Triggering Databricks Notebook Jobs from StreamSets Data Collector
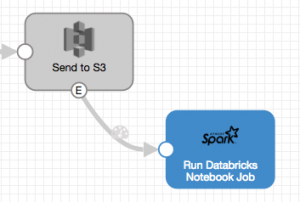 Last December, I covered Continuous Data Integration with StreamSets Data Collector and Spark Streaming on Databricks. In StreamSets Data Collector (SDC) version 2.5.0.0 we added the Spark Executor, allowing your pipelines to trigger a Spark application, running on Apache YARN or Databricks. I’m going to cover the latter in this blog post, showing you how to trigger a notebook job on Databricks from events in a pipeline, generating analyses and visualizations on demand.
Last December, I covered Continuous Data Integration with StreamSets Data Collector and Spark Streaming on Databricks. In StreamSets Data Collector (SDC) version 2.5.0.0 we added the Spark Executor, allowing your pipelines to trigger a Spark application, running on Apache YARN or Databricks. I’m going to cover the latter in this blog post, showing you how to trigger a notebook job on Databricks from events in a pipeline, generating analyses and visualizations on demand.
 Hi, my name is
Hi, my name is