![]() When you’re building a pipeline with StreamSets Data Collector (SDC), you can often implement the data transformations you require using a combination of ‘off-the-shelf’ processors. Sometimes, though, you need to write some code. The script evaluators included with SDC allow you to manipulate records in Groovy, JavaScript and Jython (an implementation of Python integrated with the Java platform). You can usually achieve your goal using built-in scripting functions, as in the credit card issuing network computation shown in the SDC tutorial, but, again, sometimes you need to go a little further. For example, a member of the StreamSets community Slack channel recently asked about computing SHA-3 digests in JavaScript. In this blog entry I’ll show you how to do just this from Groovy, JavaScript and Jython.
When you’re building a pipeline with StreamSets Data Collector (SDC), you can often implement the data transformations you require using a combination of ‘off-the-shelf’ processors. Sometimes, though, you need to write some code. The script evaluators included with SDC allow you to manipulate records in Groovy, JavaScript and Jython (an implementation of Python integrated with the Java platform). You can usually achieve your goal using built-in scripting functions, as in the credit card issuing network computation shown in the SDC tutorial, but, again, sometimes you need to go a little further. For example, a member of the StreamSets community Slack channel recently asked about computing SHA-3 digests in JavaScript. In this blog entry I’ll show you how to do just this from Groovy, JavaScript and Jython.
Scripting on the JVM
The SDC script evaluators are implemented using the Java Scripting API defined by JSR-223, the specification for how scripts run in a JVM. It’s the Java Scripting API that enables SDC to expose objects to your scripts such as records, state and log. The Java Scripting API also allows your scripts to access arbitrary Java code from external JARs.
Let’s take SHA-3 as our example. The Bouncy Castle Crypto APIs for Java include SHA-3, and much more. It’s a snap to compute a SHA-3 hash in Java – just include the Bouncy Castle JAR and do:
// One time
SHA3.DigestSHA3 sha3 = new SHA3.DigestSHA3(256);
// As often as you like - just reset sha3 before each digest
sha3.reset();
byte[] digest = sha3.digest(inputString.getBytes("UTF-8"));
System.out.println(Hex.toHexString(digest));
Running this on an input of "abc" results in a hex-encoded digest value of "3a985da74fe225b2045c172d6bd390bd855f086e3e9d525b46bfe24511431532".
Let’s see how to do the same from Groovy, JavaScript and Jython.
Calling External Java Code from Groovy
The first step is to follow the SDC documentation for including external libraries. Establish a base directory for external libraries – I’ll use /opt/sdc-extras as an example, but you can put it anywhere you like as long as it’s outside SDC’s directory tree. Where the documentation tells you to create a specific subdirectory for the stage, you’ll need to create /opt/sdc-extras/streamsets-datacollector-groovy_2_4-lib/lib/. Make sure you edit SDC’s environment and security policy configuration files to set STREAMSETS_LIBRARIES_EXTRA_DIR and the security policy for external libraries. Note also that, if you’re starting SDC as a service, you should set the STREAMSETS_LIBRARIES_EXTRA_DIR environment variable in libexec/sdcd-env.sh, otherwise, if you’re running bin/streamsets dc interactively, set it in libexec/sdc-env.sh.
Now download the Bouncy Castle provider jar file (currently bcprov-jdk15on-155.jar) and put it in the Groovy external libs subdirectory, /opt/sdc-extras/streamsets-datacollector-groovy_2_4-lib/lib/. Restart SDC, and create a test pipeline.
