As more data enters an organization’s ecosystem for transformation and is shared with more and more organizations both within and external to the business, data quality processes and frameworks are essential. Without data quality, users will lose trust in the analytics, resulting in stalled user adoption and analytic silos. Pulling all of the information together correctly creates symbiotic results that business users believe in and derive value from.
If you are dealing with a business that relies on integrating more-and-more data sources to create a more complete picture of the customer, you know that each data source will kick-off event-driven JSON transaction records, each with its own schema and validation requirements. The best way to handle this is to make sure there is an interoperability standard defined by the organization so that additional data sources can quickly be adopted into the architecture and shared throughout the organization. It is also imperative that schema validation and record level transformations are handled appropriately.
It’s no surprise that StreamSets Data Collector Engine, a fast data ingestion engine, and StreamSets Control Hub for data pipeline monitoring and management, both of which are components of StreamSets DataOps Platform, do a spectacular job simplifying the data management processes of real-time data mapping and maintaining corporate architecture documentation – that’s what StreamSets was built to do. By streamlining the ETL processes upon ingestion, the pipelines in StreamSets have a single data origin, but can have multiple destinations, increasing the number of analytic applications that can derive immediate insight from constantly changing data.
The Challenge of Schema Validation and Record-level Transformation Re-Use
Unfortunately, more times than not, I encounter the problem: schema validation and record level transformations (specifically reshaping the record and renaming the fields) need improvement. While out-of-the-box StreamSets Data Collector Engine and its dozens of processors help, for very complex schemas and transformations, pipeline developers gravitate towards scripting evaluators. The downside of scripting evaluators is that they aren’t very reusable, and if a team member isn’t aware that someone has solved the same validation/transformation problem in the past, they are most likely going to reinvent the wheel, which is time-consuming and costly.
If you use StreamSets you may be thinking “Why not create a fragment?”
For those of you who are not familiar with fragments: “A pipeline fragment is a stage or set of connected stages that you can use in pipelines. Use pipeline fragments to easily add the same processing logic to multiple pipelines and to ensure that the logic is used as designed.” You’d be right that fragments are very powerful because they let developers create reusable components, but fragments often rely on parameters, and depending on the complexity of the logic, there could be dozens of parameters involved in a validation/transformation. Unfortunately, overly parameterized fragments result in other developers not re-using them.
The Solution: Optimize Re-use to Ensure Data Quality
By creating custom stage libraries and using the open source projects JSON Schema and Jolt, not only are validation/transformation components cataloged and easy to reuse, but the coding is also simplified. I will demonstrate how this works below.
Using the JSON Schema Validator
The JSON Schema Validator is a custom stage that uses a DSL as defined by https://json-schema.org/ to validate incoming records. If a record’s schema fails validation, the stage will generate an error record. The Schema Validator can handle complex nested structures, required fields, required data types, accepted values, ranges, uniqueness, string patterns, and complex conditional logic.
Example Scenario:
Input Record: Address information

For this simple example the schema requirements are as follows:
- Street Address must be filled in as a string value
- Country s required and must be “The United States of America” or “Canada”
- Postal Code is required, a string, and has a conditional format based on the Country
- “The United States of America”: [0-9]{5}
- “Canada”: [A-Z][0-9][A-Z] [0-9][A-Z][0-9]
Despite its simplicity, hand coding this JSON in an evaluator is more involved than you might expect. The schema will need to be defined, each validation will require logic, and finally you will have to know how to handle validation failures.
