messages consumer origins:
- Kafka Consumer
- Kafka MultiTopic Consumer
Why are there two Kafka origins?
Suppose you have an application that needs to read messages from a Kafka topic, run some validations against them, and write the results to another data store. In this case you will create a consumer pipeline which subscribes to the appropriate topic, and start receiving messages, validating them and writing the results.

This may work well for a while, but what if the rate at which producers write messages to the topic exceeds the rate at which your application can validate them? If you are limited to a single consumer reading and processing the data, your application may fall further and further behind, unable to keep up with the rate of incoming messages. Obviously, there is a need to scale consumption from topics. Just like multiple producers can write to the same topic, we need to allow multiple consumers to read from the same topic and as well read from multiple topics, splitting the data between them. That’s where Kafka multi-topic consumer origin comes in handy. This origin uses multiple threads to enable parallel processing of data.
Kafka Multi-topic Consumer origin can then take advantage of additional processors and memory to run several consumer threads in parallel. Kafka will distribute messages across the partitions, and the load will be shared between the consumer threads.
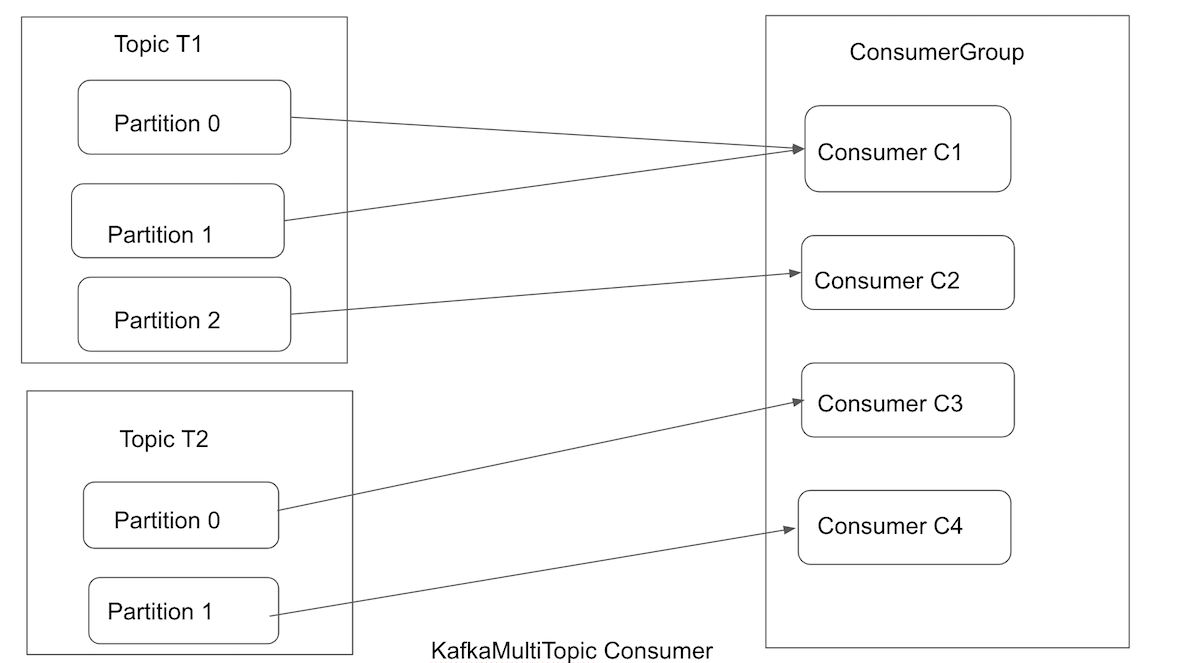
Which one is the right choice for me?
