![]() One of the drivers behind Slack‘s rise as an enterprise collaboration tool is its rich set of integration mechanisms. Bots can monitor channels for messages and reply as if they were users, apps can send and receive messages and more via a wide range of APIs, and slash commands allow users to interact with external systems from the Slack message box. In this blog post, I’ll explain how I implemented a sample slash command as a microservice pipeline in StreamSets Data Collector 3.8.0, allowing users to look up stock item names and URLs from stock item numbers. Use this as the basis for creating your own slash command!
One of the drivers behind Slack‘s rise as an enterprise collaboration tool is its rich set of integration mechanisms. Bots can monitor channels for messages and reply as if they were users, apps can send and receive messages and more via a wide range of APIs, and slash commands allow users to interact with external systems from the Slack message box. In this blog post, I’ll explain how I implemented a sample slash command as a microservice pipeline in StreamSets Data Collector 3.8.0, allowing users to look up stock item names and URLs from stock item numbers. Use this as the basis for creating your own slash command!
Slack Slash Command Basics
Quoting from the excellent Slack API documentation:
Slash Commands are initiated from the message box in Slack, but they aren’t messages. A submitted Slash Command will cause a payload of data to be sent from Slack to an app, allowing the app to respond in whatever way it wants.
A user invokes a slash command by typing /commandname optionally followed by some text. Slack sends a signed HTTP form POST to the URL configured for that command. The form payload contains the identity of the requesting user, the command’s name, any text following the command, and more. The app verifies the signature and responds to the POST with either plain text or JSON content that Slack can display to the user. The JSON content can include text, images, links and more.
To implement a slash command, then, your app needs a publicly accessible HTTP endpoint, it needs to parse incoming text, and it needs to return a response. It just so happens that a microservice pipeline in StreamSets Data Collector can do all of this.
Microservice Pipelines in StreamSets Data Collector
A microservice pipeline comprises a microservice origin, zero or more processors, and one or more microservice destinations. A microservice origin receives requests from client apps, parses the request content, and hands off a batch of one or more records for processing by the remainder of the pipeline, holding the request connection open while the batch is processed. Processors act on the message content, looking up data, applying transformations, etc, before passing the batch to the destination(s). There are a variety of microservice destinations; some pass data to an external system, but they can all return a response via the connection held by the origin. For more information on microservice pipelines, and a detailed tutorial, see the blog post Create Microservice Pipelines with StreamSets Data Collector.
