Most data collected from sources like database systems, websites, applications, and internal systems undergo either online transaction processing (OLTP) or online analytical processing (OLAP). These processing systems carry out different functions, with OLAP performing complex queries on aggregated, historical data, while OLTP helps manage and update transaction records. Choosing which processing system to use depends on your business needs, data volume, response times, and query complexity.
Let’s discuss the differences between both processing systems and how they operate together to provide a befitting processing solution for your business needs.
What Is Online Transactional Processing (OLTP)
OLTP powers most day-to-day transactions, sitting behind customer self-service apps like banking, ATMs, shopping, and booking and ticketing applications. An OLTP system processes daily operational tasks like making updates or deletions to large volumes of transactional data in real-time, e.g., updating your shopping carts, making and canceling product orders, and more. In addition, because OLTP systems handle and update current transactional data, they require fast processing times to ensure operational efficiency and a smooth customer experience.
Some features of an OLTP include:
- Transactions are ACID (Atomicity, Concurrency, Isolation, Durability)-compliant: Database transactions help perform a task and may comprise multiple units. Atomicity ensures that transaction operations proceed and complete fully, as a unit, without any part failing. A failure from one part of the unit results in a rollover of the other elements that proceeded successfully. Concurrency ensures that transactions leave the database in a consistent state; for example, a transfer to another account should leave the total value of both accounts the same as before the transfer. Isolation ensures transaction operations occur in isolation and cannot be altered simultaneously. Lastly, these database changes must occur permanently to be valid. ACID compliance ensures database transactions occur smoothly without compromising data integrity and consistency.
- Fast processing times, usually in milliseconds, to handle high-speed, voluminous queries.
- Simple queries and transactions: OLTP systems are built to perform mostly simple surface-level transactions and are not effective for more complex queries.
- Requires high availability as any downtime may cause poor customer experience and reduced sales. For example, a user trying to add items to her cart may abandon shopping for another if the site suddenly becomes unresponsive.
- High-computing power is necessary to handle the high volume of users accessing the database records simultaneously.
- Requires normalized schema to manage the delete, update, and insert operations faster.
What Is Online Analytical Processing (OLAP)
An OLAP system collates and stores data from multiple sources like websites, CRM and ERP systems, and social media and aggregates this data for making queries to obtain valuable insights like customer trends, sentiment analysis, and other helpful information that affects business decisions. As a result, OLAP grants analysts and business users faster access to a unified view of data without performing joins or complex database operations, thereby promoting faster decision-making.
An OLAP system uses an OLAP cube or hypercube to represent data in more than the usual two dimensions in tables. Although these cubes make it easy to store and access aggregated data, OLAP cubes are rigid, and once modeled, changing the underlying data becomes only possible if you rebuild the model.
OLAP systems can perform complex queries on large volumes of data, amounting to petabytes of data. For instance, an e-commerce application collates customer data, social media, and survey results. Then, it can use an OLAP to analyze these data to determine sentiment analysis and least liked products and develop strategies to improve the product’s performance.
Quick Reference Table: OLAP vs. OLTP
| Factors | OLAP | OLTP |
| Architecture | It utilizes the data cube model that extends on the row-by-column model used by most traditional databases. This cube model allows for querying multi-dimensional data. | It uses the conventional row-by-column relational database model. |
| Purpose | Collects and extracts aggregated data to perform complex queries on multi-dimensional data to drive analysis and business decisions. | Drives most daily transactional operations by creating, updating, or deleting records like cart orders, delivery information, and more. |
| Performance | Optimized for read-heavy workloads for performing complex queries on high volumes of data. Processing time on queries depends on the volume and complexity of the query. | Optimized for write-heavy workloads and have high processing times for processing high-frequency, high-volume transactions without compromising data integrity. |
| Data frequency updates | Data updates vary; some may occur daily, weekly, or monthly in batches, depending on the need for analytics. | Updates occur in real-time with stream processing and are usually triggered by action from you or your users. For example, removing an item from your cart should update the cart in the OLTP database immediately. |
| Data sources | Several OLAP databases act as the data source for an OLAP system. The OLAP source could also be a data store like a data warehouse. | The data source is usually a relational database system. |
| Availability | Availability is low-priority for OLAP as it’s optimized for analytics. Also, backups are less frequent as they mainly deal with aggregated data and don’t modify current data. | High availability and frequent backups is needed for OLTP systems as they update and modify transactional and operational data. |
The Differences Between OLAP and OLTP Explained
Data Architecture
For an OLAP system, there exists the data cube model. The data cube or hypercube model is present in OLAP systems and represents a multi-dimensional array of information. It extends on the traditional row-column tabular formats in relational databases by adding layers to make data easily findable. For example, the housing data represented in the OLAP cube below has addresses and housing prices as its top layers. However, analysts can use the drill-down operation (the drill-down operation fragments data or increases dimensions) to layer further to include addresses and contacts.
