As a data engineer, you likely have an opinion on coding. The ongoing debate between pro-code and no-code approaches has touched most of us. But the reality is that this is not an all-or-nothing choice. In fact, there is great value in combining both no-code/low-code tools and traditional coding methods to achieve optimal results. Let’s explore the benefits of this hybrid approach and how it can revolutionize your data integration practice.
What Is No-Code/Low-Code Data Integration?
No-code data integration refers to the use of intuitive graphical interfaces and drag-and-drop functionality to build and orchestrate data pipelines, automate processes, and collaborate with others, all without writing extensive code. It encompasses various aspects, such as no-code databases, data pipelines, automation, and data warehousing. These tools let non-technical users perform data integration tasks efficiently and independently.
The Business Case for No-Code/Low-Code, and Pro-Code
To understand the true value of a hybrid approach, we must consider the business logic behind it. No-code and low-code data integration tools offer rapid development and democratize data integration, enabling business users to take an active role in the process of building and managing data pipelines. However, these tools may lack the configurability and customization needed for complex scenarios.
By introducing code into the mix, data professionals can mitigate the downsides of no-code/low-code solutions. Hand coding can provide fine-grained control, flexibility, and the ability to tackle intricate data challenges. Moreover, code can enhance the performance and optimization of data integration workflows.
Combining Code and No-Code/Low-Code Data Integration
Combining code with no-code/low-code data integration tools is about changing the way data engineers and other technical users work with business users. Fostering open communication and collaboration is absolutely required for success. Business users can share their requirements, perhaps even draft pipelines and workflows with no-code/low-code tools, and data engineers can apply their technical expertise to enhance and optimize these processes.
The Must-Haves for Your No-Code/Low-Code and Pro-Code Hybrid Method
Let’s talk about the must-haves for a no-code/low-code and pro-code hybrid approach. First, any approach has to be user-friendly and support smooth collaboration between technical users and business. It is also important that any solution has a robust community and plenty of documentation, webinars, videos, and other resources to help out when things get tricky. Out-of-the-box connectors for third-party systems are also a must for easy integration with various data sources.
Reusable data pipeline components or fragments are lifesavers for collaborative projects. And, of course, we need the platform to support and integrate with downstream systems, enabling them to connect and export data for analytics purposes. Finally, we want a toolset that’s easily extensible, so we can customize and build upon it without breaking anything in the process.
No-Code to Pro-Code on StreamSets
StreamSets is a prime example of a tool that offers a seamless transition from no-code to pro-code functionality. Through a simple, low-code/no-code interface, users can configure data integrations and workflows using visual components. Let’s look at a specific example using StreamSets’ Transformer for Snowflake engine.
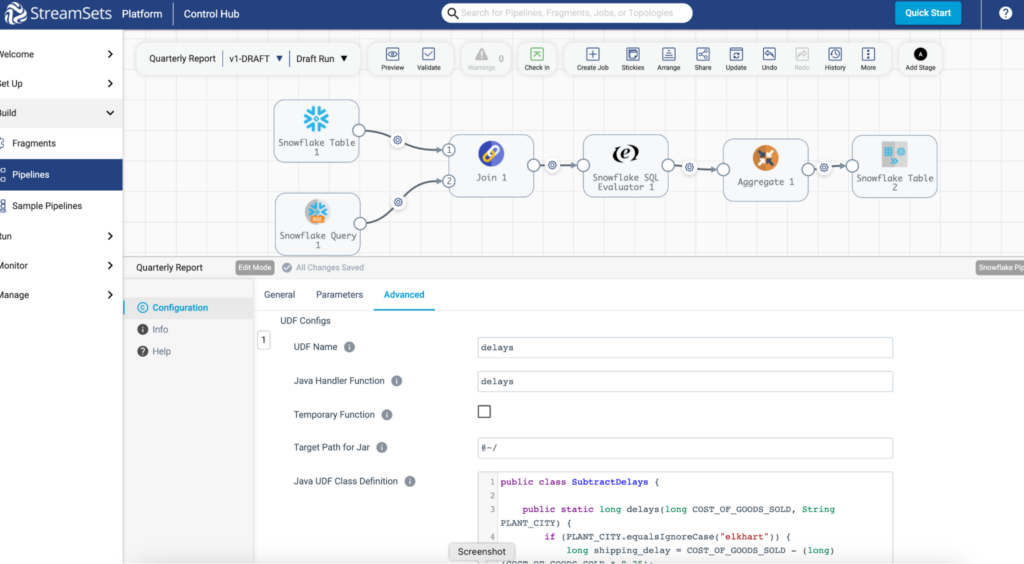
In the above image, we see a no-code data pipeline that retrieves data from Snowflake, joins, transforms it, and sends it to a final destination, all using StreamSets to interact with Snowflake’s API framework: Snowpark. This represents the straightforward, user-friendly, drag-and-drop interface central to a low-to-no-code tool.
In the same image, we also see a configuration menu that contains a UDF or User Defined Function. In this case, the UDF is written in Java. This UDF extends and customizes the transformations to the data in this pipeline. In other words, this Java code is enhancing this low-code pipeline.
This hybrid approach to pipeline building and orchestration is just one way you can use StreamSets to combine low-to-no-code with code. Exploring the relationship between the two is part of the fun of a successful data integration strategy.
Embrace a Hybrid Approach
Let’s leave the pro-code vs. no-code debate behind and embrace a hybrid approach. By combining the strengths of both methods, we can create agile, collaborative, and innovative data integration processes. StreamSets can be a collaborative partner in this journey for data teams looking for success in the middle ground.
