This blog post was updated March 14, 2023
Data warehouse schema is a description, represented by objects such as tables and indexes, of how data relates logically within a data warehouse. Star, galaxy, and snowflake schema are types of warehouse schema that describe different logical arrangements of data. Also known as multi-dimension schemas, these schemas define rules for how these data warehouses manage the names, descriptions, associated data items, and aggregates within a data warehouse.
- What is a Data Warehouse Schema?
- 3 Types of Schema Used in Data Warehouses
- What is a Star Schema in a Data Warehouse?
- What is a Snowflake Schema?
- What is a Galaxy Schema?
- Key Differences Between Star, Snowflake, and Galaxy schema
What Is a Data Warehouse Schema?
We can think of a data warehouse schema as a blueprint or an architecture of how data will be stored and managed. A data warehouse schema isn’t the data itself, but the organization of how data is stored and how it relates to other data within the data warehouse.
In the past, data warehouse schemas were often strictly enforced across an enterprise, but in modern implementations where storage is increasingly inexpensive, schemas have become less constrained. Despite this loosening or sometimes total abandonment of data warehouse schemas, knowledge of the foundational schema designs can be important to both maintaining legacy resources and for creating modern data warehouse design that learns from the past.
The basic components of all data warehouse schemas are fact and dimension tables. The different combination of these two central elements compose almost the entirety of all data warehouse schema designs.
Fact Table
A fact table aggregates metrics, measurements, or facts about business processes. In this example, fact tables are connected to dimension tables to form a schema architecture representing how data relates within the data warehouse. Fact tables store primary keys of dimension tables as foreign keys within the fact table.

Dimension Table
Dimension tables are non-denormalized tables used to store data attributes or dimensions. As mentioned above, the primary key of a dimension table is stored as a foreign key in the fact table. Dimension tables are not joined together. Instead, they are joined via association through the central fact table.

3 Types of Schema Used in Data Warehouses
History presents us with three prominent types of data warehouse schema known as Star Schema, Snowflake Schema, and Galaxy Schema. Each of these data warehouse schemas has unique design constraints and describes a different organizational structure for how data is stored and how it relates to other data within the data warehouse.
What Is a Star Schema in a Data Warehouse?
The star schema in a data warehouse is historically one of the most straightforward designs. This schema follows some distinct design parameters, such as only permitting one central table and a handful of single-dimension tables joined to the table. In following these design constraints, star schema can resemble a star with one central table, and five dimension tables joined (thus where the star schema got its name).
Star Schema is known to create denormalized dimension tables – a database structuring strategy that organizes tables to introduce redundancy for improved performance. Denormalization intends to introduce redundancy in additional dimensions so long as it improves query performance.
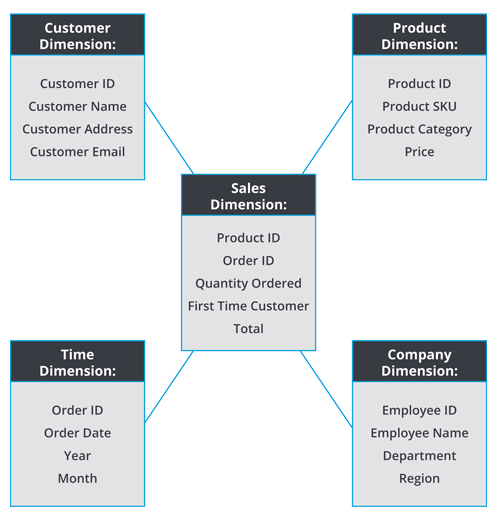
Characteristics of the Star Schema:
- Star data warehouse schemas create a denormalized database that enables quick querying responses
- The primary key in the dimension table is joined to the fact table by the foreign key
- Each dimension in the star schema maps to one dimension table
- Dimension tables within a star scheme are not to be connected directly
- Star schema creates denormalized dimension tables
What Is a Snowflake Schema?
The Snowflake Schema is a data warehouse schema that encompasses a logical arrangement of dimension tables. This data warehouse schema builds on the star schema by adding additional sub-dimension tables that relate to first-order dimension tables joined to the fact table.
