The rise in digital engagement has increased the amount of data generated, growing to 181 zettabytes by 2025 from 97 zettabytes in 2022. As this data is stored in storage solutions like databases, there’s a need to structure and organize the data for easy access for performing processes like data federation, integration, and migration. The organization and structuring of database data and other entities follows a database schema.
This organization includes arranging database entities like field names, tables, and data types and how these entities relate. A database schema acts as the reference map for your data professionals, providing a picture that helps them to model and navigate data structures for finding useful and existing data relationships for business insights.
This article discusses database schema, its types, some principles to follow in database schema design, and how StreamSets helps abstract database schema thinking from your data processes.
What Is a Database Schema?
Although one can describe the database schema as the map or layout of a database, it doesn’t contain data but instead, can determine the efficiency and performance of your database operations.
Besides ensuring effective business data communication to database users and internal stakeholders, schema design could also ensure data safety and security by incorporating security measures like authentication and access control into your database. For example, sensitive or protected data could be held in a separate schema with limited access.
Database schema follows a design process called data modeling and falls into three different types:
- Conceptual data model: This represents the whiteboard model and usually gives an overview of what the schema will contain. The conceptual model is often the first step in database design and captures all the data, attributes, and relationships between the data. This conceptual model provides a picture of the ‘what’ in schema design rather than about the model implementation.
- Logical data model: This model is more detailed than the conceptual model and visualizes your data entities, attributes, and relationships. For example, this step may involve defining the tables for a relational database and the collections present if you choose a document database.
- Physical data model: This last step implements the technical details described in the logical data model. It is more complex and involves building these structures in the database itself.
What Are the Types of Database Schema?
Database schemas have different classes based on the interactions with the data:
- Relational model: Objects in a relational database have attributes as columns, and in an ideal example of this model every row represents records represented using a unique ID/key. These unique keys make it easy to identify and establish relationships with other tables. One everyday use for the relational database model is connecting customer records and transactions, as banks use. However, this model has limited flexibility, requiring predefining structures and relationships.
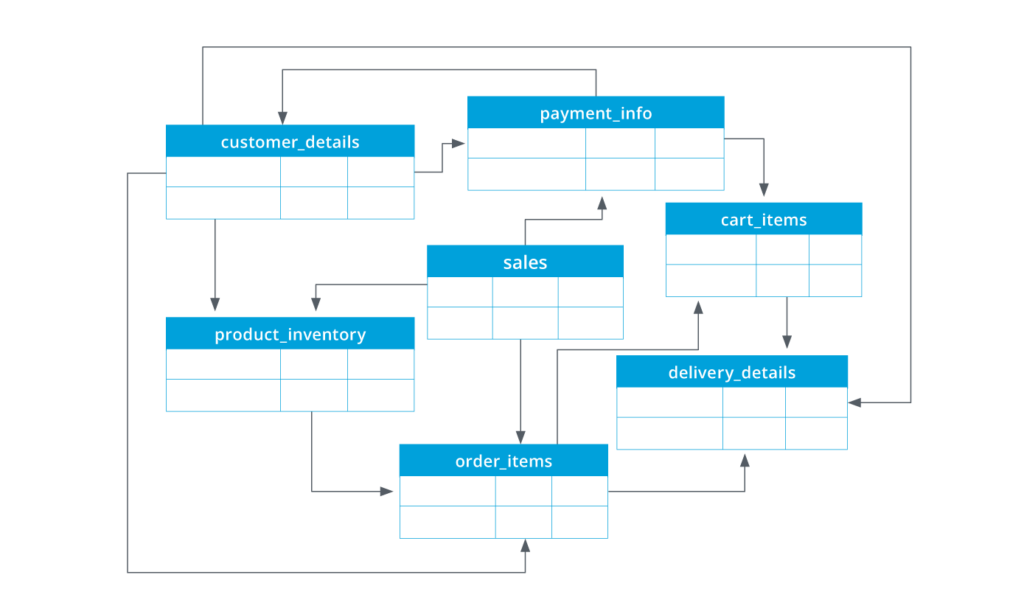
A relational database model has no central or fact table but numerous tables that relate to each other in multiple ways. For example, the model above shows numerous tables connected.
- Hierarchical model: This schema model contains a root table connected to multiple child tables.
