We’re thrilled to introduce the latest release of the StreamSets Python SDK – a powerful tool that seamlessly combines the capabilities of StreamSets with the flexibility and ease-of-use of Python. If you’re looking to build, integrate, and scale custom solutions efficiently, this SDK is your gateway to unblocking new possibilities.
StreamSets’ Python SDK empowers users to streamline their operations by providing an easy-to-use suite of tools for creating and maintaining your StreamSets assets. This results in a significant boost in productivity, reduces the potential for user error, and enables your business to create, manage, and maintain data integration workflows with unmatched simplicity and speed.
In this blog, we’ll cover new features and enhancements in the latest release of StreamSets Python SDK. Our goal is to keep you informed about how these enhancements can directly benefit you and your organization.
What’s New
1. Effortless Data Migration – Programmatically Update Origins and Destinations
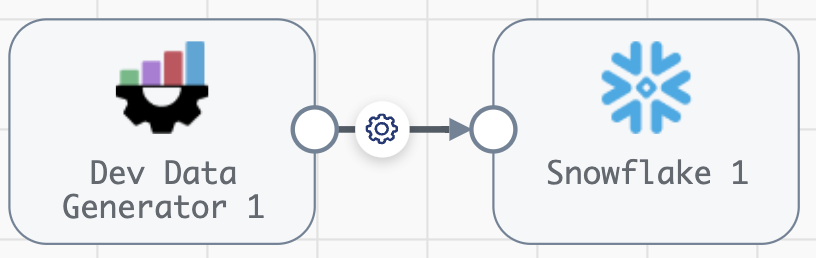
With this latest release of the SDK, we’re excited to introduce a new feature that empowers users to liberate their data effortlessly. Tackling the common challenge of migrating data between platforms or vendors has never been easier. Without the SDK, users would typically find themselves navigating through the UI, manually making changes to one or more pipelines, which can be a time consuming and error-prone process. With the SDK, however, all it takes is a few lines of code to unlock the ability to programmatically replace origins and destinations across hundreds or thousands of pipelines. Say goodbye to tedious, manual changes.
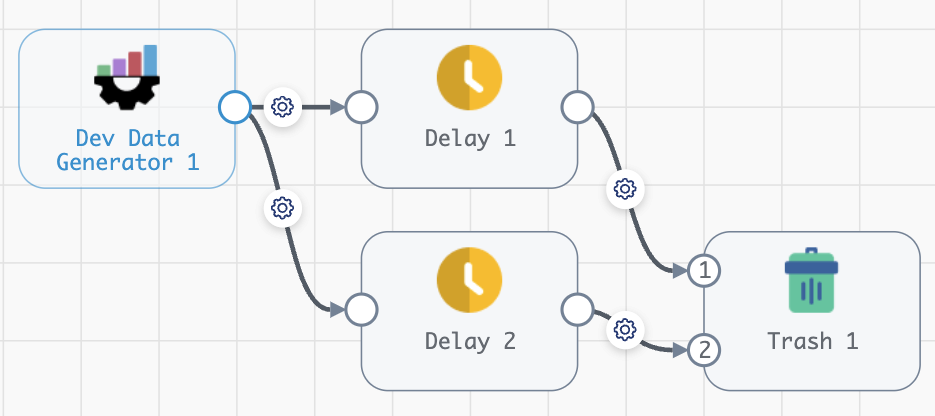
# Include this if we want to add a nice warning if no Trash destination is found import warnings # Let's loop through all of our pipelines for pipeline in sch.pipelines: try: # If our pipeline has a Trash Destination trash_destination_to_replace = pipeline.stages.get(stage_name='com_streamsets_pipeline_stage_destination_devnull_NullDTarget') # We can also filter on specific properties if we need to if trash_destination_to_replace.description == 'Replace me!': # Let's save our input connections to apply to the replacement stage - this does not work for output lanes trash_destination_input_lanes = trash_destination_to_replace.input_lanes # Then we remove our existing destination pipeline.remove_stages(trash_destination_to_replace) # And add our new one new_snowflake_destination = pipeline.add_stage('Snowflake', type='destination') # We can change configuration properties here too new_snowflake_destination.configuration.connection = sch.connections.get(name='my_prod_snowflake_connection').id # Add our connections new_snowflake_destination.input_lanes = trash_destination_input_lanes # And publish sch.publish_pipeline(pipeline, commit_message='Replace Trash destination with Snowflake') except ValueError: warnings.warn('Pipeline {} was checked and no Trash destination was found'.format(pipeline.pipeline_id))
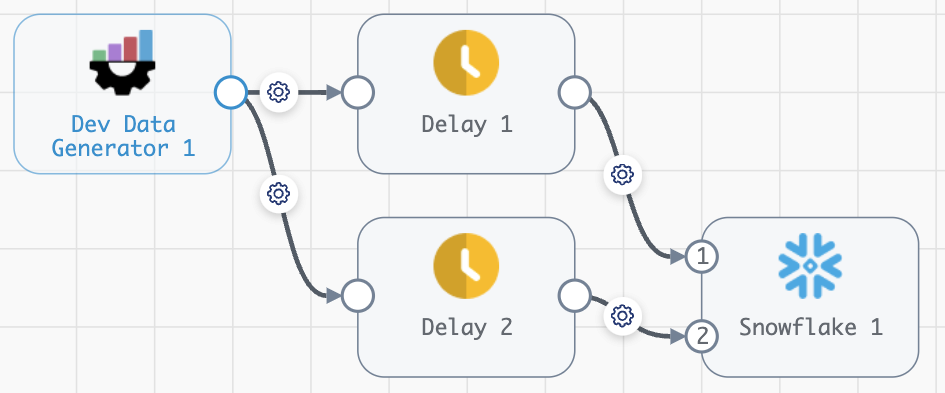
2. Reduce, Reuse, Recycle