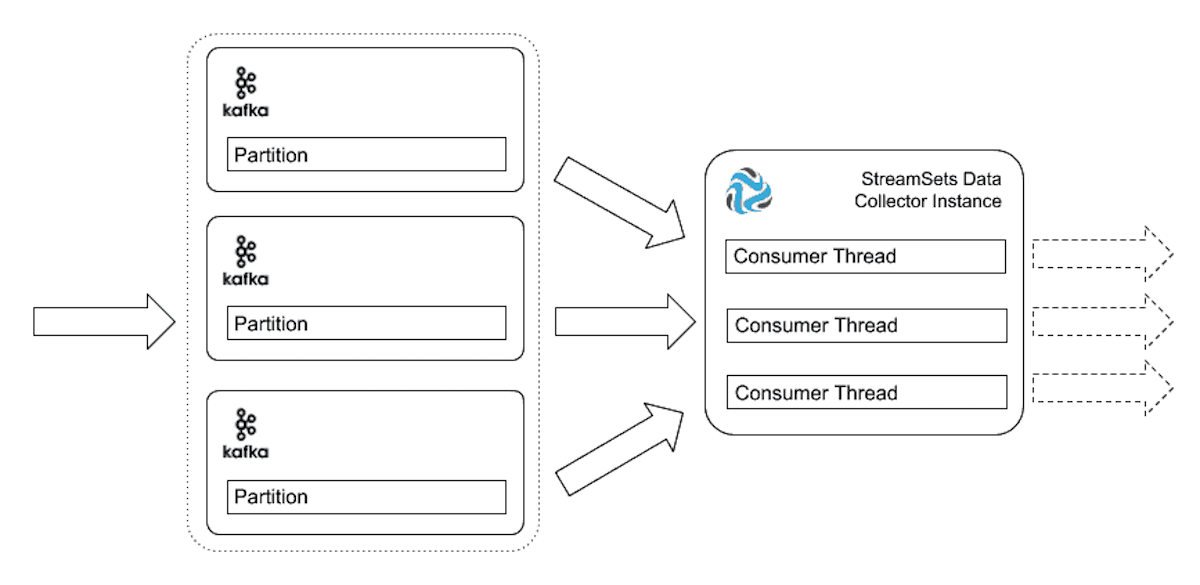
If your SDC engine is running on a more powerful machine which has high resource availability, then use Kafka Multi-topic origin to scale vertically.
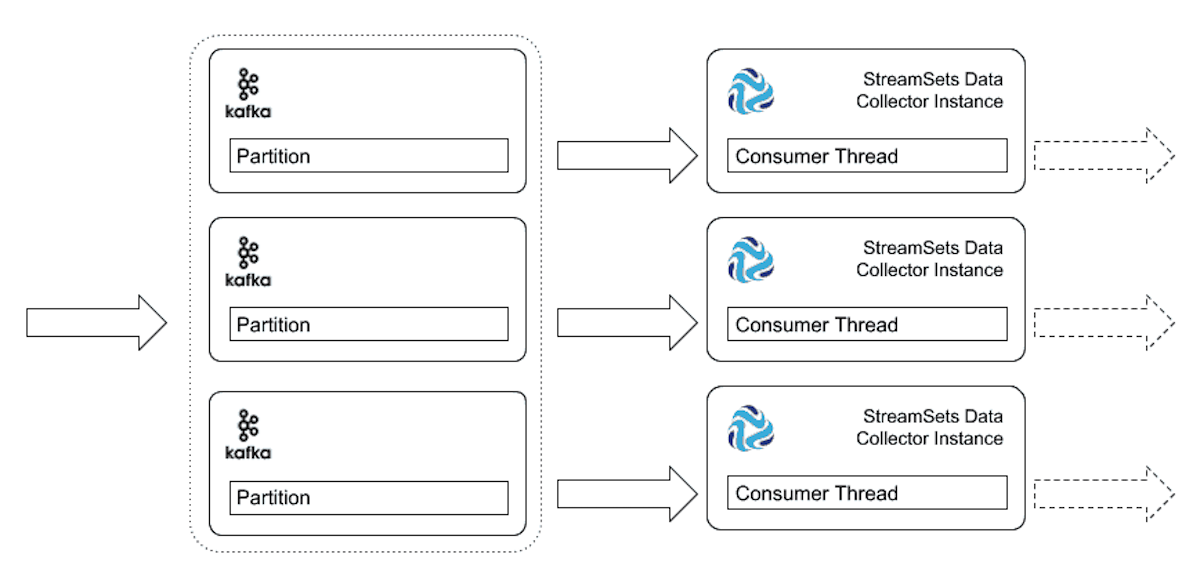
 However, if you plan to scale horizontally which is a more cost-effective option, then use Kafka consumer again partitioning the Kafka topic, but this time running the pipeline on multiple Data Collector instances. This has some extra overhead of maintenance if you are manually running multiple instances of this pipeline over multiple data collector instances, but this can be achieved easily with StreamSets Control Hub to start multiple pipeline instances through the same job.