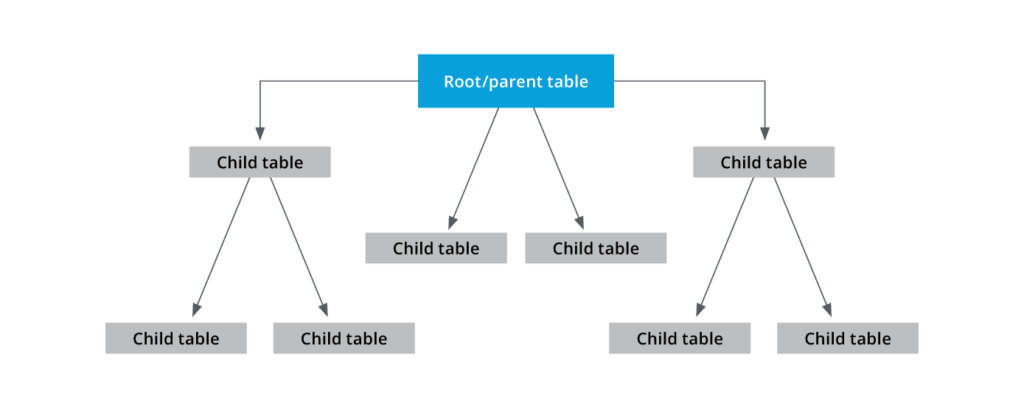
A hierarchical model helps with the quick retrieval and deletion of records. Although a parent table in this model can have multiple child tables, every child table must have a single-parent table. The limited relationship between child and parent nodes limits the flexibility and one-to-many relationships as observed in relational databases. Retrieving records in this model involves navigating the entire tree structure, starting at the root table.
- Flat model: The flat schema is ideal for simple applications that involve simple record-keeping without complex business relationships. A flat model contains a single table where all records are stored as single rows and separated by delimiters like a comma. This model cannot be indexed and queried as all the data exists in isolation.

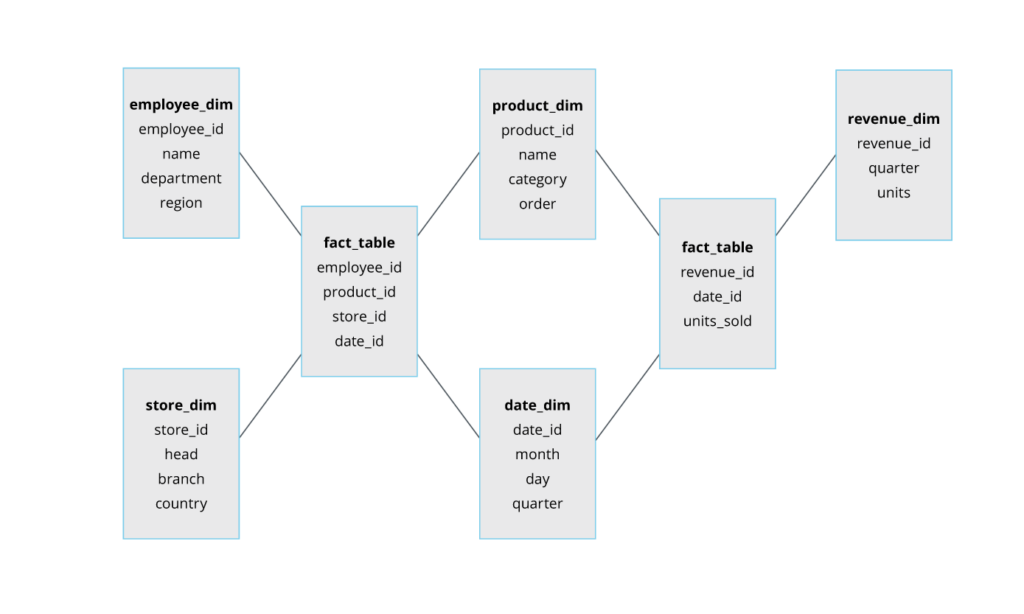
- Star: This schema is commonly used for modeling data in dimensional data marts and warehouses. This schema contains a single fact connected to multiple dimension tables. A fact table represents business facts, while the dimension tables have more information about the data in the fact table.