Drag a Dev Raw Data Source onto the pipeline canvas, and configure it with JSON data format and the following raw data:
{ "data" : "abc" }
{ "data" : "" }
{ "data" : "abcdbcdecdefdefgefghfghighijhijkijkljklmklmnlmnomnopnopq" }
{ "data" : "abcdefghbcdefghicdefghijdefghijkefghijklfghijklmghijklmnhijklmnoijklmnopjklmnopqklmnopqrlmnopqrsmnopqrstnopqrstu" }
Now add a Groovy Evaluator and paste in this script:
import org.bouncycastle.jcajce.provider.digest.SHA3
// Only need a single SHA3 instance
if (!state['sha3']) {
state['sha3'] = new SHA3.DigestSHA3(256)
}
SHA3.DigestSHA3 sha3 = state['sha3'];
for (record in records) {
try {
// Need to reset the SHA3 instance for every field we digest
sha3.reset()
byte[] digest = sha3.digest(record.value['data'].getBytes("UTF-8"))
record.value['digest'] = digest.encodeHex().toString()
output.write(record)
} catch (e) {
// Write a record to the error pipeline
log.error(e.toString(), e)
error.write(record, e.toString())
}
}
There are a few useful techniques here. First, we import the Bouncy Castle SHA3 class exactly like the Java sample. We can use the same SHA3 instance for every hash we compute, so we only need to create a single instance, and keep it in the state object. We retrieve the SHA3 instance from the state map before looping through the records, to minimize the work done in the loop. Since we’re reusing the same SHA3 instance, we need to reset it before computing a new hash. After that, it’s just a case of calling the digest() method on the input field’s bytes, hex encoding the resulting byte array, and putting it in the digest field of the record.
Preview the pipeline, click on the Groovy Evaluator, and you should see that the digests of the various sample input values.
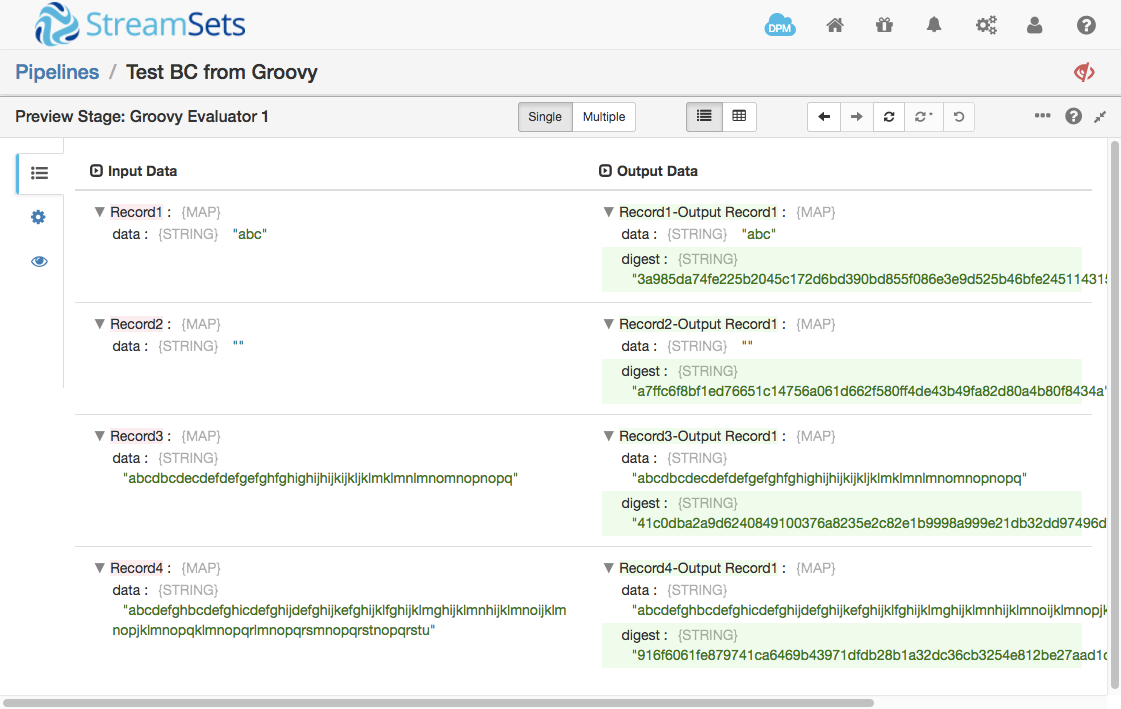
You can check the results against this handy list of SHA test vectors – thanks, DI Management!
Calling External Java Code from JavaScript
The process is very similar in JavaScript, with a couple of exceptions. The Bouncy Castle jar file needs to go in /opt/sdc-extras/streamsets-datacollector-basic-lib/lib/, since the JavaScript Evaluator is included in SDC’s basic stage library.