However, if you plan to scale horizontally which is a more cost-effective option, then use Kafka consumer again partitioning the Kafka topic, but this time running the pipeline on multiple Data Collector instances. This has some extra overhead of maintenance if you are manually running multiple instances of this pipeline over multiple data collector instances, but this can be achieved easily with StreamSets Control Hub to start multiple pipeline instances through the same job.
 Advanced Features
Advanced Features
Let’s look at some Advanced features which you can leverage in both Kafka origins.
Kafka Security
You can configure both Kafka stages – Kafka Consumer and Kafka Multitopic Consumer – to connect securely through the following methods:
- Kerberos
- SSL/TLS
- Both SSL/TLS and Kerberos
Enabling security requires configuring additional Kafka configuration properties in the stage in addition to completing the prerequisite tasks.
Record Header Attributes
Both Kafka origins creates record header attributes that include information about the originating file for the record. Especially when the origin processes Avro data, it includes the Avro schema in an avroSchema record header attribute.
- avroSchema: When processing Avro data, provides the Avro schema
- offset: The offset where the record originated
- partition: The partition where the record originated
- topic: The topic where the record originated
Key Required to Send Kafka Messages to Amazon S3
You can configure both origins to capture the message keys included in each Kafka message and store them in generated records. Kafka message keys can be string values or Avro messages, depending on how your Kafka system is configured. You can store message key values in a record header/field or both and can use the values in pipeline processing logic or to write them to destination systems. If you have no need for message keys, you can discard them. The Kafka Consumer and Kafka Multi-topic Consumer origins discard message keys by default.
Data Pipeline Overview And Implementation
The goal here is to read Avro files from a file system directory and write them to a Kafka topic using the StreamSets Kafka Producer. We’ll then use a second pipeline configured with a Kafka Consumer to read all the messages from that topic, perform a set of transformations to mask the data and determine the type of credit card. And finally send Kafka messages to Amazon S3 by partitioning the data on credit card type and make sure that the data stored on S3 is encrypted. In the second part of this blog, we will redesign our data pipeline for scaling and for handling huge amounts of data running through during your send of Kafka Messages to Amazon.
Here’s what the data in JSON format looks like:
{ "transaction_date":"dd/mm/YYYY", "card_number":"0000-0000-0000-0000", "card_expiry_date":"mm/YYYY", "card_security_code":"0000", "purchase_amount":"$00.00", "description":"transaction description of the purchase" }
Prerequisites
- A working instance of StreamSets Data Collector Engine ( 3.18.1+)
- A working Kafka instance (see the Quickstart for easy local setup. Last tested on version 1.1.0 but older and newer versions should work too.)
Publish data to Kafka topic using Kafka producer
Let’s create Kafka topic — “demo-topic” — by running this command
bin/Kafka-topics.sh --create --topic demo-topic --bootstrap-server localhost:9092 --partitions 3
Now let’s push some sample data to this Kafka topic using a simple data pipeline. We will read Avro files from a file system directory and write them to a Kafka topic using the StreamSets Kafka Producer in SDC Record data format. Then use another data pipeline to read the SDC Record data from Kafka and write it to Elasticsearch and convert data to Avro for S3.
