Standing for Extract, Transform, and Load, the acronym ETL describes the process of extracting data from a target, transforming it, and sending it on to load into a destination. The barest definition of ETL doesn’t include details about the nature of the source or destination. For this reason, I think there is an excellent case to be made that reverse ETL is just ETL.
Nevertheless, a new term was deemed necessary, and reverse ETL was born. Reverse ETL is defined as the process of taking data from a primary data repository and putting it into business applications like Marketo, Salesforce, and Zendesk. It is the exact opposite of ETL, where data flows in the reverse direction from these business applications into a main data repository.
Like many organizations, StreamSets runs on data. We have many use cases for omni-directional data flows, both ETL and reverse ETL. We drink our own champagne here at StreamSets, so the below pipeline use case is an actual internal pipeline we use to solve a real business problem.
Problem Statement
We needed to get leads that had been enriched with data from our main data repository back into Marketo. In other words, we had a reverse ETL use case. Here is what the overall pipeline looks like. Let’s break it down by stage.
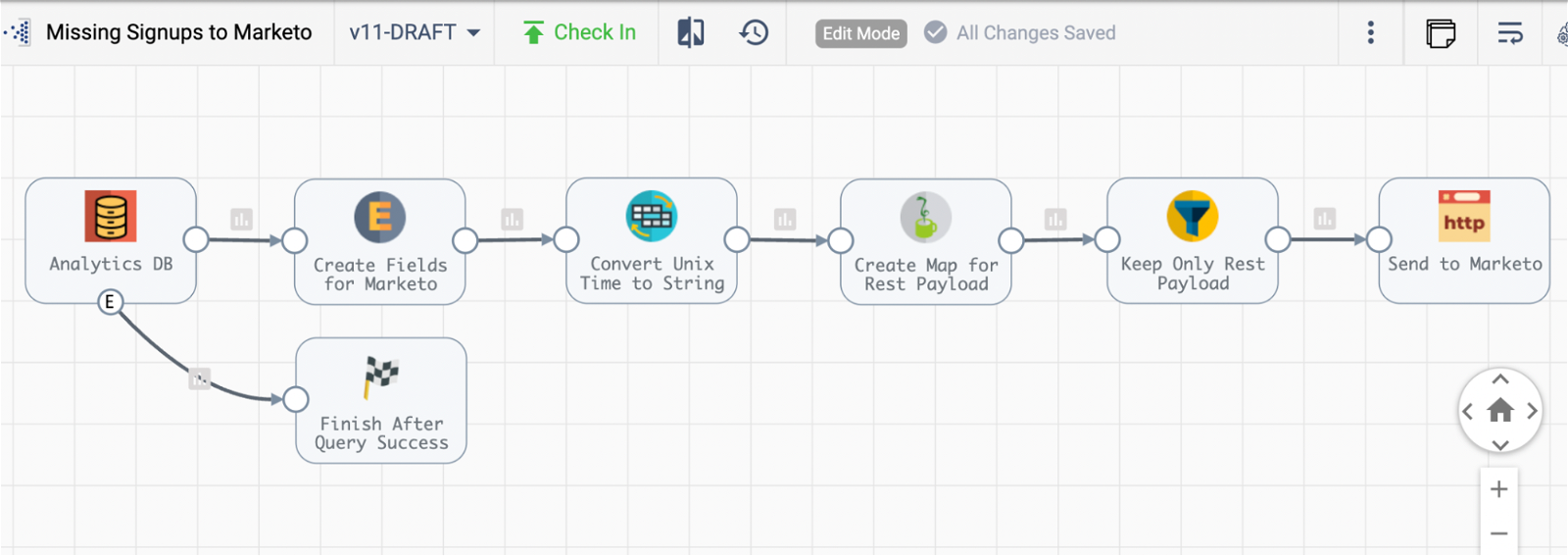
Origin: JDBC Query Consumer
In the origin of the pipeline, I connect to our analytics database. This stage is pretty straightforward, as the data in this table is already clean. I simply SELECT what I need from the database.