Another enhancement that we’re introducing with this release reduces fragmentation and encourages a more sustainable approach to data integration. Users no longer have to make countless small or large changes across multiple stages, pipelines, or jobs individually. Without the SDK, users would often resort to duplicating assets and manually editing each one, which results in wasted time, and increases the risk of a fragmented or error-prone effort. By leveraging the SDK, you gain the ability to programmatically edit existing pipelines and stages or build upon them, all while eliminating the fear of unnecessary duplication or introducing errors into one or more pipelines. By empowering you to leverage existing assets, this innovative feature boosts productivity, streamlines workflows, and reduces the risk of user error.
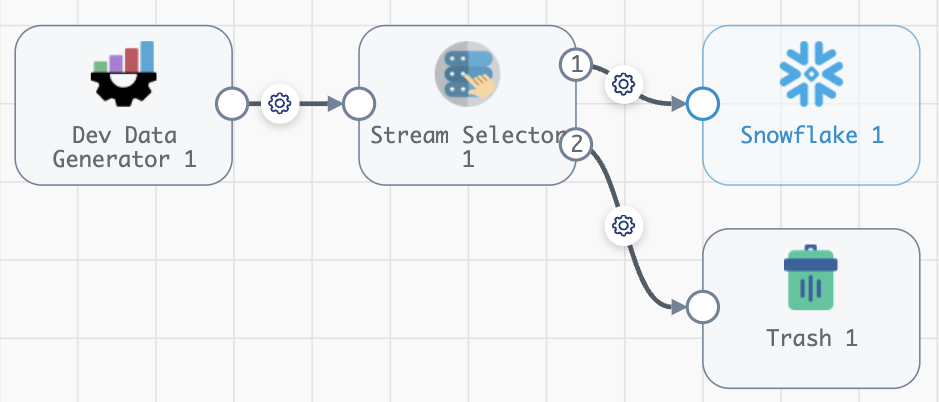
# Let's add a stream selector to all of our pipelines writing to a specific table in Snowflake import warnings # We'll get our connection outside of the loop so as not to trigger an API call each time my_prod_snowflake_connection = sch.connections.get(name='my_prod_snowflake_connection').id for pipeline in sch.pipelines: try: snowflake_destination = pipeline.stages.get(stage_name='com_streamsets_pipeline_stage_destination_snowflake_SnowflakeDTarget') if snowflake_destination.configuration.connection == my_prod_snowflake_connection and snowflake_destination.configuration.table == 'my_snowflake_table': # Add our Stream Selector and Trash stream_selector_stage = pipeline.add_stage('Stream Selector') trash_destination = pipeline.add_stage('Trash') # Now we can configure its properties stream_selector_stage.predicates = ["${record:value('/filter_column')=='DELETE_ME'}", "default"] # We will steal our input connections from our Snowflake destination stream_selector_stage.input_lanes = snowflake_destination.input_lanes # # Disconnect our old connections snowflake_destination.disconnect_input_lanes(all_stages=True) # # And point our new Stream Selector stage to our destinations stream_selector_stage.connect_outputs(stages=[snowflake_destination], output_lane_index=0) stream_selector_stage.connect_outputs(stages=[trash_destination], output_lane_index=1) sch.publish_pipeline(pipeline, commit_message='Add Stream Selector stage before all production writes to my_snowflake_table') except ValueError: warnings.warn('Pipeline {} was checked and no Snowflake destination was found'.format(pipeline.pipeline_id))
3. Master Your Connections
The latest release of StreamSets Python SDK introduces a new feature designed to grant you enhanced control over your stage connections. We understand the frustration that can result from rewiring pipelines at scale. Without the SDK, disconnecting and/or reconnecting stages in your pipelines would require significant time and effort opening pipelines one at a time in the UI and tediously adding or deleting connections one by one. With the SDK, users can quickly identify connection patterns across all pipelines and programmatically rewire them. The SDK eliminates time-consuming manual adjustments to help you reshape your pipelines as needed.