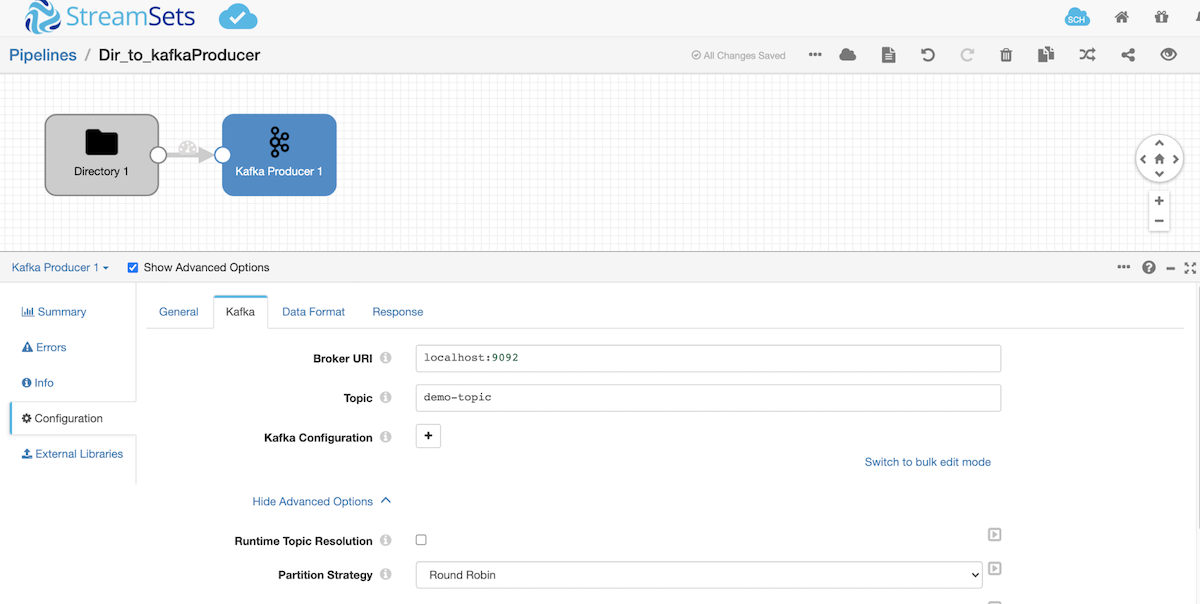
Consume Kafka messages and store them in Amazon S3
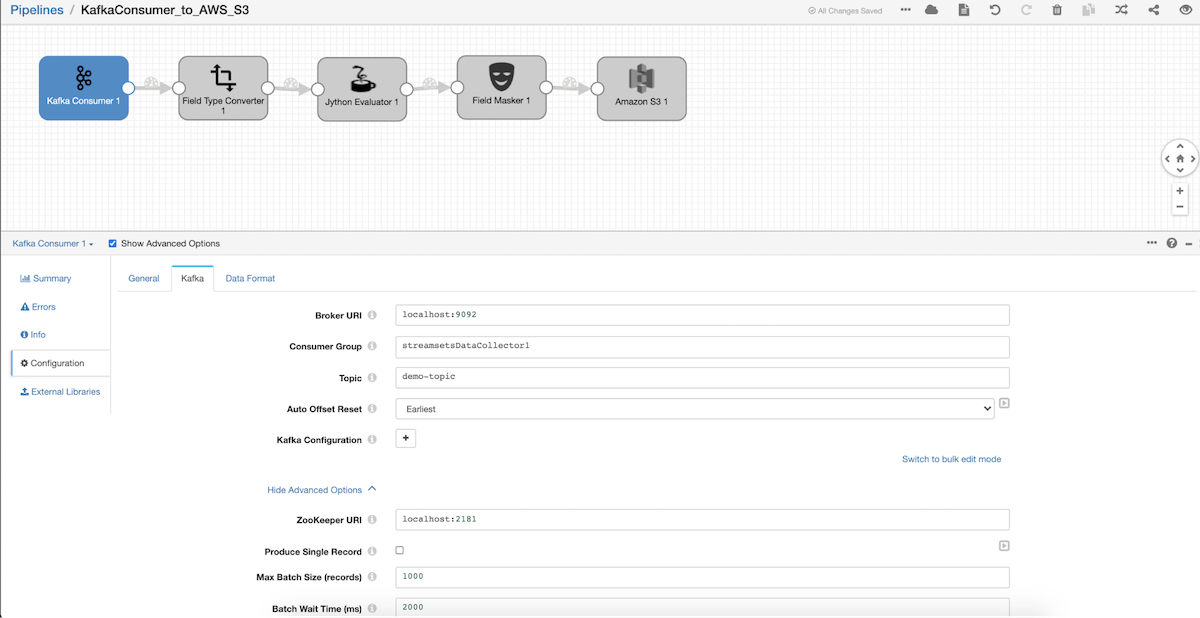
Kafka Consumer
- Let’s configure Kafka origin to consume messages from your local Kafka setup and on Data Format tab select SDC Record.
