Download and Install or Deploy StreamSets Data Collector
How to easily move data between any source and destination
Install or Deploy StreamSets Data Collector Engine
The StreamSets Data Collector engine is a key, integrated component within the StreamSets Platform. The StreamSets Data Integration Platform is where you develop, manage and monitor your data pipelines, and is available as a SaaS. StreamSets Data Collector is one of the pipeline execution engines that is managed by the platform and which actually executes the pipeline.
To get started, sign up for and log into the StreamSets Platform (it’s free!) From there you can set up the Data Collector engine in a variety of ways depending on your use case and your environment. StreamSets makes it easy for you to deploy the Data Collector engine wherever you need, on-premises, in a VPC or in the public cloud– to support the breadth of pipeline patterns across hybrid, multi-cloud environments.
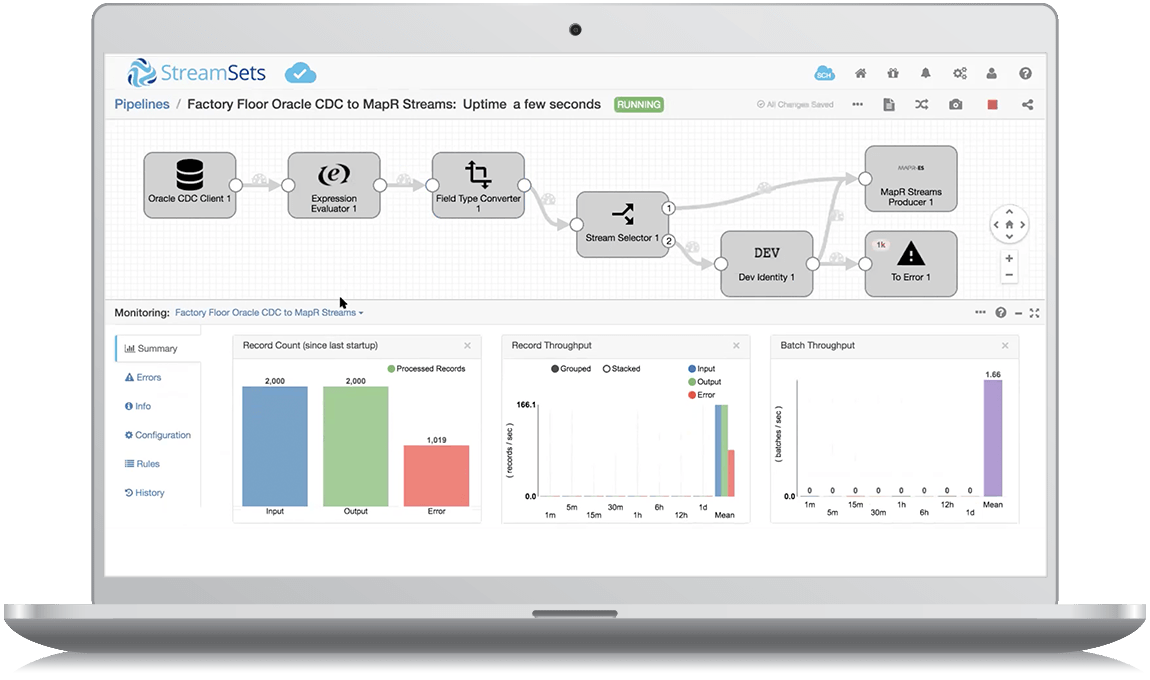
You can choose from a variety of methods to deploy a Data Collector engine–
either download and install, or deploy in the cloud.
- Option A: download the StreamSets Data Collector Docker image, and use Docker to run the Data Collector engine on your local machine, on-premises or in your VPC. This is a self-managed deployment, meaning you are taking full control of procuring the resources to run the engines. The StreamSets Data Collector Docker image download is available from within the StreamSets Data Integration Platform.
- Option B: download the StreamSets Data Collector engine Tarball and install Data Collector on your local machine, on-premises or in your VPC. The StreamSets Data Collector download tarball is available from within the StreamSets Data Integration Platform.
