 StreamSets Data Collector Engine has long supported both reading and writing data from and to relational databases via Java Database Connectivity (JDBC). While it was straightforward to configure pipelines to read data from individual tables, ingesting records from an entire database was cumbersome, requiring a pipeline per table. StreamSets Data Collector Engine Now introduces the JDBC Multitable Consumer, a new pipeline origin that can read data from multiple tables through a single database connection. In this blog entry, I’ll explain how the JDBC Multitable Consumer can implement a typical use case – replicating relational databases (an entire one) into Hadoop.
StreamSets Data Collector Engine has long supported both reading and writing data from and to relational databases via Java Database Connectivity (JDBC). While it was straightforward to configure pipelines to read data from individual tables, ingesting records from an entire database was cumbersome, requiring a pipeline per table. StreamSets Data Collector Engine Now introduces the JDBC Multitable Consumer, a new pipeline origin that can read data from multiple tables through a single database connection. In this blog entry, I’ll explain how the JDBC Multitable Consumer can implement a typical use case – replicating relational databases (an entire one) into Hadoop.
Installing a JDBC Driver
The first task is to install the JDBC driver corresponding to your database. Follow the Additional Drivers documentation carefully; this is quite a delicate process and any errors in configuration will prevent the driver from being loaded.
In the sample below, I use MySQL, but you should be able to ingest data from any relational database, as long as it has a JDBC driver.
Replicating Relational Databases
I used the MySQL retail_db database included in the Cloudera Quickstart VM as my sample data source. It contains 7 tables:
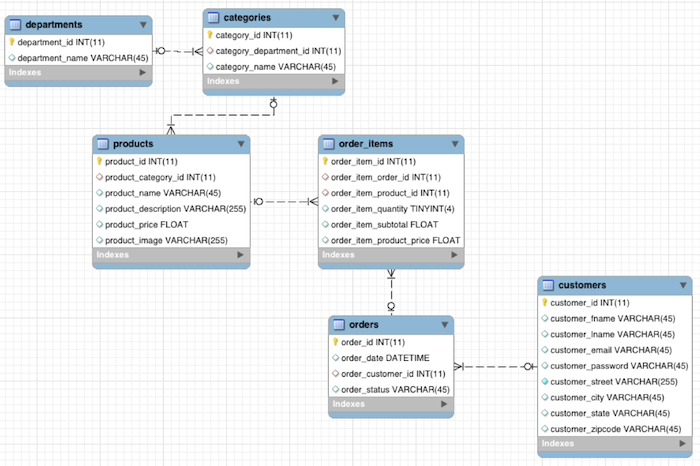
Although this is a simple schema, the sample database contains a significant amount of data – over a quarter of a million rows in total. My goal for replicating relational databases (this entire database to be exact) – every table, every row – into an Apache Hive data warehouse isn’t as difficult as it sounds when using StreamSets.
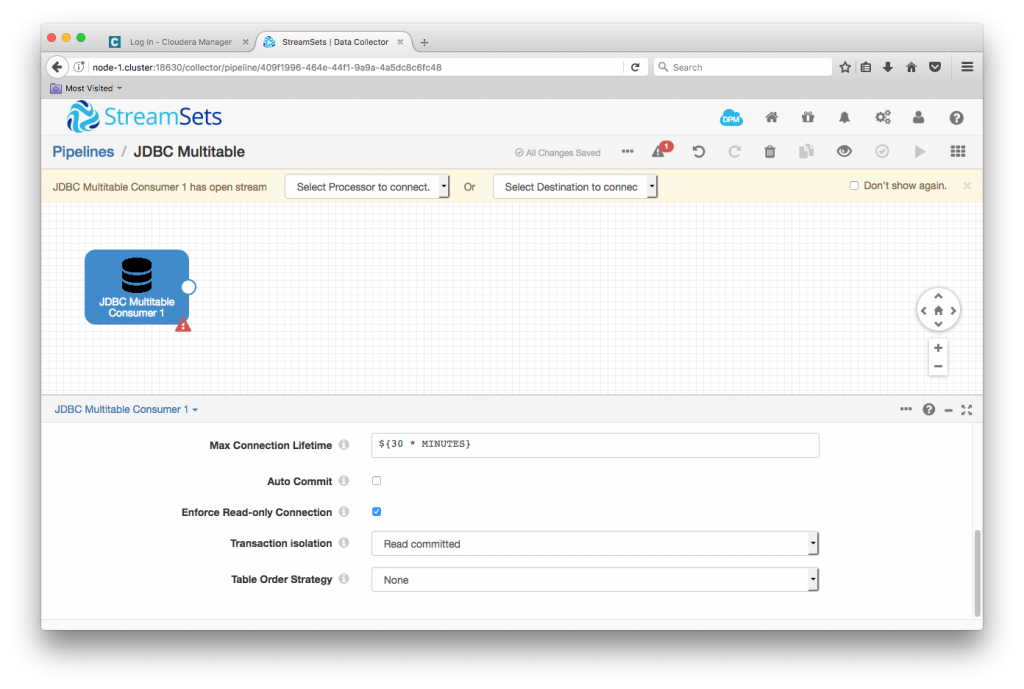
I created a new pipeline, and dropped in the JDBC Multitable Consumer. The key piece of configuration here is the JDBC Connection String. In my case, this was jdbc:mysql://pat-retaildb.my-rds-instance.rds.amazonaws.com:3306/retail_db, but you’ll need to change this to match your database.