Field Converter
- It so happens that the card number field is defined as an integer in Avro. We will want to convert this to a string value. So type ‘/card_number‘ in the ‘Fields to Convert’ text box and set it to type String in ‘Convert to Type’. Leave the rest to default values.
Jython Evaluator
- In this stage we’ll use a small piece of python code to look at the first few digits of the card number and figure out what type of card it is. We’ll add that card type to a new field called ‘credit_card_type‘.
Field Masker
- The last step of the process is to mask the card number so that the last 4 digits of the card is all that makes it to the data stores.
Writing Kafka Messages to Amazon S3
- We’ll convert the data back to Avro format and store it in S3 bucket.
- On ‘Data Format‘ select ‘Avro‘ and ‘In Pipeline Configuration‘ for ‘Avro Schema Location’. Then specify the following schema for Avro Schema:
{"namespace" : "cctest.avro", "type": "record", "name": "CCTest", "doc": "Test Credit Card Transactions", "fields": [ {"name": "transaction_date", "type": "string"}, {"name": "card_number", "type": "string"}, {"name": "card_expiry_date", "type": "string"}, {"name": "card_security_code", "type": "string"}, {"name": "purchase_amount", "type": "string"}, {"name": "description", "type": "string"} ] }
- To save storage space on the S3 bucket let’s compress the data as it’s written. Select BZip2 as the Avro Compression Codec.
- To write to partitions based on data in the `credit_card_type` field, we will use ${record:value(‘/credit_card_type’)} expression as the Partition Prefix. With this expression, the destination will create and write records to partitions based on the “credit_card_type” value in the record.
- Protecting Sensitive Data: you can use any of the options below for server-side encryption on Amazon S3 to protect sensitive data. For example, in our case, credit card numbers.
- Amazon S3-Managed Encryption Keys (SSE-S3)
- AWS KMS-Managed Encryption Keys (SSE-KMS)
- Customer-Provided Encryption Keys (SSE-C)

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
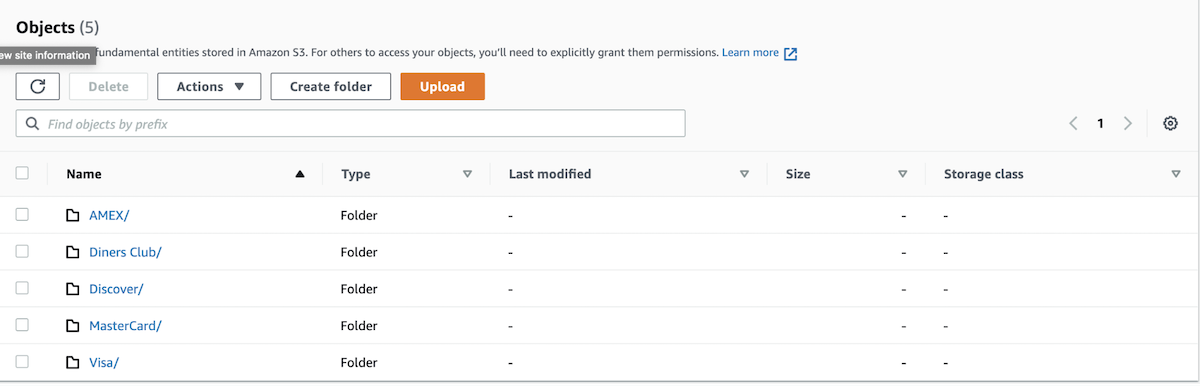
Output on Amazon S3
Note that the Output on S3 will be partitioned by ‘credit_card_type’
Data Pipeline Redesign For Large Workloads
Now let’s assume you have to scale the above solution given the scenario that you are dealing with large amounts of data and there are multiple upstream applications which are writing to multiple Kafka topics. So the rate at which producers write messages to the topic has exceeded the rate at which this pipeline consumes.