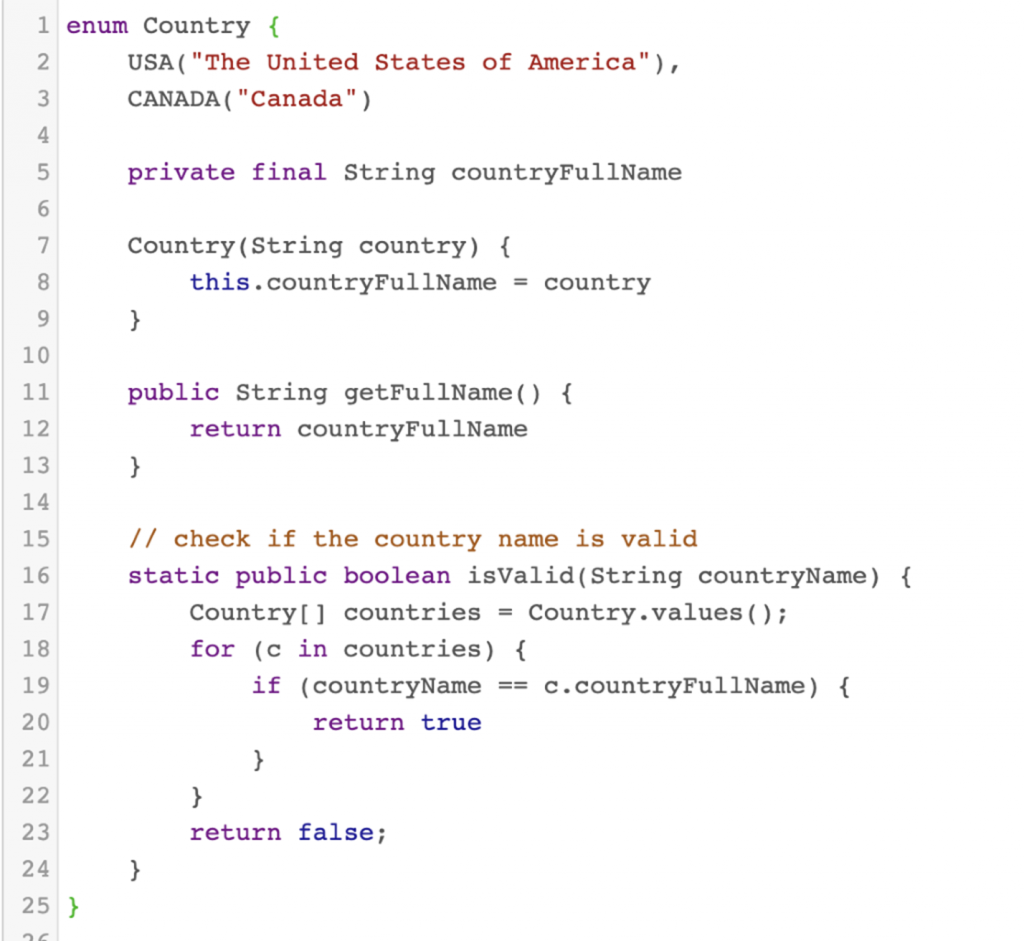
Using Groovy, I coded the validation requirements for Country:
Here are the requirements fully implemented with the Schema Validator stage library:
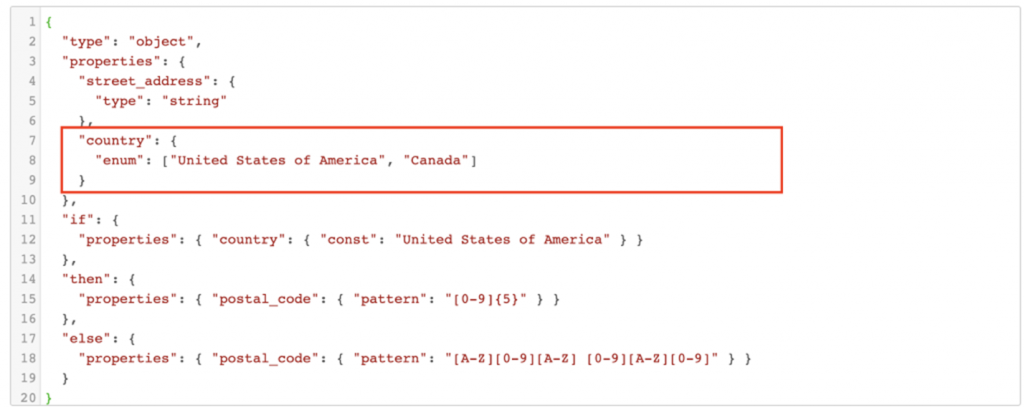
The snippet inside of the red box here is equivalent to the code snippet above. As you can see, it’s much cleaner and more readable.