# Let's get our working pipeline rewire_connections_pipeline = sch.pipelines.get(filter_text='rewire_connections_pipeline') # Get our stages whose connections we want to edit dev_data_gen_origin = rewire_connections_pipeline.stages.get(stage_name='com_streamsets_pipeline_stage_devtest_RandomDataGeneratorSource') delay_stage = rewire_connections_pipeline.stages.get(stage_name='com_streamsets_pipeline_stage_processor_delay_DelayProcessor') field_renamer_stage = rewire_connections_pipeline.stages.get(stage_name='com_streamsets_pipeline_stage_processor_fieldrenamer_FieldRenamerDProcessor') trash_destination = rewire_connections_pipeline.stages.get(stage_name='com_streamsets_pipeline_stage_destination_devnull_NullDTarget') # Let's disconnect everything delay_stage.disconnect_output_lanes(all_stages=True) delay_stage.disconnect_input_lanes(all_stages=True) field_renamer_stage.disconnect_output_lanes(all_stages=True) field_renamer_stage.disconnect_input_lanes(all_stages=True) # And rewire dev_data_gen_origin >> field_renamer_stage >> delay_stage >> trash_destination sch.publish_pipeline(rewire_connections_pipeline, commit_message='Replace Trash destination with Snowflake')

4. Unify Your Workflow Between UI and SDK
Navigating between the user interface and the SDK environment while configuring or editing pipeline stages can be challenging for new users. The latest release of StreamSets Python SDK introduces a new configuration convention to alleviate this problem and ensure your workflow remains uninterrupted. Before SDK 6.0, users would be overwhelmed with stage functions and configuration properties without knowing which is which, let alone what field they correspond to in the UI. This release is the first step in simplifying this process by enabling you to easily access stage configuration properties through ‘stage.configuration’ which exposes the top-level configurable properties that you’re already used to seeing in the UI. Say goodbye to unnecessary complications and take advantage of the streamlined experience that allows you to focus on your objectives.
5. Brand New SDK Academy Course
It has never been easier to get started with the StreamSets Python SDK – enroll in our free, self-paced, course that teaches you the basics of working with our SDK. Learn how to create environments, deployments, pipelines, and jobs with a few lines of Python code. Unfamiliar with Python? We also offer a free Python course to help you get started!
This latest release of SteamSets’ Python SDK represents a significant stride towards simplifying and enhancing your data integration efforts. With the power to seamlessly transition between the user interface and the SDK environment, you can now navigate your workflows with ease. By introducing features that facilitate effortless pipeline construction and maintenance, promote asset reuse, and programmatic access to all of the functionality in the UI, this release empowers you to break free from the constraints of manual processes. As you explore the possibilities this SDK brings, you’ll discover streamlined efficiency, with enhanced user productivity and reduced errors.
Get Started with StreamSets.