While the initial implementation of microservice pipelines wrapped the outgoing batch for return to the microservice client, the microservice origins in Data Collector 3.8.0 have a Send Raw Response configuration option that simply returns records as-is, with no wrapping. This setting is the key to implementing a Slack slash command, and many other integrations.
I created a microservice pipeline to implement a Slack slash command to lookup stock numbers and return the stock item’s name and URL. Here’s how you would invoke it from the Slack message box:

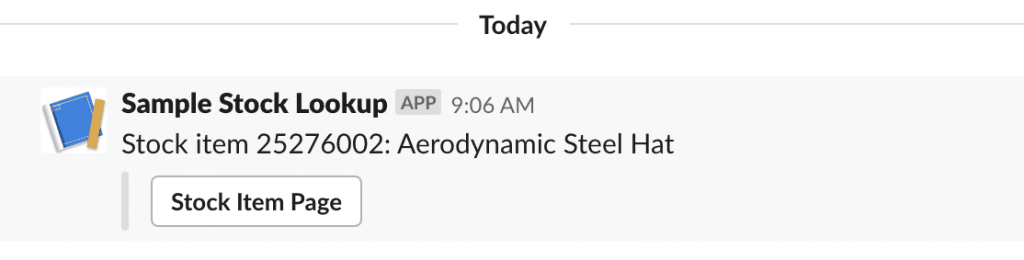
And the response:
Here’s the pipeline I built:
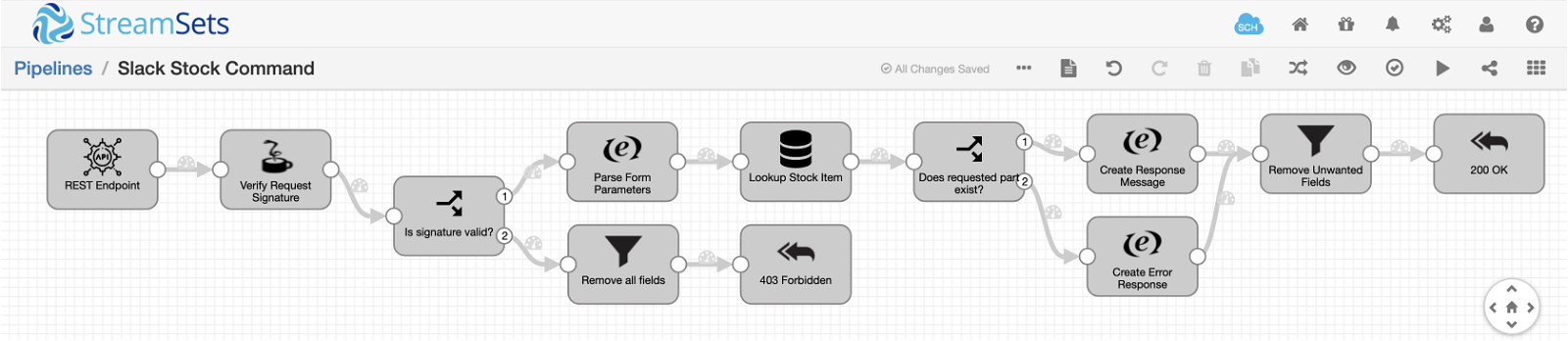
Although the pipeline looks quite complex, it’s actually pretty simple. Let’s look at it stage by stage, starting with the origin on the left.
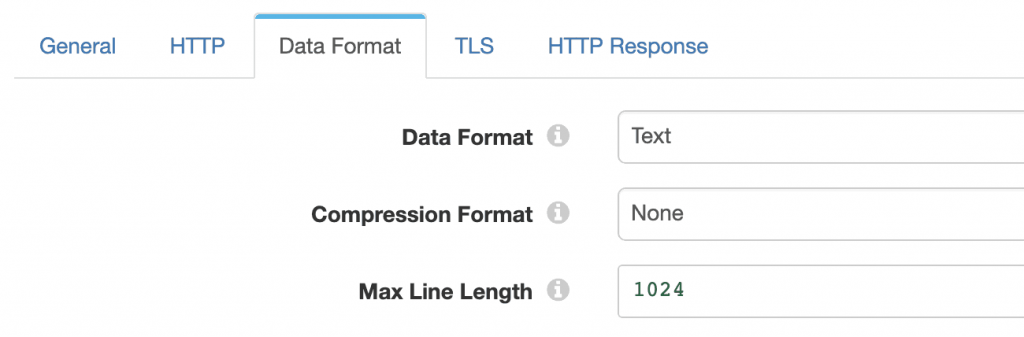
Since the incoming request arrives as an HTTP form post, the REST Service origin is configured with the Text data format:
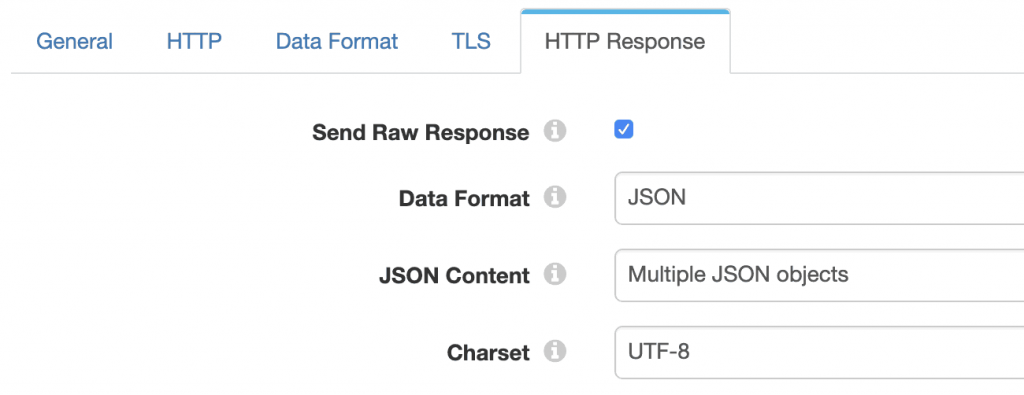
As mentioned above, the Send Raw Response must be enabled in the HTTP Response tab; we’re returning rich content to Slack, which requires the JSON data format:
Next, the Jython Evaluator verifies the signature according to the mechanism provided by Slack. The code is actually quite straightforward:
import hmac
import hashlib
for record in records:
try:
# Slack signing secret is a runtime parameter
slack_signing_secret = '${SLACK_SIGNING_SECRET}'
# The HTTP POST payload is in the /text field
request_body = record.value['text']
# HTTP headers are available as record header attributes
timestamp = record.attributes['X-Slack-Request-Timestamp']
# Construct the data to be signed according to Slack's instructions
sig_basestring = 'v0:' + timestamp + ':' + request_body
# Compute a SHA-256 HMAC using the Slack signing secret
digest_maker = hmac.new(str(slack_signing_secret), msg=str(sig_basestring), digestmod=hashlib.sha256)
computed_signature = 'v0=' + digest_maker.hexdigest()
# If the computed signature matches the one in the incoming request, we're good
record.attributes['signatureValid'] = ('true'
if (computed_signature == str(record.attributes['X-Slack-Signature']))
else 'false')
# Write record to processor output
output.write(record)
except Exception as e:
# Send record to error
error.write(record, str(e))
As noted in the code, SLACK_SIGNING_SECRET is configured as a runtime parameter, along with the parameters we will need for the database lookup:

Since Slack also sends details of the user that invoked the command, you have the opportunity to perform additional authorization in the pipeline – for example, you might have a database table containing the ids of users authorized to invoke the slash command.