- Option C: use StreamSets Platform to automatically provision a Data Collector engine and the associated resources required to run the engine in your choice of cloud service provider– AWS EC2, Azure VM or GCE— in just a few minutes. This allows you to easily set up and manage a cloud instance of the StreamSets Data Collector engine in your own cloud namespace. The StreamSets Data Integration Platform does the hard work of ensuring that the resources meet the engine requirements, and automatically deploying and launching your Data Collector engine on those resources.
After your engine deployment is set up, you can start building your smart data pipeline in the StreamSets Platform. You can then execute your pipeline using your new StreamSets Data Collector engine.




Getting Started Videos
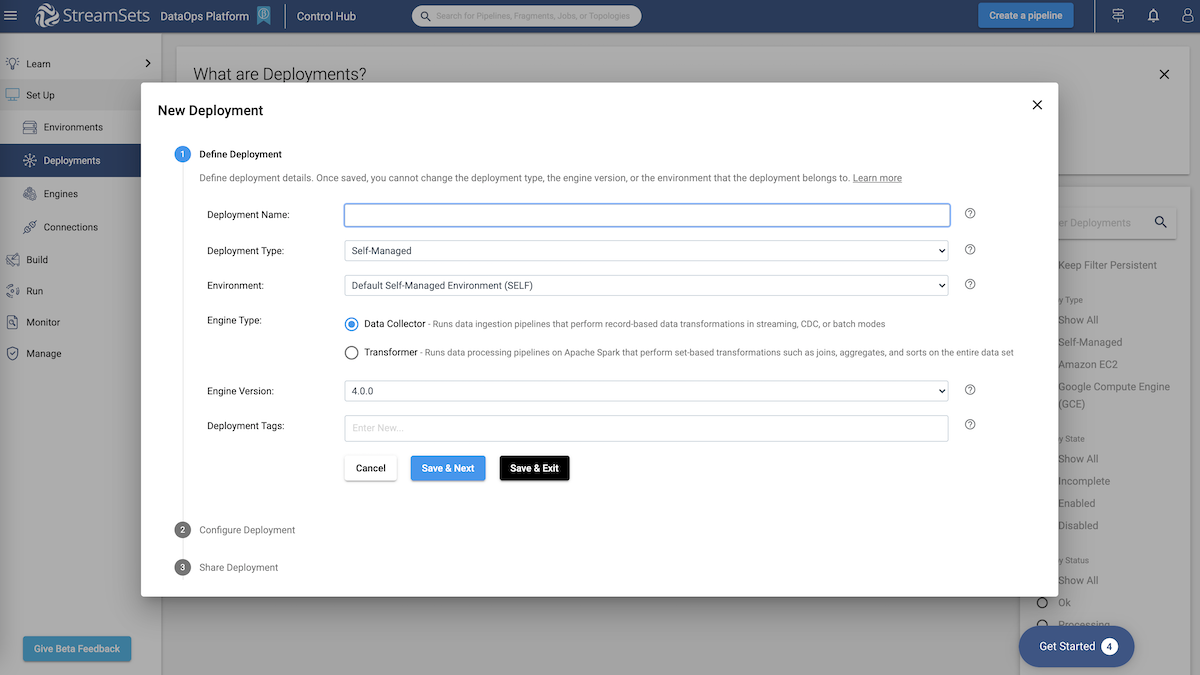
Here is where you will define your StreamSets engine and set configurations.
