 I’m frequently asked, ‘How does StreamSets Data Collector integrate with Spark Streaming? How about on Databricks?’. In this blog entry, I’ll explain how to use Data Collector to ingest data into a Spark Streaming app running on Databricks, but the principles apply to Spark apps running anywhere. This is one solution for continuous data integration that can be used in cloud data platforms.
I’m frequently asked, ‘How does StreamSets Data Collector integrate with Spark Streaming? How about on Databricks?’. In this blog entry, I’ll explain how to use Data Collector to ingest data into a Spark Streaming app running on Databricks, but the principles apply to Spark apps running anywhere. This is one solution for continuous data integration that can be used in cloud data platforms.
Databricks is a cloud-based data platform powered by Apache Spark. You can spin up a cluster, upload your code, and run jobs via a browser-based UI or REST API. Databricks integrates with Amazon S3 for storage – you can mount S3 buckets into the Databricks File System (DBFS) and read the data into your Spark app as if it were on the local disk. With this in mind, I built a simple demo to show how SDC’s S3 support allows you to feed files to Databricks and retrieve your Spark Streaming app’s output.
I started with the works of Shakespeare, split into four files – the comedies, histories, poems and tragedies. I wanted to run them through a simple Spark Streaming word count app, written in Python, running remotely on Databricks. Here’s the app:
# Databricks notebook initializes sc as Spark Context
from pyspark.streaming import StreamingContext
from uuid import uuid4
batchIntervalSeconds = 10
inputDir = '/mnt/input/shakespeare/'
outputDir = '/mnt/output/counts/'
def creatingFunc():
ssc = StreamingContext(sc, batchIntervalSeconds)
def saveRDD(rdd):
if not rdd.isEmpty():
rdd.saveAsTextFile(outputDir + uuid4().hex)
lines = ssc.textFileStream(inputDir)