After the Jython script runs, a Stream Selector sends records fulfilling the condition ${record:attribute('signatureValid') == 'true'} for further processing, while records that fail the test have all of their fields removed and result in a 403 Forbidden response being returned to the client.
Valid requests are parsed by the Expression Evaluator using the str:splitKV() Expression Language (EL) function.

splitKV takes a delimited set of key-value pairs, such as an HTTP form POST payload, and splits it into a key-value map. For instance the input
firstName=Bob&lastName=Todd
is split into
firstName: "Bob" lastName: "Todd"
Since HTTP form parameters are URL-encoded, we URL-decode the /text field. This is not crucial for this example, but is essential if your command text contains characters such as spaces or percent signs.
Now the JDBC Lookup processor can lookup the part number in the database. The SQL query is very straightforward:
SELECT item_name FROM stock_item WHERE item_number = '${record:value('/item_number')}'
If a matching stock item is found, them the /item_name record field will be populated. The second Stream Selector tests for the existence of the field with this expression:
${record:exists('/item_name')}
If the /item_name field does exist, then the upper Expression Evaluator builds the response:
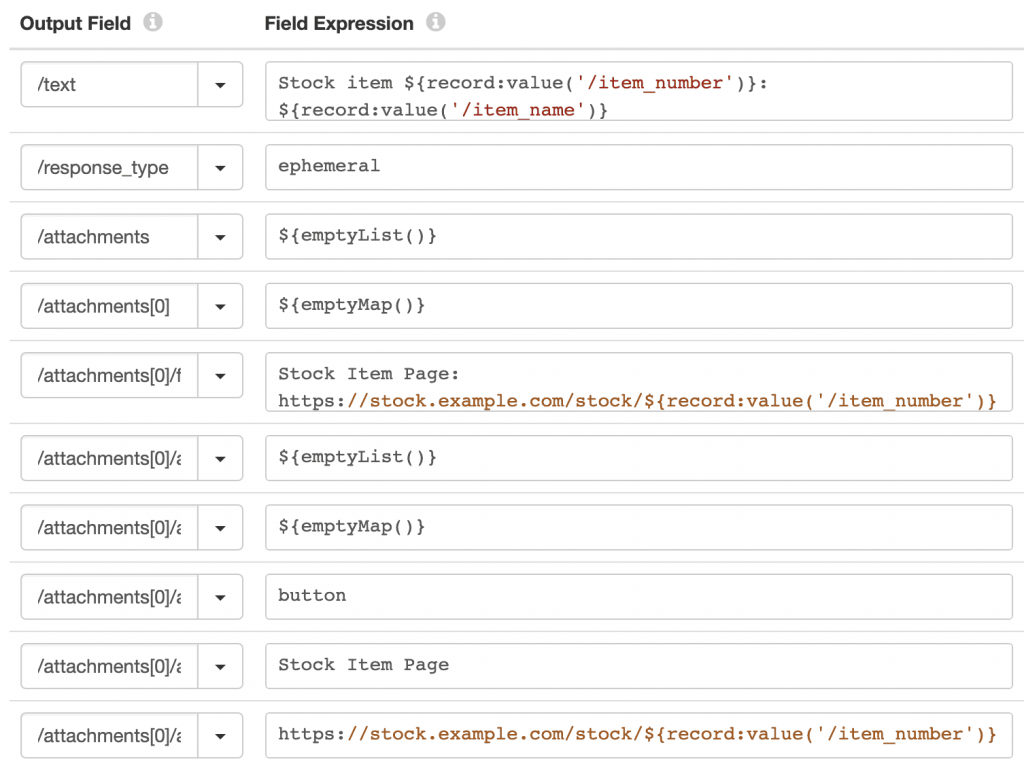
Note the use of emptyList() and emptyMap() to build the required field hierarchy.
