Running Scala Code in StreamSets Data Collector
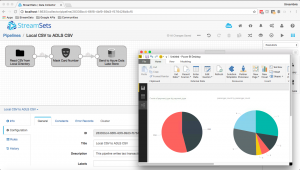
 The Spark Evaluator, introduced in StreamSets Data Collector (SDC) version 2.2.0.0, lets you run an Apache Spark application, termed a Spark Transformer, as part of an SDC pipeline. Back in December, we released a tutorial walking you through the process of building a Transformer in Java. Since then, Maurin Lenglart, of Cuberon Labs, has contributed skeleton code for a Scala Transformer, paving the way for a new tutorial, Creating a StreamSets Spark Transformer in Scala.
The Spark Evaluator, introduced in StreamSets Data Collector (SDC) version 2.2.0.0, lets you run an Apache Spark application, termed a Spark Transformer, as part of an SDC pipeline. Back in December, we released a tutorial walking you through the process of building a Transformer in Java. Since then, Maurin Lenglart, of Cuberon Labs, has contributed skeleton code for a Scala Transformer, paving the way for a new tutorial, Creating a StreamSets Spark Transformer in Scala.