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.foreachRDD(saveRDD)
return ssc
# Start the app
ssc = StreamingContext.getActiveOrCreate(None, creatingFunc)
ssc.start()
# Wait a few seconds for the app to get started
ssc.awaitTerminationOrTimeout(batchIntervalSeconds * 2)
If you’ve already run a simple word count app like this yourself, you’ll have noticed that it considers punctuation part of the adjacent word – for example, the final word of “To be or not to be,” will be counted as “be,” rather than “be”. This is pretty annoying when you’re analyzing the results, so let’s use Data Collector to remove punctuation as we ingest the text, as well as removing any empty lines:
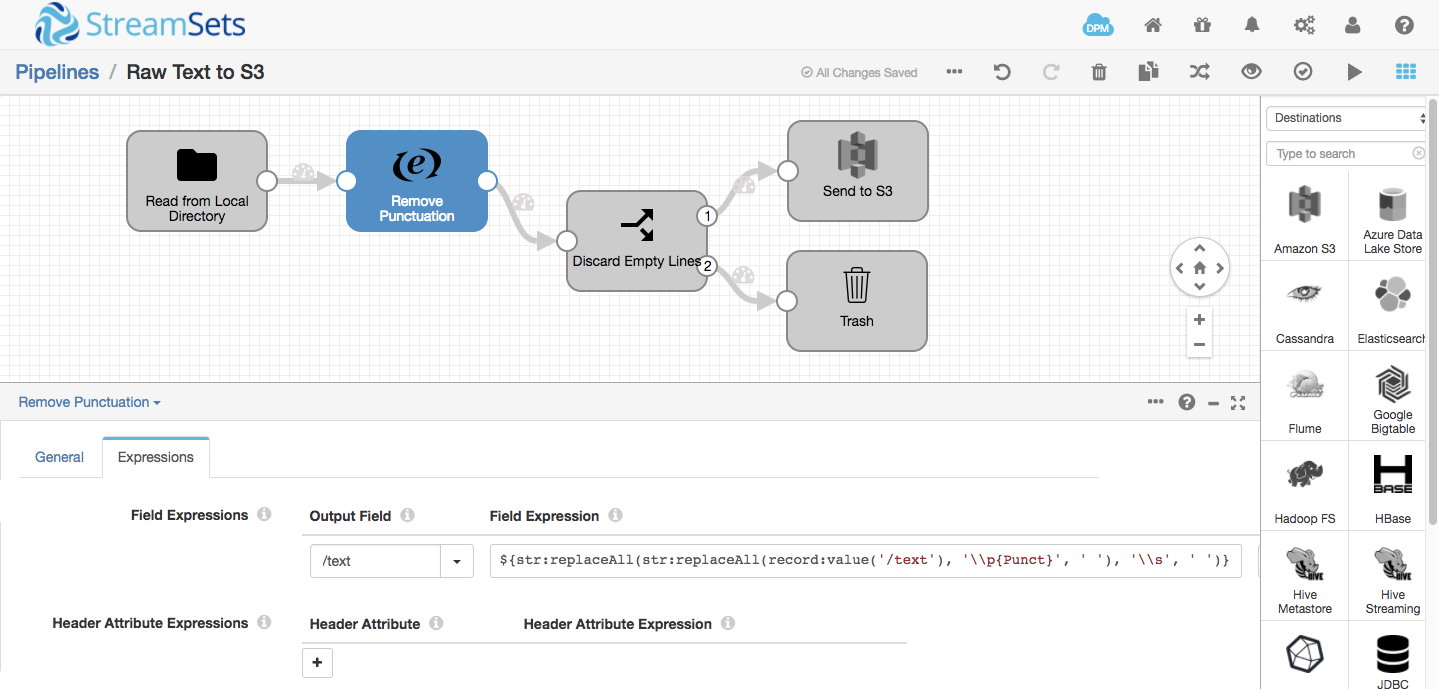
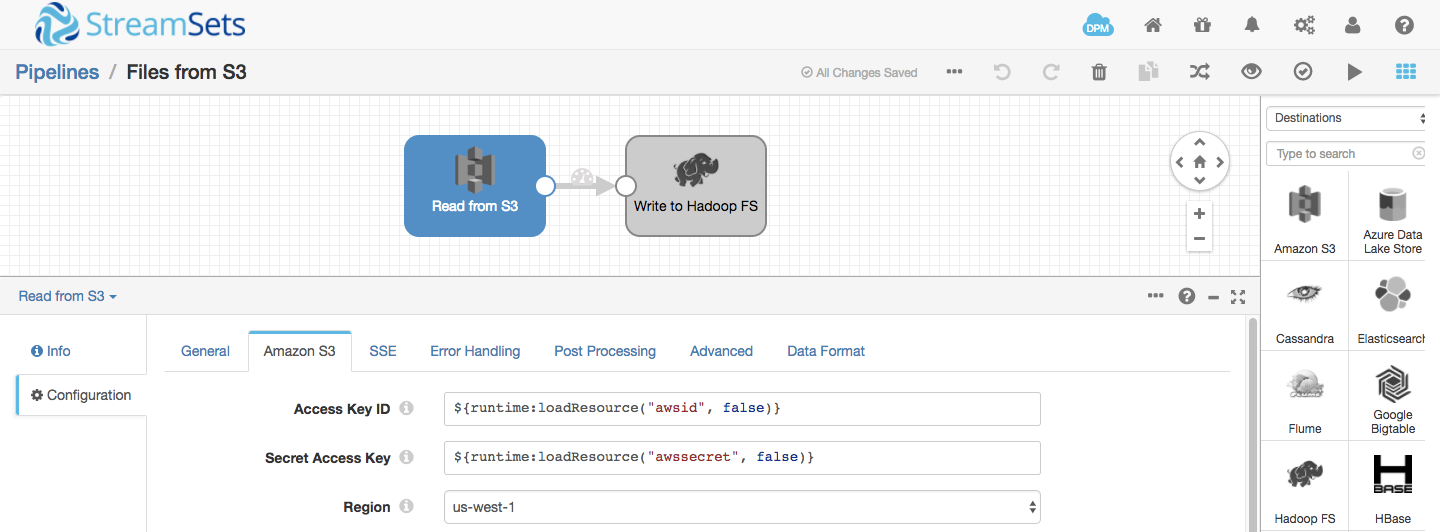
The pipeline reads files from a local directory and writes to an S3 bucket that is mounted in DBFS at /mnt/input. Note that you must start the Spark Streaming app before you move any data to its input directory, as it will ignore any preexisting files. I mounted a second S3 bucket to /mnt/output; the word count app writes its results to the output directory; a second pipeline retrieves files from the output S3 bucket, writing them into Hadoop FS:
With the app and both pipelines running, the system works like this:
- I drop one or more files into a local directory
- The first SDC pipeline reads them in, removing punctuation and empty lines, and writes the resulting text to S3
- The Spark Streaming app reads the text from DBFS, runs word count, and writes its results to DBFS
- The second SDC pipeline reads files as they appear in S3, writing them to Hadoop FS

I walk through the process in this short video:
Databricks offers a Community Edition as well as a trial of their full platform; StreamSets Data Collector is free to download, so you can easily replicate this setup for yourself.
What data are you processing with Spark Streaming? Let us know in the comments!