The JavaScript is very similar to the Groovy, except it uses the hex encoder from Bouncy Castle, since there is no native encoder in JavaScript.
// Only need single SHA3, Hex instances
if (!state.sha3 || !state.Hex) {
var DigestSHA3 = Java.type('org.bouncycastle.jcajce.provider.digest.SHA3.DigestSHA3');
state.sha3 = new DigestSHA3(256);
state.Hex = Java.type('org.bouncycastle.util.encoders.Hex');
}
var sha3 = state.sha3;
var Hex = state.Hex;
for(var i = 0; i < records.length; i++) {
var record = records[i];
try {
// Need to reset the message digest object for every field!
sha3.reset();
var digest = sha3.digest(record.value['data'].getBytes('UTF-8'));
record.value.digest = Hex.toHexString(digest);
output.write(record);
} catch (e) {
// Send record to error
error.write(record, e);
}
}
I used the same techniques here as in the Groovy example – caching objects in state, assigning local variables to minimize the work done in the record loop, and resetting the sha3 instance for each digest.
The Java SE 8 documentation provides further information on calling Java from JavaScript.
Calling External Java Code from Jython
Again, the process is very similar to Groovy. Put the Bouncy Castle jar file in /opt/sdc-extras/streamsets-datacollector-jython_2_7-lib/lib/, and use the following script:
from org.python.core.util import StringUtil
from org.bouncycastle.jcajce.provider.digest.SHA3 import DigestSHA3
import binascii
# Only need a single SHA3 instance
if ('sha3' not in state):
state['sha3'] = DigestSHA3(256)
sha3 = state['sha3']
for record in records:
try:
# Need to reset the message digest object for every field!
sha3.reset()
digest = sha3.digest(StringUtil.toBytes(record.value['data']))
record.value['digest'] = binascii.hexlify(digest)
output.write(record)
except Exception as e:
# Send record to error
error.write(record, str(e))
The principles are exactly the same as for Groovy and JavaScript – use state to cache long-lived objects, minimize processing within the loop, and remember to reset the SHA3 digest before each use.
You can find more information on calling Java from Jython in the Jython User Guide.
Performance
With the same functionality implemented in three script evaluators, a natural question is, “Which is fastest?” I added a Trash Destination to each pipeline and ran a quick test on my 8GB MacBook Air. To remove any effects of loading the script engines into memory I first started the pipeline, let it run for a minute, and stopped it. I then restarted it and let it run for a second minute, measuring the record throughput from the second run. Figures are in records/second – don’t consider this a scientific test of SDC performance – my heavily loaded laptop is not a representative testbed; rather, focus on the relative numbers for the three evaluators:
| Groovy | 1000 |
| JavaScript | 750 |
| Jython | 650 |
A clear win for Groovy, likely due to its tighter coupling to the JVM.
For comparison, I coded a Custom Processor in Java to do the same job; it was able to process 1800 records/second. See the custom processor tutorial if you want to go down this road.
External Script Code
A related topic is “How do I call external Groovy/JavaScript/Jython code from my script?” Since external jar files are already compiled into bytecode, performance is *much* better calling Java libraries than external script code – a JavaScript implementation of SHA-3 processed only 200 records/second on my laptop. Having said that, there are some rare occasions when the functionality you need is only available in your scripting language. I’ll cover external script code in a future blog entry.
Conclusion
StreamSets Data Collector‘s use of the Java Scripting API allows you to call existing Java code from your scripts, running in any of the Groovy, JavaScript or Jython Evaluators. It’s straightforward to import and call Java code from any of the scripting languages, and, while native Java code gives you the ultimate in performance, the Script Evaluator gives you flexibility to iterate on your code much more quickly than a custom processor’s build/copy/restart/run loop, and has clear benefits if you’re more comfortable working in Groovy, JavaScript or Jython rather than Java. One final note – the code in this article was all developed and tested on JDK 8. If you are not yet running SDC on JDK 8, you should strongly consider migrating, as JDK 7 is in the end-of-life process, and deprecated in SDC as of version 2.2.0.0.