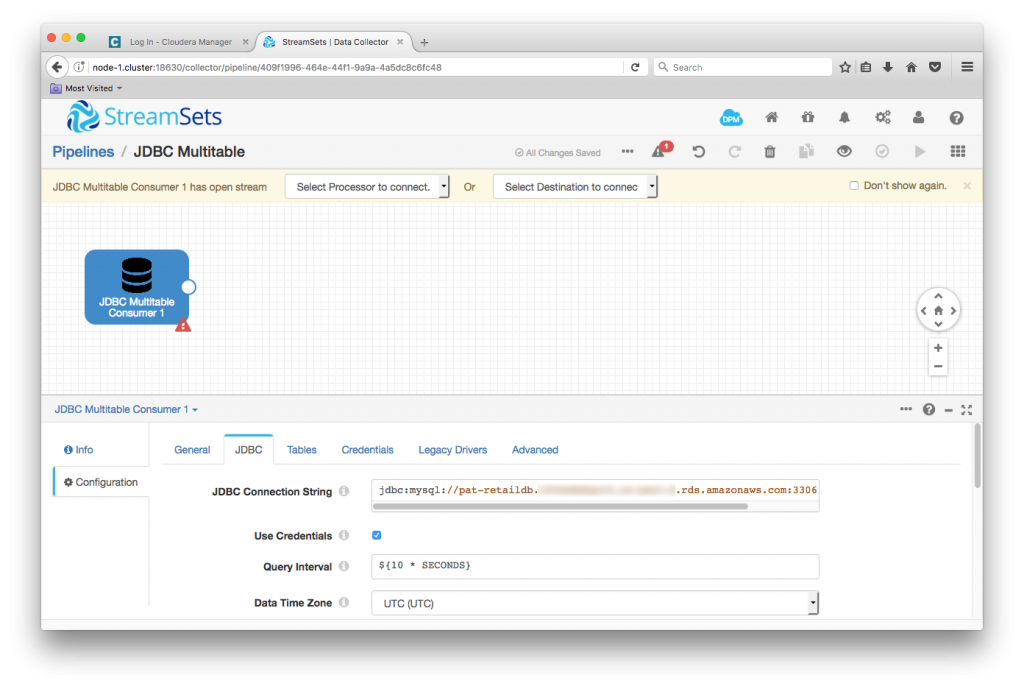
I used the default values for the remainder of the JDBC tab – see the documentation for an explanation of these items, in particular, batch strategy.