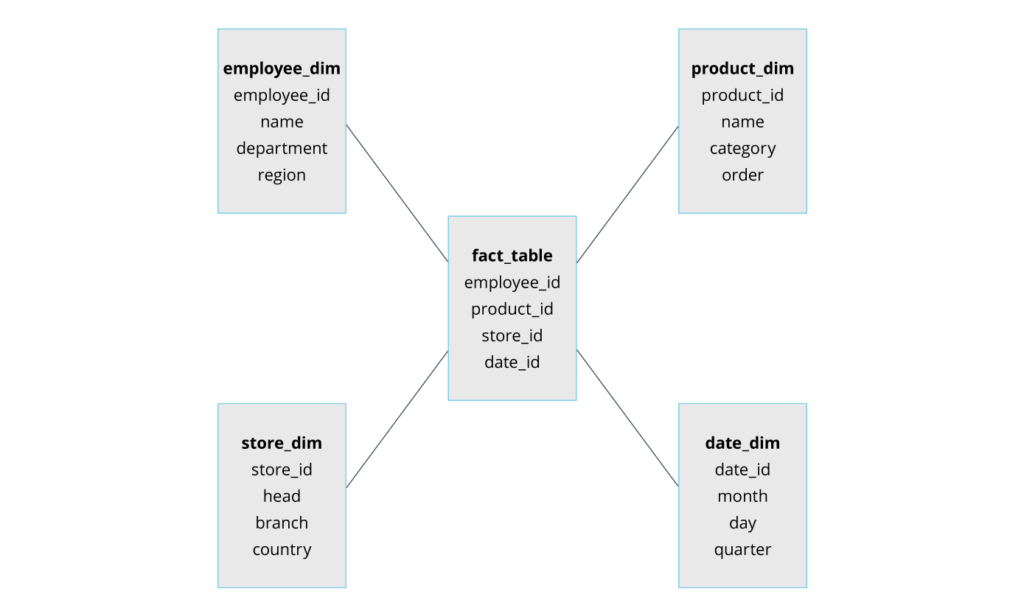
The star schema offers simplicity and a single granularity level, reducing the number of joins required for running queries. However, it can be rigid and difficult to extend the schema if the business needs change; hence, it’s ideal for data marts with simple data relationships.
- Snowflake: Another schema commonly used in data warehouses, the Snowflake schema closely resembles the star schema and is employed for complex queries and advanced analytics. Like the star schema, the snowflake schema has a single fact table connected to multiple dimension tables, but these dimension tables link to other related tables.
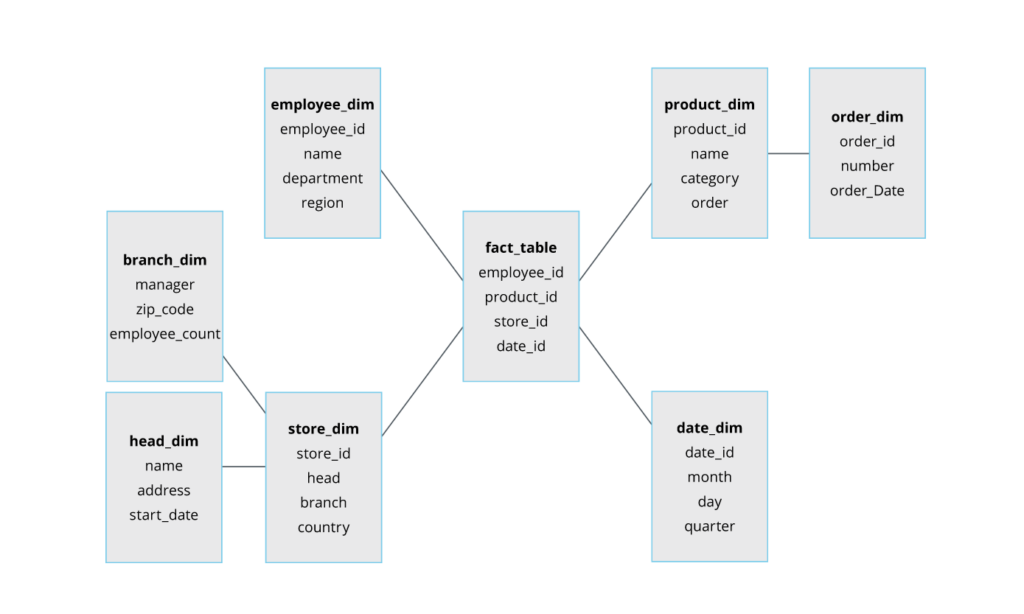
This further branched-out relationship from the dimension tables to other tables creates the snowflake structure. The normalized Snowflake schema allows storing more data with less storage space and is excellent for performing complex queries and aggregations. However, running queries may involve complex joins, slowing query performance.
- Galaxy: Also called the fact constellation schema, the galaxy schema has multiple fact tables connected to multiple dimension tables. The arrangement of these multiple fact tables shared with dimension tables creates a star-shaped structure. The complexity of this schema makes it challenging to maintain.
Principles of Database Schema Design
Database schema design refers to the steps, processes, and strategies employed for creating a clean, efficient, and consistent database schema that facilitates easy data lookup and retrieval for data consumption, manipulation, and interpretation. Here are some best practices to follow when embarking on your schema design:
Know Your Business Problem
The database schema provides a clear picture of what’s present in your database and the relationships between the data records. Your business goal may affect your choice of database elements like column and table names and ER (Entity Relationships). For example, large-scale businesses performing large-scale queries will benefit from the reduced storage requirement and complex querying ability offered by Snowflake. In contrast, a simple business application requiring no queries will benefit from a flat schema model. Knowing your business problem and objectives helps you design a schema that best illustrates these relationships and allows analysts, engineers, and other database professionals to work with and manipulate the data.