Also assume there is one more upstream pipeline/application which generates the similar credit card data and stores that info in Kafka topic `demo-topic-2`.
bin/Kafka-topics.sh --create --topic demo-topic-2 --bootstrap-server localhost:9092 --partitions 2
So instead of recreating the entire data pipeline from scratch we can easily redesign the existing pipeline by swapping out the origin with Kafka Multitopic Consumer origin. We can scale the pipeline vertically by increasing the number of threads. Simultaneously we can read multiple topics as well if required.
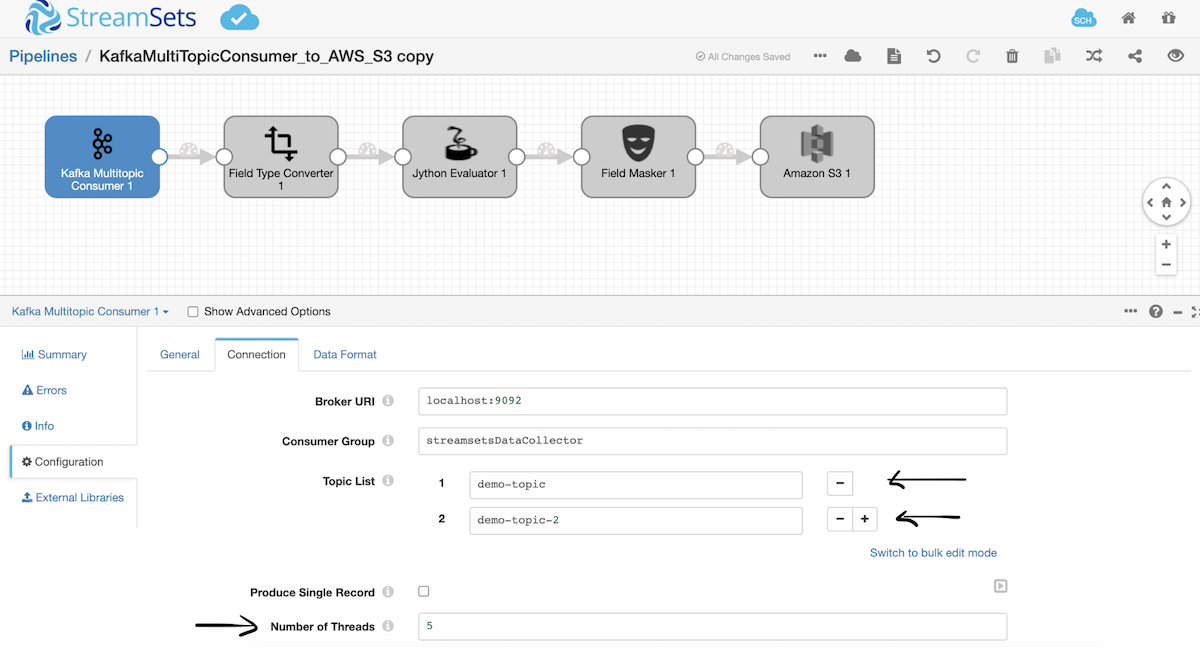
Note that the number of threads should always be less than or equal to the number of partitions which we are reading to achieve better parallelism. So here we have a demo-topic which has 3 partitions and demo-topic-2 which has 2 partitions. And hence we can set the number of threads to 5 to achieve more parallelism.
Note: Sample data and pipelines can be found on GitHub.
Conclusion
In this blog, we learned how to use StreamSets as a Kafka consumer and when to choose Kafka Consumer origin vs Kafka Multitopic Consumer origin to process large amounts of Kafka messages and take advantage of parallelism. We also explored various AWS S3 destination capabilities like partitioning and server side encryption.
Here are some resources that will help jump start your journey with designing and deploying data pipelines:
- Getting started videos for building data pipelines
- Learn more about StreamSets solutions for the cloud
- Start Building Smart Data Pipelines: Schedule a demo with an expert.