Expression Evaluator
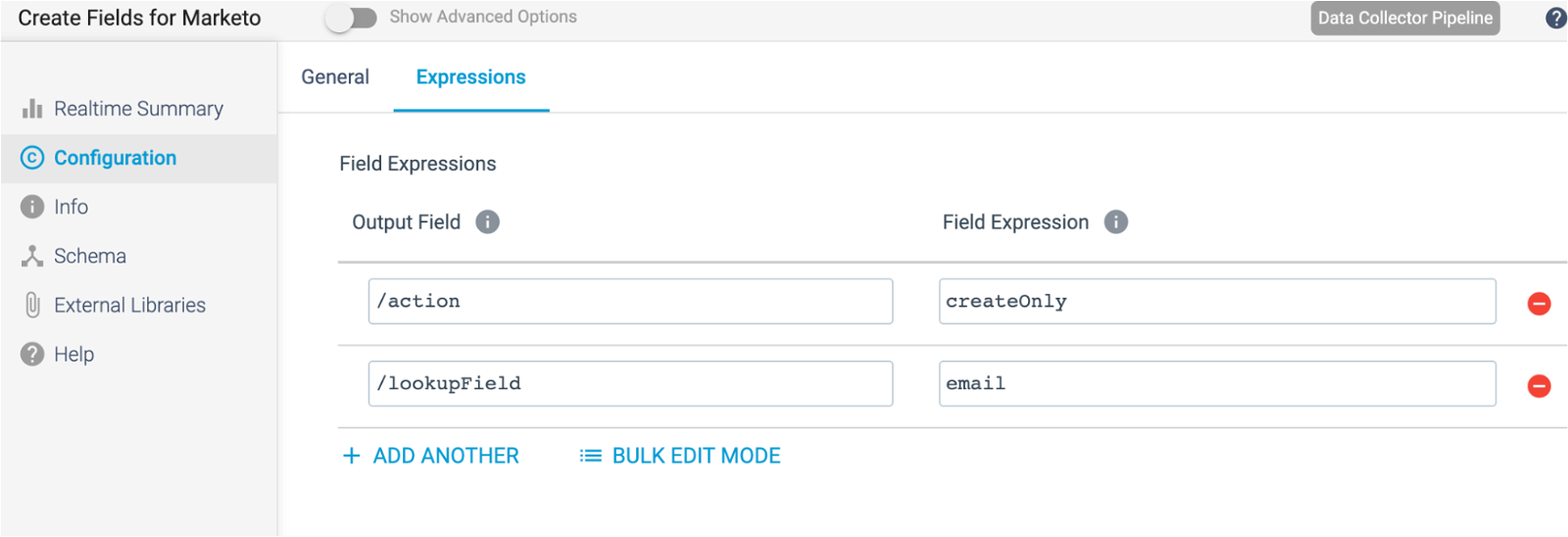
In the next stage, I’m using the expression evaluator to create two new fields: action and lookupField. These two fields are Marketo API parameters. You can look at the Marketo API for more information on the options available, but in my selection, I am only creating an email record in Marketo if one doesn’t already exist.
Field Type Converter
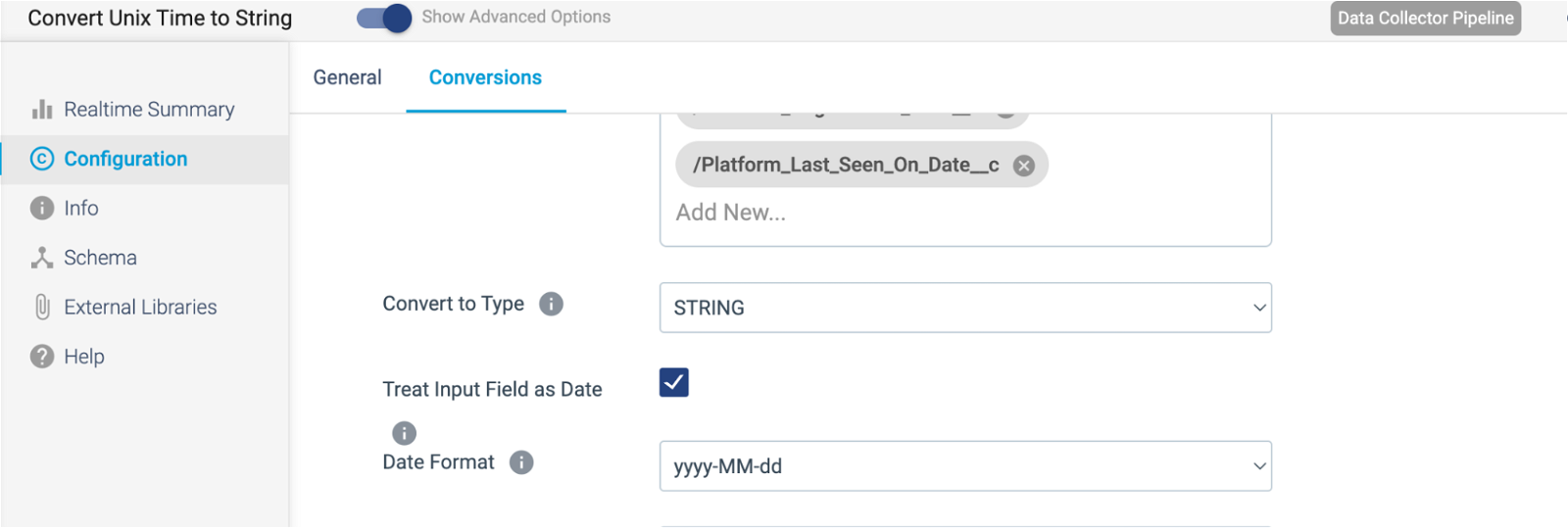
Since the destination of this pipeline will be a REST endpoint, all of the fields I’m passing to my destination need to be a STRING. StreamSets infers the schema from the data flowing through, which would normally be more helpful. But in this specific case, I need to enforce the schema. It is as easy as a drop-down to get that done.