Just like the relationship between the foreign key in the fact table and the primary key in the dimension table, with the snowflake schema approach, a primary key in a sub-dimension table will relate to a foreign key within the higher order dimension table.
Snowflake schema creates normalized dimension tables – a database structuring strategy that organizes tables to reduce redundancy. The purpose of normalization is to eliminate any redundant data to reduce overhead.
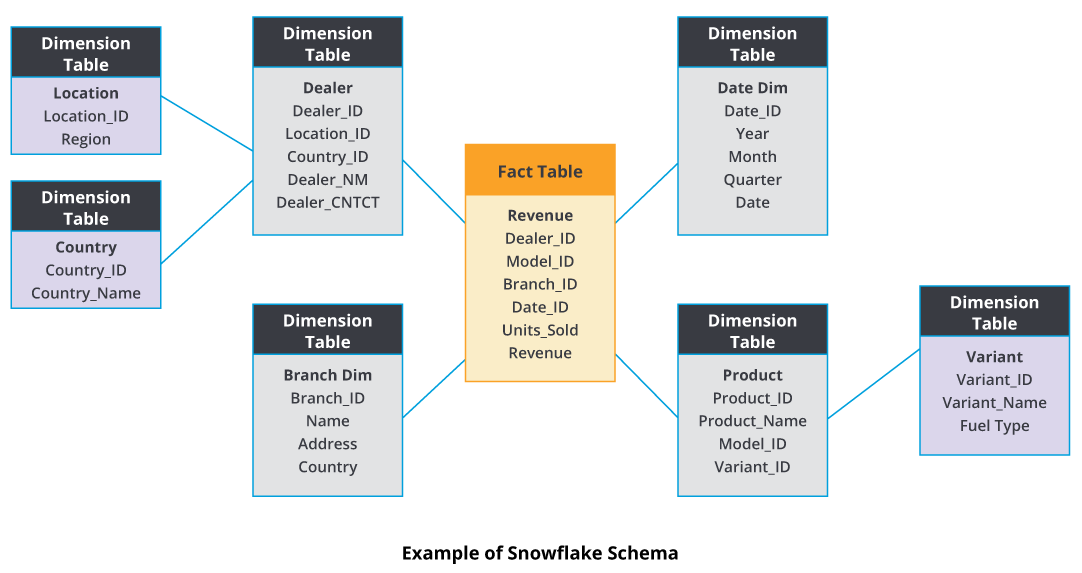
Characteristics of the Snowflake Schema:
- Snowflake Schema are permitted to have dimension tables joined to other dimension tables
- Snowflake Schema are to have one fact table only
- Snowflake Schema create normalized dimension tables
- The normalized schema reduces required disk space for running and managing this data warehouse
- Snowflake Scheme offer an easier way to implement a dimension
What Is a Galaxy Schema?
The Galaxy Data Warehouse Schema, also known as a Fact Constellation Schema, acts as the next iteration of the data warehouse schema. Unlike the Star Schema and Snowflake Schema, the Galaxy Schema uses multiple fact tables connected with shared normalized dimension tables. Galaxy Schema can be thought of as star schema interlinked and completely normalized, avoiding any kind of redundancy or inconsistency of data.
