Grok leverages regular expression language that allows you to name existing patterns and/or combine them into more complex Grok patterns. Because Grok is based on regular expressions, any valid regular expressions (regexp) are also valid in grok.
In StreamSets Data Collector Engine, a fast data ingestion engine, running on StreamSets DataOps Platform you can use a single grok pattern, compose several patterns, or create a custom pattern to define the structure of logs data by configuring the following properties.
Grok Pattern Definition
Use this property to define a single or multiple patterns.
<PATTERN NAME> <grok pattern> <PATTERN NAME2> <grok pattern>
MYHOSTTIMESTAMP %{CISCOTIMESTAMP:timestamp} %{HOST:host}
MYCUSTOMPATTERN %{MYHOSTTIMESTAMP} %{WORD:program}%{NOTSPACE} %{NOTSPACE}
DURATIONLOG %{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}
Grok Pattern
Use this property to define the pattern that will evaluate the data. Options for defining it are:
- Predefined pattern, such as %{COMMONAPACHELOG}
- Define a custom pattern. (See below Custom Grok Patterns.)
- Patterns defined in the Definition
For example, you can use the patterns outlined in Definition above to configure as follows:
%{MYCUSTOMPATTERN} %{DURATIONLOG}
Reusing Grok Patterns
Here is the syntax for reusability: %{SYNTAX:SEMANTIC}, %{SYNTAX}, %{SYNTAX:SEMANTIC:TYPE}.
Where;
- SYNTAX is the name of the pattern that will match the text
- SEMANTIC is the identifier given to the piece of text being matched
- TYPE is the type to cast the named field
Custom Grok Patterns
You can use the following custom patterns to define the structure of logs.
Using Grok In Amazon S3
For instance, let’s take a look at how you can use Grok in Amazon S3 origin to easily parse Apache web logs ingested in the following format.
79.133.215.123 - - [14/Jun/2014:10:30:13 -0400] "GET /home HTTP/1.1" 200 1671 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36" 162.235.161.200 - - [14/Jun/2014:10:30:13 -0400] "GET /department/apparel/category/featured%20shops/product/adidas%20Kids'%20RG%20III%20Mid%20Football%20Cleat HTTP/1.1" 200 1175 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.76.4 (KHTML, like Gecko) Version/7.0.4 Safari/537.76.4" 39.244.91.133 - - [14/Jun/2014:10:30:14 -0400] "GET /department/fitness HTTP/1.1" 200 1435 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36"
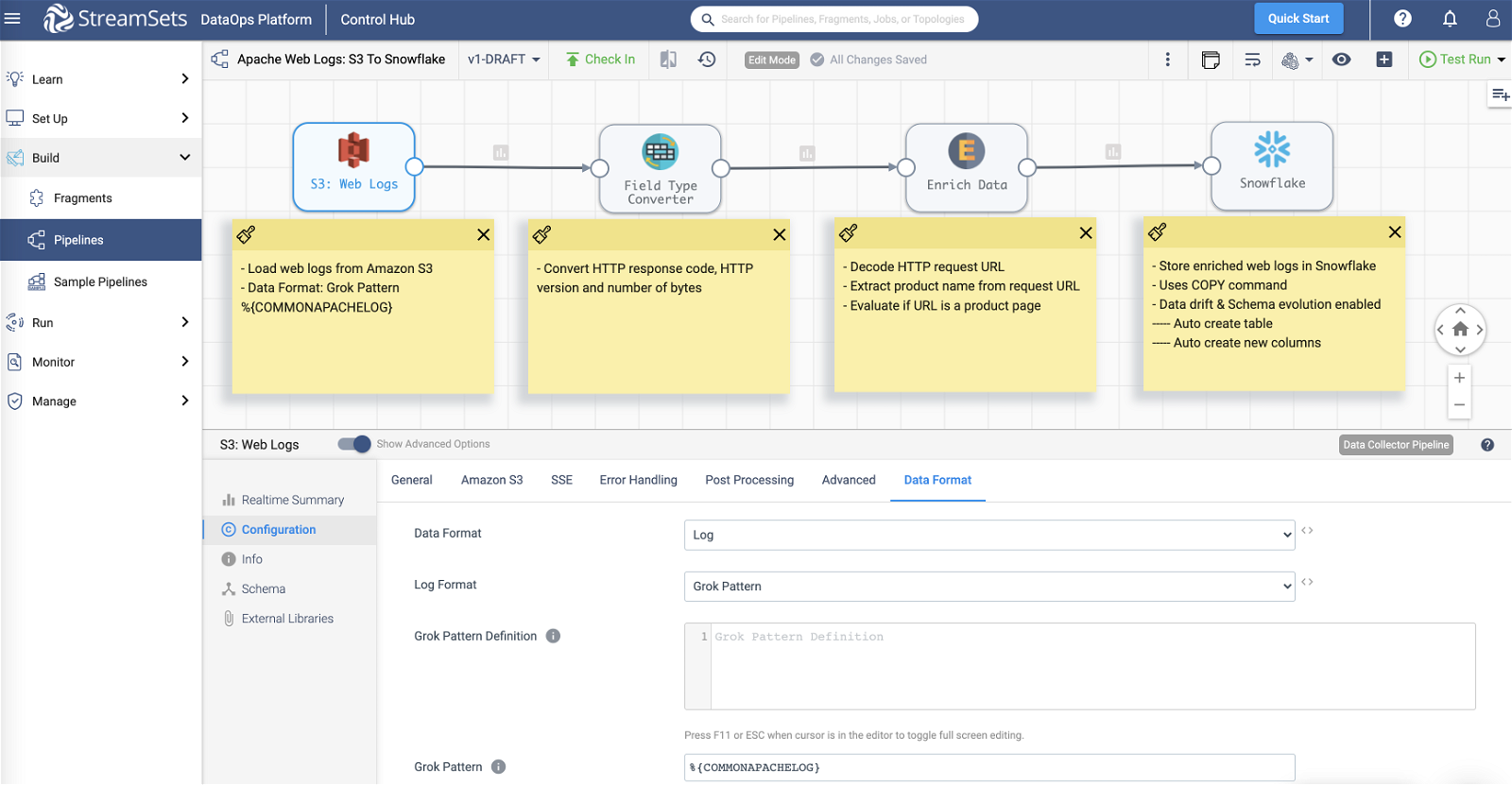
Note on Amazon S3 >> Data Format tab
- Data Format is set to Log
- Log Format is set to Grok Pattern
- Grok Pattern is set to %{COMMONAPACHELOG}
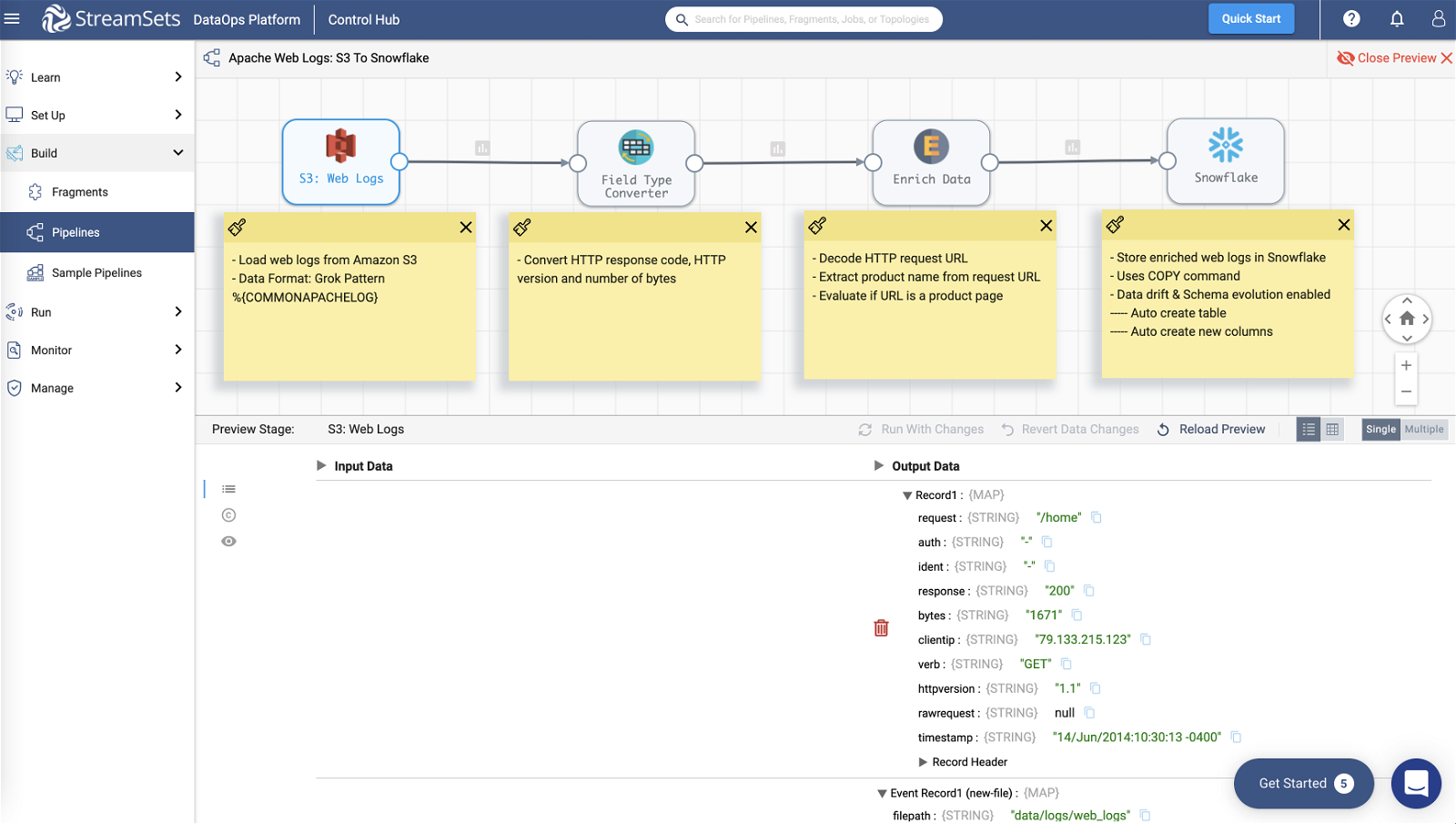 In the pipeline:
In the pipeline:
- Field Type Converter processor converts fields like response, timestamp, httpversion from string to their respective datatypes
- Expression Evaluator processor decodes field request (the HTTP url) to UTF-8 and also extracts product name from the URL using regExCapture()
Snowflake
The parsed and enriched Apache web logs are stored in Snowflake for analytics in Snowsight.