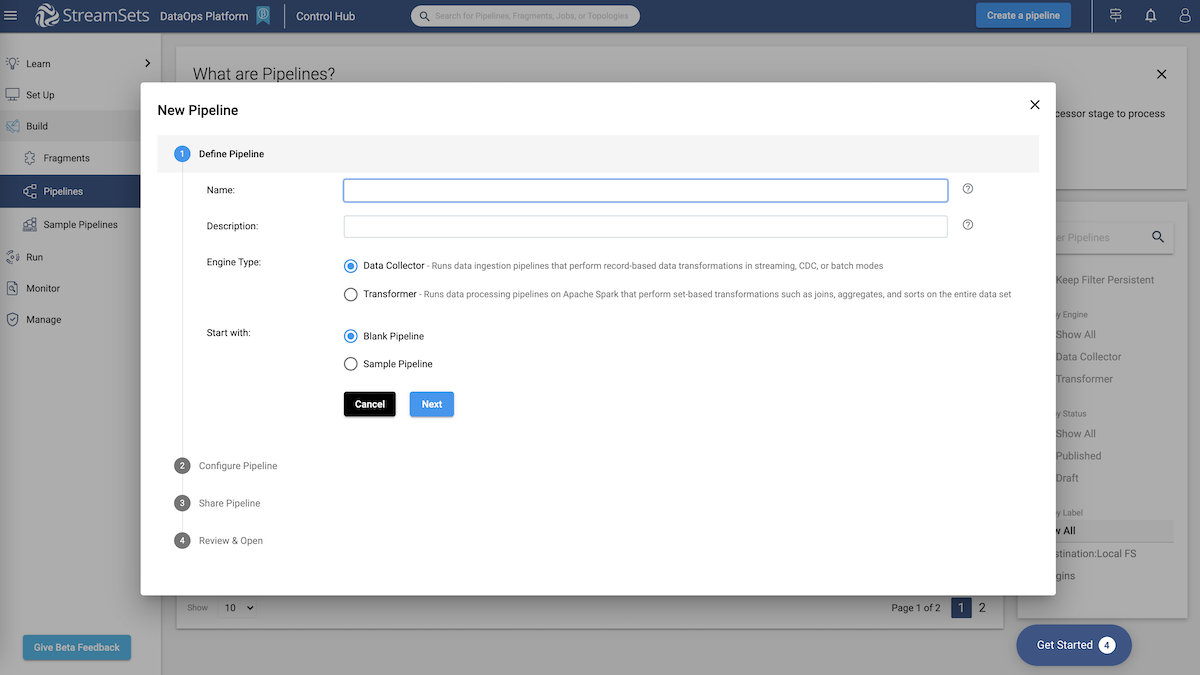
Use the drag and drop functionality and pre-built processors.
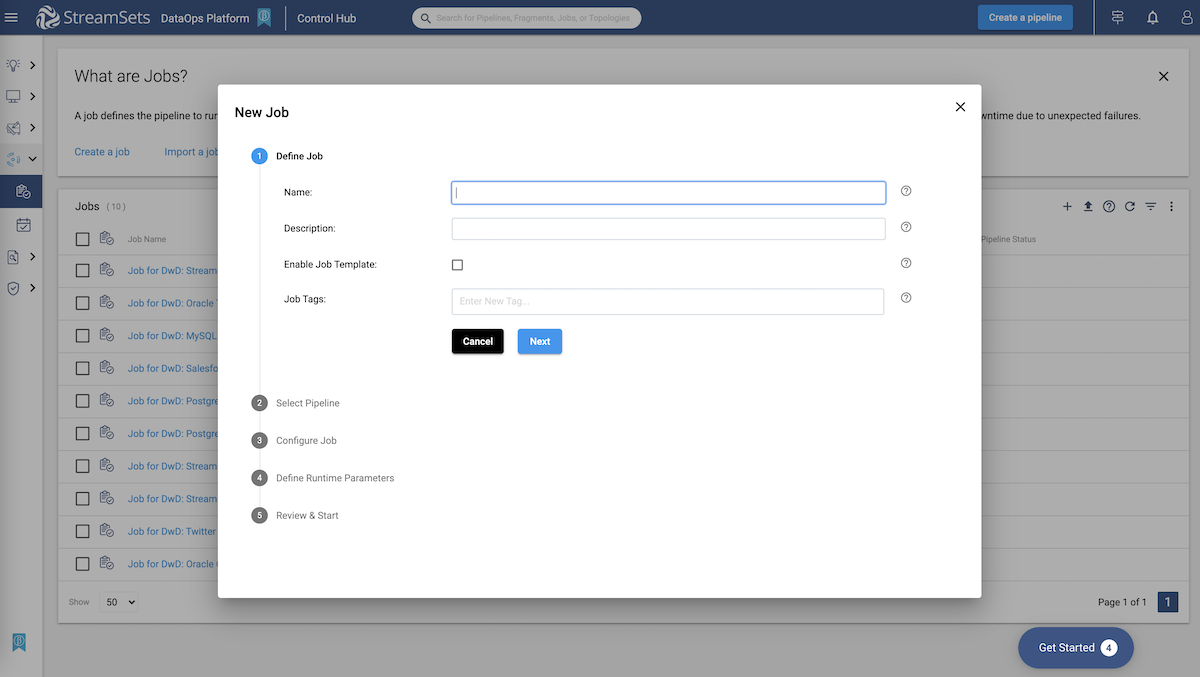
Check your pipeline configurations and you’re ready to start processing.
