Streaming & Batch Ingest Data Collector
Build reusable data ingestion pipelines in one interface. From any source, to any destination.
Data Ingestion Pipelines, Simplified
Spend more time building data smart pipelines, enabling self-service and innovating without the noise. StreamSets Data Collector Engine is an easy-to-use data pipeline engine for streaming, CDC and batch ingestion from any source to any destination.
Connectors
100+ connectors get your pipelines up and running fast without special skills.






Awards and Recognition


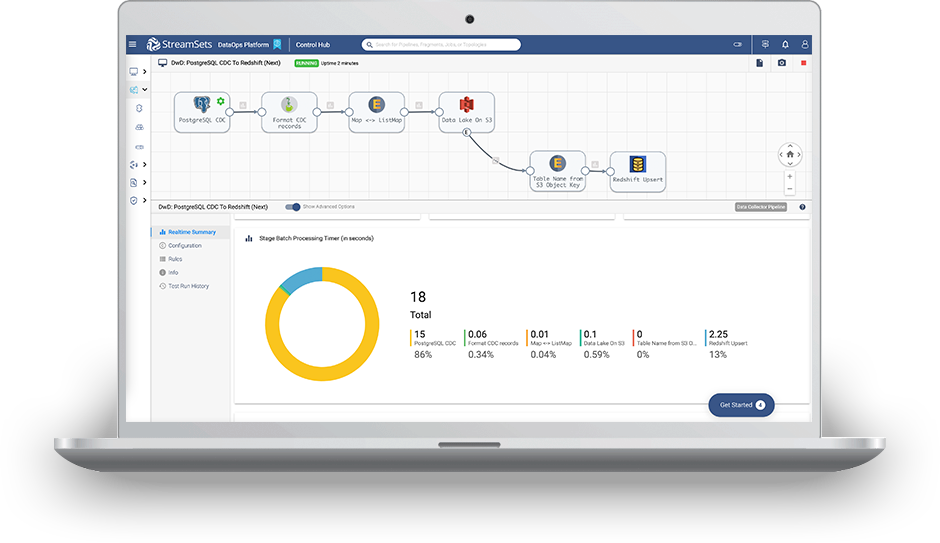
Operationalize Your Data Collection

Single Experience for All Design Patterns
Build schema-agnostic smart data pipelines with pre-built sources and destinations in minutes for streaming, batch, and change data capture (CDC), using a single, visual tool. StreamSets Data Collector Engine makes it easy to run data pipelines from Kafka, Oracle, Salesforce, JDBC, Hive, and more to Snowflake, Databricks, S3, ADLS, Kafka and more. Data Collector Engine runs on-premises or any cloud, wherever your data lives.
Ingest Data Across Multiple Platforms
Run your data in a development environment on multiple platforms without rework. Data Collector pipelines are platform agnostic by design so you can reuse them across data platforms in hybrid and multi-cloud environments. With a few configuration settings, any data professional can start ingesting data from any source to multiple platforms, giving your organization the flexibility to adapt more quickly to new business needs.


Smart Data Pipelines Built for Change
Worst case scenario: an upstream change doesn’t break your pipeline, it flows unreliable, incorrect, or unusable data into your analytics platform undetected. Intent-driven pipelines built for data drift, reducing risk of bad data downstream and outages. When data drift happens, Data Collector pipelines alert you to remediate issues or embrace emergent design.
Data Engineers Gain Efficiencies With StreamSets

![]() 8/1/23
8/1/23
"The best feature of StreamSets is its intuitive visual interface, allowing us to effortlessly design, monitor, and manage data pipelines without the need for complex coding. This has significantly reduced our development time and made the process highly accessible to both technical and non-technical team members."

![]() 8/3/23
8/3/23
"StreamSets has lot of out of box features to use for data pipelines and connect AWS Kinesis, DB or Kafka and send to HDFS & Hive."
Frequently Asked Questions
What is StreamSets Data Collector?
What is the difference between StreamSets Data Collector and Transformer?
StreamSets Data Collector runs data ingestion for cloud data pipelines in streaming, CDC, or batch modes, whereas StreamSets Transformer performs ETL, ELT and data transformations such as joins, aggregates, and unions directly on Apache Spark and Snowflake platforms. They are both part of the StreamSets platform.
How is processed data in StreamSets Data Collector tracked?
Processed data is tracked in Data Collector through the Orchestration Record, which contains details about the task that it performed, such as the IDs of the jobs or pipelines that it started and the status of those jobs or pipelines.
Can the StreamSets Data Collector engine be deployed in the cloud?
Yes. StreamSets Data Collector can be deployed to Amazon EC2, Azure Virtual Machine, or Google Compute Engine. Review the documentation for more information.