Use Appropriate Naming Conventions
Your naming conventions strongly affect the quality, latency, and performance of database queries. Some naming principles to take note of include:
- Avoid longer column and table names as it consumes disk space and can reduce query performance. For example, removing unnecessary words or name additions from table and column names is best, like using ProductName instead of NameOfProduct.
- Eliminate hyphens, quotes, spaces, or special characters, which may need additional work during querying or result in invalid results or a syntax error.
- Always specify data types when naming your columns and ensure that the set data type can support every possible value that data presents. For example, choosing an integer type for product price must accommodate every price stipulated.
- Avoid reserved words like select, function, group by, and others in naming to avoid confusion when querying.
- Always spell check. Incorrectly spelled field names can become very difficult to manage.
Enforce Access Control and Authentication for Data Security
Data safety and security for your database are vital to prevent data misuse and leaks. Effective security measures like establishing access control and authentication help ensure that only authorized users can access and manipulate data. Therefore, your schema must allow for various forms of authentication, registering new users and password recovery, and employ hashing or encryption techniques to hide and mask sensitive columns to resist data hacks or leaks and prevent access by unauthorized users.
Document Everything
Apart from the routine database users, there may be a need to communicate your business data with other business stakeholders, hence the need for proper documentation. Proper database design documentation makes it easier for others to understand the composition, structure, functionality, and maintenance steps. However, it is best to know the database audience to prepare valid and useful documentation for consumption.
Normalize Data To Reduce Redundancies
Database operations involving everyday transactions rely on updating, deleting, and inserting data which may encounter errors resulting from inconsistent or repeated data. Redundant/repeated database records are a primary cause of inconsistencies in data, as the same data stored in two locations may result in updates made to one and not the other, affecting analysis results. One important principle to consider during schema design is applying normalization. Normalization helps eliminate repetitive data in your data after defining entities by ensuring every data record is stored exactly once. Normalization behavior depends on the constraints set by your entity form.
Define Entity Relationships With ER Diagrams
A database often contains multiple tables in one or more interactions with each other. Creating various tables in your database without an idea of how they relate to themselves often creates the risk of developing orphan records and no enforcement of referential integrity. Referential integrity ensures that columns in tables having a relationship share some common value. You can illustrate entity relationships with an ER diagram. An ER diagram visualizes relationships between entities in your database and helps engineers or database engineers identify flaws or errors in your schema design before production. In an ERD, a rectangle represents an entity, and a diamond represents a relationship between entities. Table relationships often involve a primary key-foreign key relationship, forming the basis for multi-table querying behavior.
Have a Unique Primary Key
Every table in your database should have a unique identifier — the primary key for identifying rows. The primary key helps analysts better understand your data model and the relationships with other tables. Additionally, the primary key helps improve data integrity and prevents the occurrence of duplicate rows in your table, which may affect query results and cause application errors.
Employ Schema Partitioning for Better Management
Large-scale databases with large schemas can be challenging to access, visualize, and manage, hence the need for a means to ease management, like schema partitioning. Schema partitioning uses partitioning criteria set by the schema designers to divide the data into different sections to be accessed separately. These criteria differ and may include access permissions, range, or usage patterns. For example, partitioning via access permissions limits viewing schema sections according to the allowed user permissions, while usage patterns may partition the schema according to the table update frequency. Schema partitioning helps improve query performance, eases scalability, and maximizes operational efficiency.
Integrating Schema in a Database
Most large-scale solutions involve integrating two or more database schemas to create a well-integrated, robust data view for making data-driven decisions. However, incorporating heterogeneous schemas involves incompatibilities arising from:
- Data modeling differences in schema design arise from designer methods.
- Semantic incompatibility from key, type, naming, and scaling conflicts.
- Variations in defining database entities.
Creating a global schema and restructuring to accommodate the multiple entities from the numerous schemas can be challenging and requires considerable human efforts and complexity.
How StreamSets Helps You Abstract Away Database Schema
Defining and implementing your schema during data ingestion and other data processes can be challenging as data fields may change and the addition/removal of new fields. Thankfully, StreamSets helps abstract away schema thinking through its schema-on-read approach. StreamSets confers flexibility and easy adaptability to your data processes. Its schema-on-read method infers and implements the schema without requiring engineers and developers to define it, freeing up time for other tasks.
This time-saving approach to data integration means that the careful definition, modeling, and curation of schemas is mostly an artifact of the past. Modern cloud warehouses usually charge very little for storage, and the expense incurred is often for processing power. This makes it very easy for organizations to store raw, unstructured, and unclean data for later processing. This practice naturally gave way to a new way of thinking about the movement and processing of data: ELT. Extract and Load first, then Transform.
Whatever methodology your organization chooses to handle your data, StreamSets can help. Check out patterns in our community, or join in learning in StreamSets Academy for free today.