Jython Evaluator
This Jython evaluator is the real powerhouse stage of this pipeline. This script puts all the fields flowing through my pipeline into a map called input. If you took a look at the Marketo API docs earlier, you might have noticed that input is another parameter for Marketo that contains all the details on which fields in Marketo are being updated with which data.
for record in sdc.records:
try:
input = {} input['email'] = record.value['email'] input['FirstName'] = record.value['FirstName'] input['LastName'] = record.value['LastName'] input['Account_Org_ID__c'] = record.value['Account_Org_ID__c'] input['Platform_Org_Name__c'] = record.value['Platform_Org_Name__c'] input['Platform_Org_Created_Date__c'] = record.value['Platform_Org_Created_Date__c'] input['Platform_Org_Last_Modified_Date__c'] = record.value['Platform_Org_Last_Modified_Date__c'] input['Platform_User_ID__c'] = record.value['Platform_User_ID__c'] input['EULA_Accepted_DateTime__c'] = record.value['EULA_Accepted_DateTime__c'] input['Platform_Registration_Date__c'] = record.value['Platform_Registration_Date__c'] input['Platform_Last_Seen_On_Date__c'] = record.value['Platform_Last_Seen_On_Date__c'] input['Platform_Instance_Name__c'] = record.value['Platform_Instance_Name__c'] input['Platform_Zone_ID__c'] = record.value['Platform_Zone_ID__c'] input['Platform_Zone_Name__c'] = record.value['Platform_Zone_Name__c'] input['Platform_Last_Seen_IP__c'] = record.value['Platform_Last_Seen_IP__c'] record.value['input'] = [input] sdc.output.write(record)
except Exception as e:
# Send record to error sdc.error.write(record, str(e))
Field Remover
This stage should be pretty self-explanatory. I’m taking on only those fields that fit the payload for my Marketo REST call: input, action and lookupField
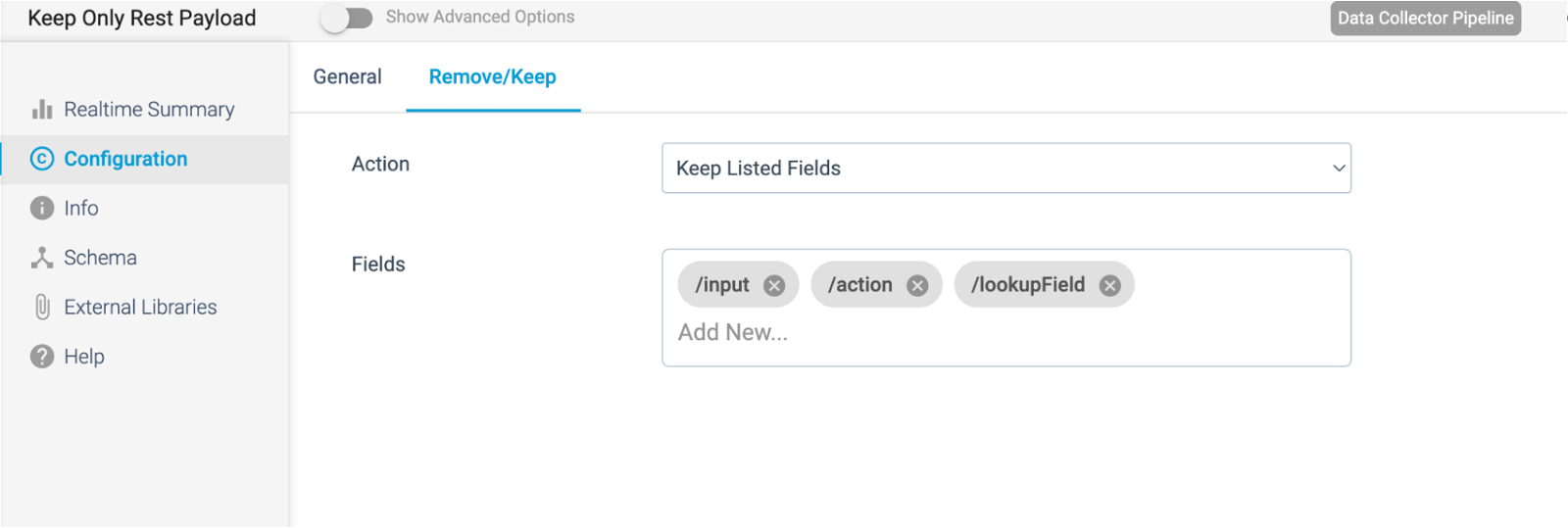
Destination: REST
All of the remaining fields represent the payload for a POST REST call to Marketo. After a response from the API, the pipeline is executed again with the data from the next row in the database. This approach is best used when there are not a lot of records to be inserted into Marketo as there is a rate limit for Marketo. Their docs have more detail.
Pipeline Finisher
The final stage of this pipeline is arguably the most important. The pipeline finisher listens for the event of ‘no more data’ and then stops the pipeline once the event is received, effectively turning a pipeline that would otherwise run endlessly into a batch pipeline that can be scheduled at whatever cadence is required.
Conclusion
This reverse ETL pipeline — or just ETL pipeline depending on your perspective — is a real production pipeline we use to keep data flowing through our business. Feel free to riff off this pattern for your own use cases. Please join us in the community to share what you’ve accomplished.