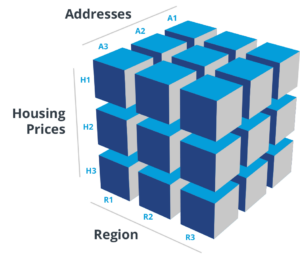
OLAP has four major operations: drill-down, roll-up, slice-and-dice, and pivot (rotate). The dimensions present in an OLAP help analysts and other data professionals filter or group the data. In contrast, an OLTP system follows the traditional relational database format, which groups data in a tabular form using rows and columns.
Storage and Compute Requirements
An OLAP pulls and extracts data from multiple sources like relational databases, data warehouses, and other systems to create a centralized data store. Hence, its storage requirement is high, measuring up to Terabytes and petabytes of data. Additionally, queries can be complex, requiring high-compute power to ensure high performance. However, for OLTP, storage requirements are lower, up to gigabytes, as you can clear the transactional data from the relational databases after loading it into a data mart or data warehouse. Again, however, it requires high-compute power.
Data Source(s)
Data sources for an OLAP system include other OLAP databases, relational databases, and data warehouses. For an OLAP system, a relational database is usually the data store.
Performance Processing
Performance for an OLAP system differs and can range from minutes to hours, depending on the query complexity and volume of data. For an OLTP, processing occurs in real-time and can be as fast as milliseconds.
Availability and Need for Backups
Availability isn’t a priority for an OLAP, as the main focus is analysis and producing insights that affect business decisions. Hence, backups don’t need to occur frequently. An OLTP system drives most transactions and requires constant availability, hence the need for frequent backups.
How StreamSets Helps Integrate OLAP and OLTP
By leveraging its intuitive drag-and-drop interface and a rich library of connectors, StreamSets enables both business users and experienced data professionals to integrate data from OLTP and OLAP sources, thus ensuring a continuous and accurate flow of information. With its built-in data quality mechanisms like data drift alerts, reusable fragments, and out of the box data transformation components, StreamSets empowers businesses to maximize the potential of both OLAP and OLTP systems. Ultimately, cleaned, combined, and properly collected data from these and other systems can provide valuable insights for informed decision-making.
Frequently Asked Questions About OLTP and OLAP
What is an example of OLTP?
OLTP systems are common for customer self-service applications like online banking, e-commerce shopping, and booking applications. For example, making a transfer should automatically debit your account in your records from the relational database.
Is Snowflake an OLAP?
Snowflake uses OLAP as a core part of its foundational schema to perform complex queries for business analysis. Snowflake is also integrated with popular business intelligence and analytics platforms like PowerBI and Tableau to facilitate business and intelligence reporting.
Which is faster, OLTP or OLAP?
OLTP relies on fast processing, as it drives most business transactions. Processing happens in real-time and can be as low as milliseconds. For OLAP, the processing time depends on the query complexity and volume of data queried.
Is OLAP normalized or denormalized?
An OLAP’s primary purpose is to perform queries on aggregated data for analytical and business reporting. It uses a denormalized schema that combines data to ease data search and retrieval for help with multi-dimensional data analysis. A denormalized schema also optimizes query speed and performance by reducing the number of join operations and tables.