If the item isn’t found, then the lower expression evaluator sets an error message:

The last step before returning the response is to remove all fields except the three that Slack is expecting:
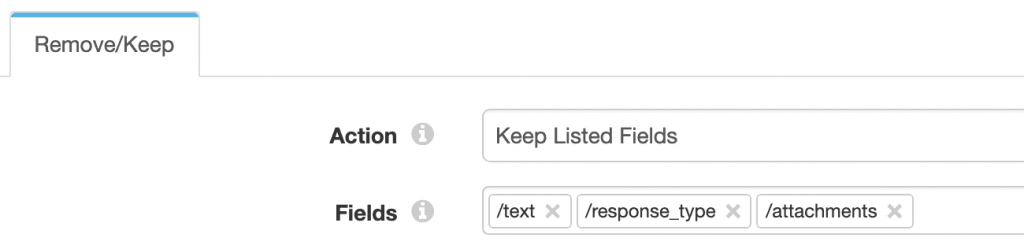
Finally, the ‘200 OK’ Send Response to Origin destination returns the record to the origin as a JSON object, along with a 200 HTTP status code indicating success.
We can test the pipeline with a simple Python script:
import hmac
import hashlib
import requests
import time
import urllib
import json
import sys
slack_signing_secret = 'DUMMY_SLACK_SECRET'
params = {
'token' : 'DUMMY_TOKEN',
'team_id' : 'T0001',
'team_domain' : 'example',
'enterprise_id' : 'E0001',
'enterprise_name' : 'StreamSets, Inc',
'channel_id' : 'C1234567890',
'channel_name' : 'test',
'user_id' : 'UABCDEFGH',
'user_name' : 'Bob',
'command' : '/stock',
'text' : sys.argv[1],
'response_url' : 'https://hooks.slack.com/commands/1234/5678',
'trigger_id' : '13345224609.738474920.8088930838d88f008e0'
}
timestamp = str(int(time.time()))
request_body = urllib.urlencode(params)
sig_basestring = str('v0:' + timestamp + ':' + request_body)
digest_maker = hmac.new(slack_signing_secret, msg=sig_basestring, digestmod=hashlib.sha256)
signature = 'v0=' + digest_maker.hexdigest()
headers = {
'X-Slack-Request-Timestamp' : timestamp,
'X-Slack-Signature' : signature
}
r = requests.post("http://localhost:8888/?sdcApplicationId=bob", data=request_body, headers=headers)
print("Status code: " + str(r.status_code))
print("Payload: " + json.dumps(json.loads(r.text), indent=2))
After setting the SLACK_SIGNING_SECRET runtime parameter to DUMMY_SLACK_SECRET and running the pipeline, we can run the test script:
$ python2.7 ~/Documents/slack_request.py 25276002
Status code: 200
Payload: {
"text": "Stock item 25276002: Aerodynamic Steel Hat",
"response_type": "ephemeral",
"attachments": [
{
"fallback": "Stock Item Page: https://stock.example.com/stock/25276002",
"actions": [
{
"url": "https://stock.example.com/stock/25276002",
"text": "Stock Item Page",
"type": "button"
}
]
}
]
}
Success!
Registering Your Slash Command Endpoint in Slack
The Slack API documentation explains how to set up a slash command as a Slack app – you’ll need to supply the name of the command, its URL, description etc. Once you’ve created the Slack app, you can copy its Signing Secret and paste it into the pipeline’s runtime parameters.
Putting it All Together
You can see the slash command in action in this short video:
Conclusion
With StreamSets Data Collector 3.8.0 you can implement arbitrary REST APIs as microservice pipelines. You can use standard processors to lookup data and manipulate record fields, while script evaluators can implement custom logic such as validating request signatures. Data Collector is Apache 2.0 licensed open source, so download it today and get started building your own microservice pipelines. Leave a comment to let us know what you come up with!
Attending the Strata Data Conference this week in San Francisco? Come visit the StreamSets team at booth 1231 in the expo!