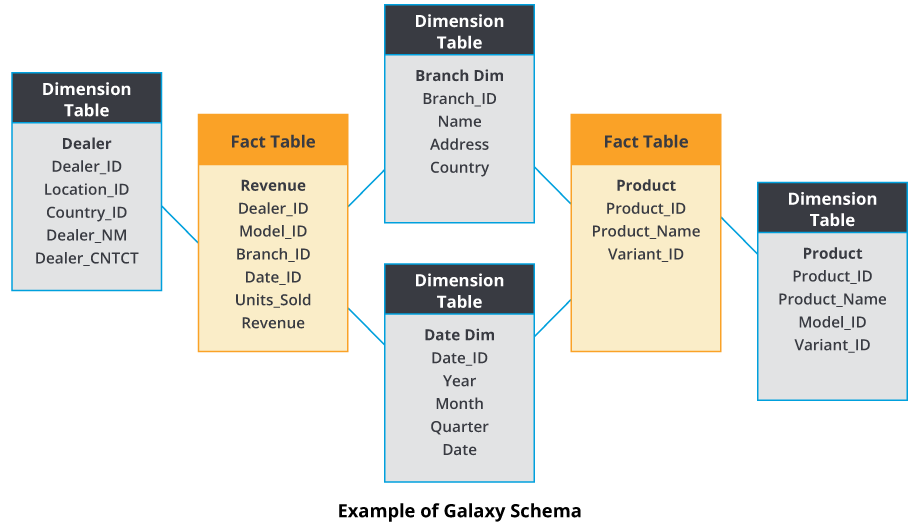
Characteristics of the Galaxy Schema:
- Galaxy Schema is multidimensional acting as a strong design consideration for complex database systems
- Galaxy Schema reduces redundancy to near zero redundancy as a result of normalization
- Galaxy Schema is known for high data quality and accuracy and lends to effective reporting and analytics
Key Differences Between Star, Snowflake, and Galaxy Schema
| Star Schema | Snowflake Schema | Galaxy Schema | |
| Elements | Single Fact Table connected to multiple dimension tables with no sub-dimension tables | Single Fact Table connects to multiple dimension tables that connects to multiple sub-dimension tables | Multiple Fact Tables connects to multiple dimension tables that connects to multiple sub-dimension tables |
| Normalization | Denormalized | Normalized | Normalized |
| Number of Dimensions | Multiple dimension tables map to a single Fact Table | Multiple dimension tables map to multiple dimension tables | Multiple dimension tables map to multiple Fact Tables |
| Data Redundancy | High | Low | Low |
| Performance | Fewer foreign keys resulting in increased performance | Decreased performance compared to Star Schema from higher number of foreign keys | Decreased performance compared to Star and Snowflake. Used for complex data aggregation. |
| Complexity | Simple, designed to be easy to understand | More complicated compared to Star Schema – can be more challenging to understand | Most complicated to understand. Reserved for highly complex data structures |
| Storage Usage | Higher disk space due to data redundancy | Lower disk space due to limited data redundancy | Low disk space usage compared to the level of sophistication due to the limited data redundancy |
| Design Limitations | One Fact Table only, no sub-dimensions | One Fact Table only, multiple sub-dimensions are permitted | Multiple Fact Tables permitted, only first level dimensions are permitted |
Data Warehouse Schema Summarized
To understand data warehouse schema and its various types at the conceptual level, here are a few things to remember:
- Data warehouse schema is a blueprint for how data will be stored and managed. It includes definitions of terms, relationships, and the arrangement of those terms and relationships.
- Star, galaxy, and snowflake are common types of data warehouse schema that vary in the arrangement and design of the data relationships.
- Star schema is the simplest data warehouse schema and contains just one central table and a handful of single-dimension tables joined together.
- Snowflake schema builds on star schema by adding sub-dimension tables, which eliminates redundancy and reduces overhead costs.
- Galaxy schema uses multiple fact tables (Snowflake and Star use only one) which makes it like an interlinked star schema. This nearly eliminates redundancy and is ideal for complex database systems.
Which Data Warehouse Schema is Best?
There’s no one “best” data warehouse schema. The “best” schema depends on (among other things) your resources, the type of data you’re working with, and what you’d like to do with it.
For instance, star schema is ideal for organizations that want maximum simplicity and can tolerate higher disk space usage. But galaxy schema is more suitable for complex data aggregation. And snowflake schema could be superior for an organization that wants lower data redundancy without the complexity of star schema.
How StreamSets’ Schema-agnostic Approach Makes Schemas Easy
Our agnostic approach to schema management means that StreamSets data pipeline tools can manage any kind of schema – simple, complex or non-existent. Meaning, with StreamSets you don’t have to spend hours matching the schema from a legacy origin into your destination, instead StreamSets can infer any kind of schema without you having to lift a finger. If however, you want to enforce a schema and create hard and fast validation rules, StreamSets can help you with that as well. Our flexibility in how we manage schemas means your data teams have less to figure out on their own and more time to spend on what really matters: your data.
Ready to combat data drift automatically? Get started with the StreamSets DataOps Platform.