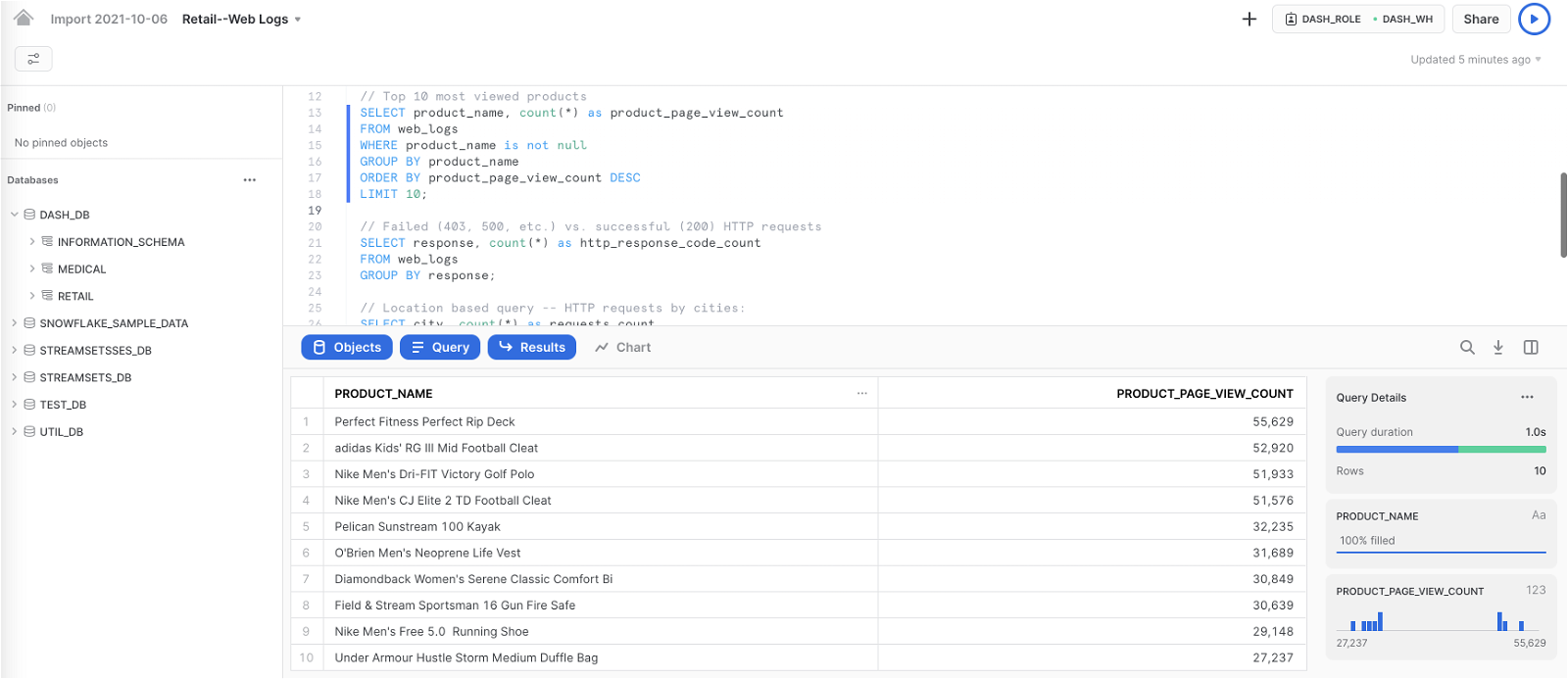
Query: Top 10 most viewed products
SELECT product_name, count(*) as product_page_view_count FROM web_logs WHERE product_name is not null GROUP BY product_name ORDER BY product_page_view_count DESC LIMIT 10;
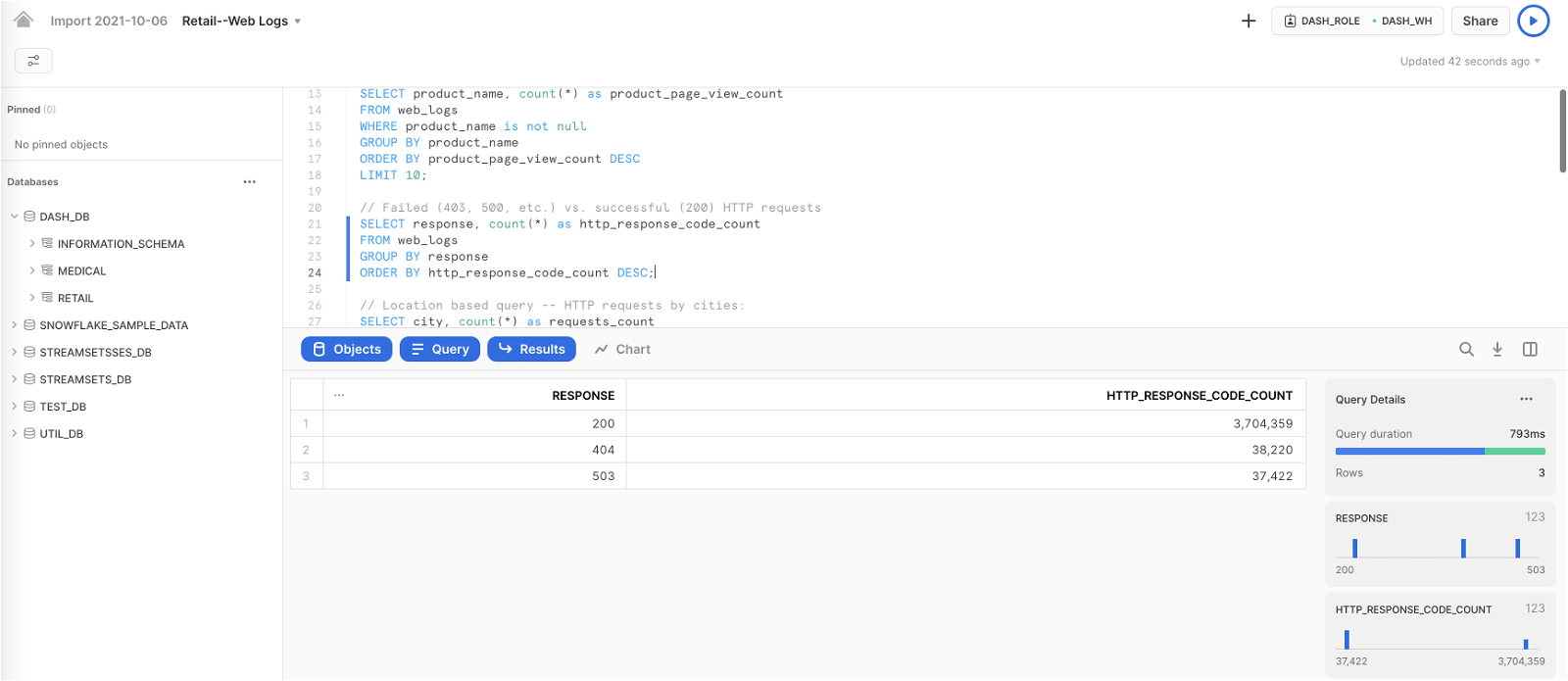
Query: Failed (403, 500, etc.) vs. successful (200) HTTP requests
SELECT response, count(*) as http_response_code_count FROM web_logs GROUP BY response ORDER BY http_response_code_count DESC;
Log Data Format Support In StreamSets Data Collector
For a comprehensive list of all the origins, processors, and destinations in StreamSets Data Collector Engine that support Log data format where Grok Patterns can be used, visit our documentation.
Try Grok in Your Data Pipelines
To take advantage of this and other features, get started today by deploying data engines in your favorite cloud to design, deploy, and operate data pipelines.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.