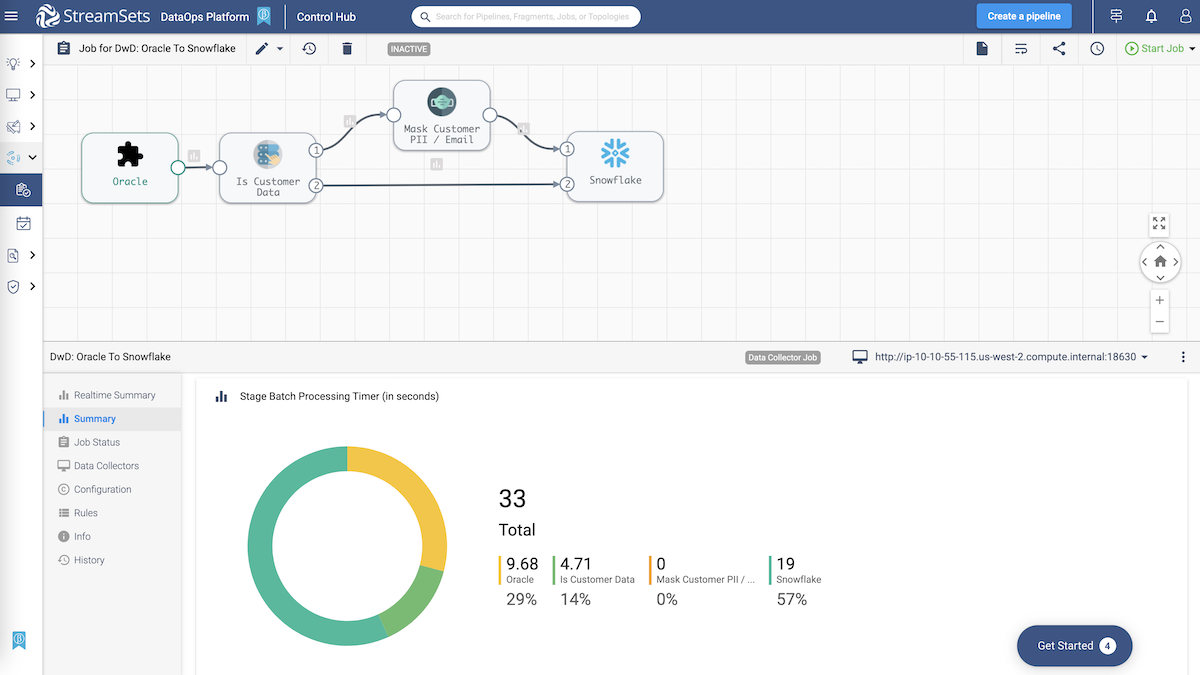
Review the status, monitor the outcome and analyze.
Check out more demos and see the StreamSets Data Integration Platform live in action.
What Is a Data Collector?
The StreamSets Data Collector engine is a powerful execution engine used to ingest and process data in batch, streaming, or CDC pipelines, and is a core part of the StreamSets Platform.
You can install and deploy Data Collector engines anywhere you need to ingest data, on-premises or in the cloud. You can download and install the Data Collector engine, or let the StreamSets Platform auto-deploy it in AWS, Azure or GCP. Either way, the Data Collector engine will be managed from the StreamSets Platform. Use the pre-built connectors and native integrations to configure your smart data pipeline without coding. With smart data pipelines, you can spend more time building new data pipelines and less time rewriting and fixing old pipelines.
Where is the StreamSets download? Where is the Data Collector download?
For those who may have been used to downloading StreamSets Control Hub as well as engines in the past, StreamSets has evolved the Platform to function natively in the cloud. The StreamSets Platform is a cloud-native SaaS that you can simply log into. From within the StreamSets Platform, you can then choose how you want to deploy your Data Collector engine– download and install yourself, or use the auto-provisioning capabilities of the StreamSets Platform to deploy the cloud.