MLOps is emerging now more than ever in everyday workflows. Data Engineers are often tasked with the plumbing work to make data available for machine learning models. Even though statistically a small number of models get deployed to production, the ones that do often involve our time to manually update and test our previous workflows. But what is MLOps and why does it provide value to both us and organizations as a whole? First, we need to understand the different steps involved in creating a machine learning model and then we can jump into where MLOps provides value.
 The author of this post, Drew Nicolette is a Data Engineer who has spent all his career working in the public sector, building out big data solutions to help warfighters and soldiers on the ground to capture valuable data insights. On a personal level, he enjoys playing chess, staying active, and learning new cutting-edge technologies in the Data Engineering realm. Based on what he learns, he teaches what he finds to the open-source community or contributes to open-source technologies directly.
The author of this post, Drew Nicolette is a Data Engineer who has spent all his career working in the public sector, building out big data solutions to help warfighters and soldiers on the ground to capture valuable data insights. On a personal level, he enjoys playing chess, staying active, and learning new cutting-edge technologies in the Data Engineering realm. Based on what he learns, he teaches what he finds to the open-source community or contributes to open-source technologies directly.
Model Workflow
All machine learning models go through a similar continuous workflow to get deployed and stay sustained in production.
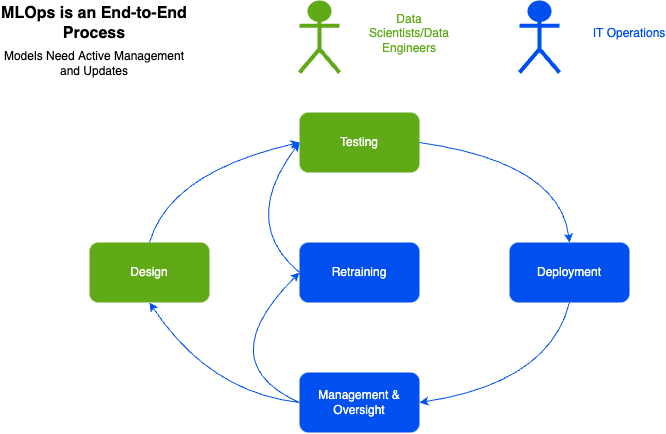
The first step in the process is designing the model. Here Data Scientists and Data Engineers work heavily with the business analysts and SMEs to define the overall problem. This is crucial because it not only defines what is expected as far as data inputs but also what the objective is for a successful production model.
Data Engineers and Scientists will work together to prototype and train their first model to then be pushed to the testing phase.
Second, is the testing and the model evaluation phase. Testers, Data Engineers, and Data Scientists will prepare manual experiments to validate model output. They will evaluate different hyperparameters, metrics, performance, and compare those models with one another to determine which one performed the best. This is an iterative process and has a lot of manual intervention but will eventually result in a model with the best performing output.
Once the model has been chosen, the third step is packaging it and deploying it to production. Here members of the IT operations team will make it readily available to be called by the end users.
However, even though the model is readily available, the machine learning process is practically just beginning. IT Operations Specialists along with data personnel need to monitor it and make sure there isn’t any model drift. Model drift refers to the continuous degradation of model performance either based on new data or behavior coming in that impacts outputs negatively over time. This is where the Management & Oversight step comes in.
If there is model drift, the data scientist and data engineers need to work together to refresh the model with new training data and execute the process all over again which is the last step of retraining.
This process overall is very time consuming, tedious, and can lead to a continuous loop where the model can’t update in a timely manner. It’s not sustainable and very hard to reproduce across teams. By the time the model gets updated and retested with new training data, it’s practically out of date again and the process starts again from the beginning.
What is MLOps?
With that brief understanding, we can now jump into MLOps. Formally, MLOps is defined as a process that will automate a sequence of common steps to deploy a model into production.
To me, it covers most aspects of the Machine Learning workflow. Not only can it be leveraged to automate the deployment of new models but also to continually monitor them and mitigate a lot of the manual tasks involved in the overall lifecycle.
Why do we need MLOps?
- Mismatched Expertise
Operations teams typically have business knowledge, data teams understand data, and ML experts understand algorithms. There is a wide gap of mismatched experience. MLOps combines experience between Data Engineers, Data Scientists, Business Analysts, and IT Operations Specialists to work together in a more efficient manner. - Reproducibility/Auditability
Each model is typically built from a very specific pipeline and code drives generation and deployments. Now with MLOps, pipelines are reproducible, and all artifacts can be tagged and audited with little to no overhead. - Validation
Because we are using MLOps, we can leverage automated validation and checking to make sure each model is profiled to the exact environment we need before rolling it out. We are also able to integrate with important tools that help eliminate bias and add capabilities that allow explanations on model quality. - Automation/Observability
As models get rolled out to production, typically they are wired up with other tools to pull all that information back to the models to get better in the future. This includes controlled rollouts capabilities and comparisons of predicted vs. expected performance. All those results get fed back to the organization to improve the model and mitigate model drift.
Data Engineering Tools
Getting data fed correctly into a machine learning model is said to be the most tedious part of preparing a machine learning model for production. Since incorporating MLOps, Data Engineering pipelines need to be in place and able to transform raw data so Machine Learning Engineers can run it through their models to discover insights and trends.
Helpful tools include:
- StreamSets: Allows a Data Engineer to easily build and visualize data pipelines that are being fed into a model. It’s essential in instrumenting multiple aspects of the data pipeline lifecycle and provides an easy to use GUI to get up and running quickly.
- Apache Spark: Batch and/or real time data processing engine that allows Data Engineers to process big data using in-memory computing across a cluster.
- Apache Kafka: Distributed pub-sub messaging system to handle real-time data for streaming and pipelining.
- Apache Airflow: Orchestration system that allows engineers to schedule and monitor workflows and pipelines.
Summary
MLOps is a new way of doing business and somewhat in its infancy. Small businesses and startups are constantly trying to build new software to help the larger ML audience streamline their workflows. For the broader data engineering audience, this article was meant to scratch the surface for those unfamiliar with this concept and show the value of not having to deal with all the overhead involved in the traditional process. Also, as we continue to build pipelines and ETL workflows, there might be a time in the future where it becomes the de facto way enterprise ML is conducted and we need to be familiar with it. I hope in the end it has been useful and you took something out of it.