The JSON Schema Validator allows you to enter the schemas directly into the stage, similar to a scripting evaluator, or to externalize it in a resource file:
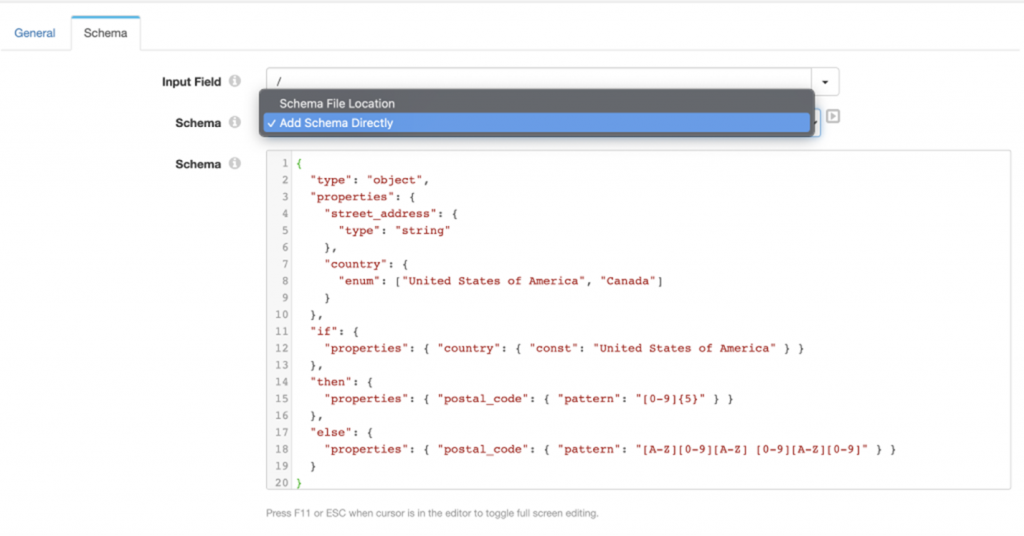
Entering it directly into the stage is convenient for development, since once your schema is working as expected you can easily add it to a resource file and reuse it across multiple pipelines!
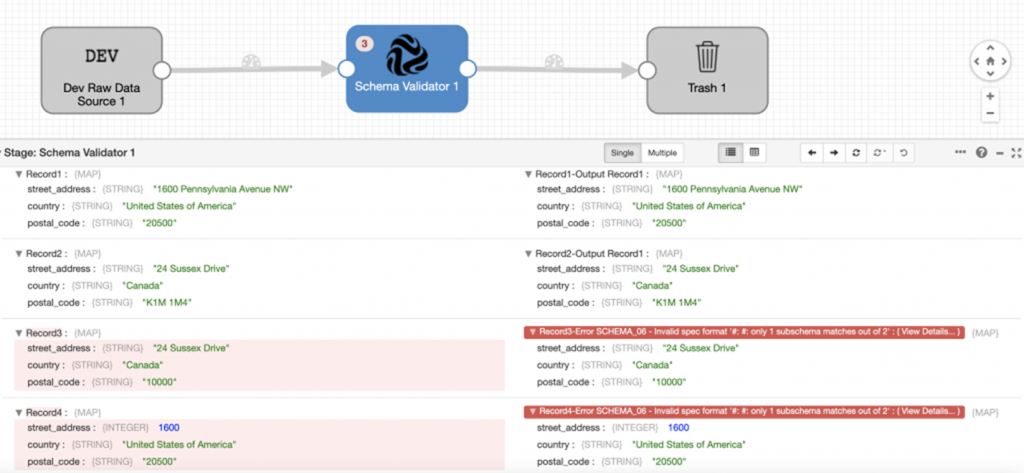
Interoperability Faster Than Before
Onboarding new data sources in your pipeline is faster with reusable coding components, delivering high quality data to analytics applications at scale. Enabling business users to make more informed decisions in the most timely manner often means increased revenue, reduced loss, and minimized risk to my customers.
Solving the Data Interoperability Challenge in Healthcare
Axis Group recently partnered with StreamSets to address a major healthcare customer’s demands by implementing an ecosystem of data interoperability. The Chief Enterprise Architect required a versatile data fabric to support all their analytics and applications. Axis Group’s best practices and technical experience powered the delivery of a microservice pipeline to deliver data in an agile and complex environment. The result was that the healthcare company achieved real-time data interoperability and can now ensure partners and customers receive the most up-to-date medication information and related details like allergies at the point of care – whether that is bedside in a medical facility or at a patient’s home.
Would you like to learn more about this solution? You can request a free data discovery call with Axis Group or check out the Git repository.
About the Author
 As a Data & Analytics Solutions Architect, James Parham tackles the toughest data strategy, management and integration challenges for Axis Group customers. Based in Atlanta, Georgia, James brings more than 15 years of experience addressing complex business challenges through analytics, automation, and data management know-how to his consulting engagements.
As a Data & Analytics Solutions Architect, James Parham tackles the toughest data strategy, management and integration challenges for Axis Group customers. Based in Atlanta, Georgia, James brings more than 15 years of experience addressing complex business challenges through analytics, automation, and data management know-how to his consulting engagements.
Axis Group is a modern Data & Analytics consulting firm with 25 years of experience. We have delivered thousands of innovative solutions to Global 1000 companies and government organizations. We are driven to make a positive impact on the world by helping people at all levels solve their biggest data and analytics problems, maximizing value and enabling better business outcomes along the way. Axis Group is the Analytics Enablement company. Learn more at axisgroup.com.