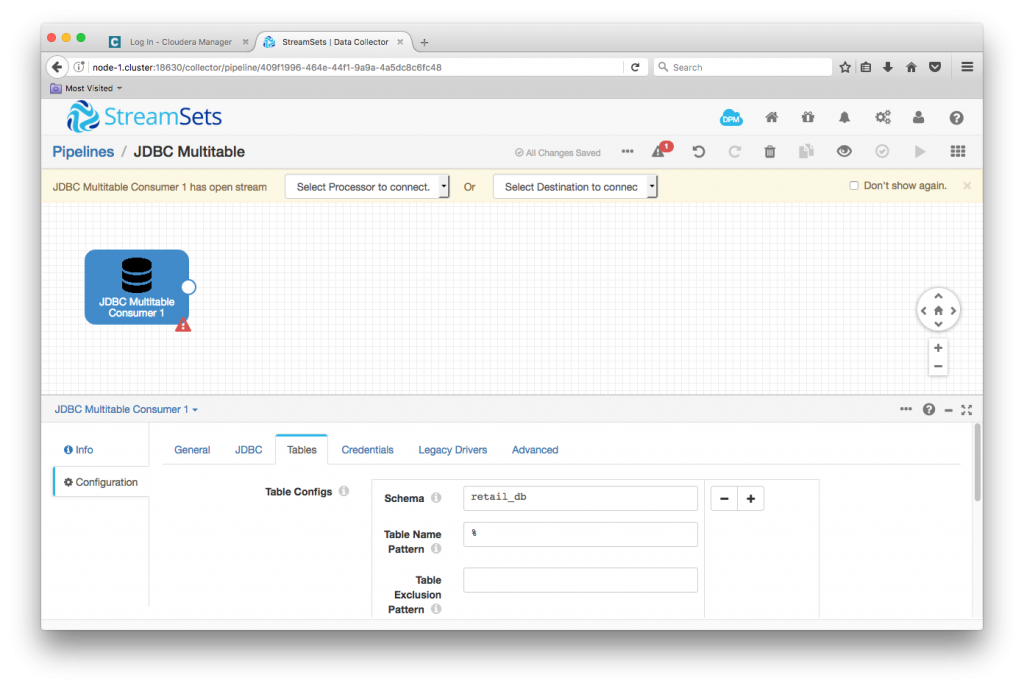
On the Tables tab, I used a single table configuration, setting JDBC schema to retail_db, and left the table name pattern with its default value, %, to match all tables in the database. You can create multiple table configurations, each with its own table name pattern, to configure whichever subset of tables you require. Since each of the tables in the sample database has a suitable primary key, I didn’t need to configure any offset columns, but you have the option to do so if necessary. The documentation describes table configurations in some detail, and is worth reading carefully.
One MySQL-specific note: the default transaction isolation level for MySQL InnoDB tables is REPEATABLE READ. This means that repeating the same SELECT statement in the same transaction gives the same results. Since the JDBC Multitable Consumer repeatedly queries MySQL tables, and we want to pick up changes between those queries, I set ‘Transaction isolation’ to ‘Read committed’ in the consumer’s Advanced tab.
With the origin configured, I was able to preview data. I checked ‘Show Record/Field Header’ in Preview Configuration so I could see the attributes that the origin sets:
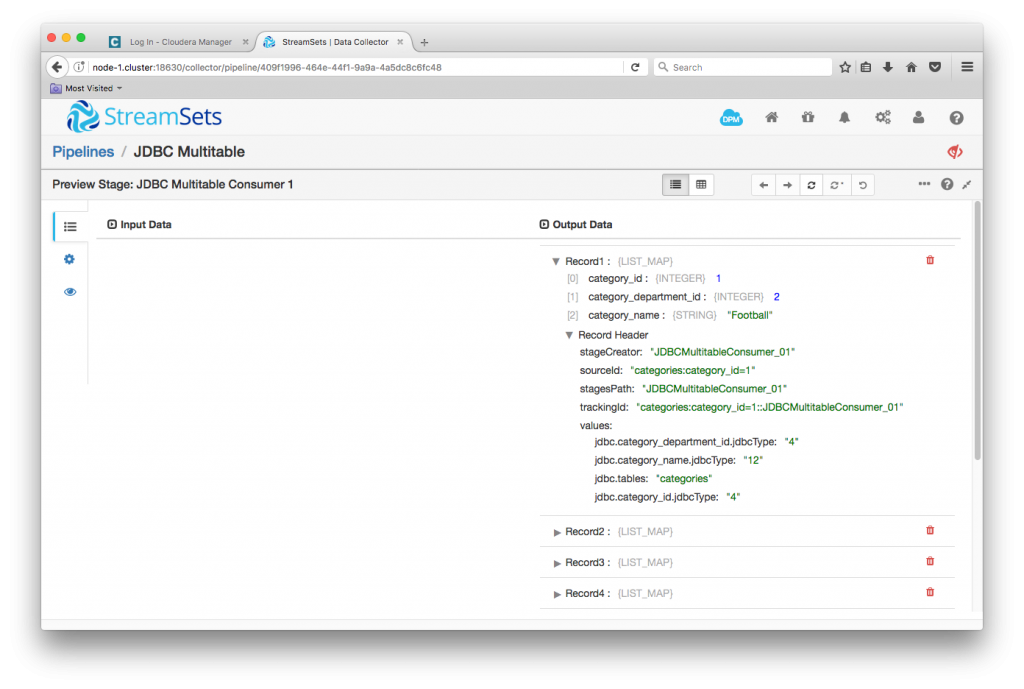
Note in particular the jdbc.tables attribute – every record carries with it the name of its originating table. Note also that, in preview mode, the origin reads only the first table that matches the configuration.
 StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Transforming Data
When we load data from transactional databases into the data warehouse, we often want to filter out personally identifiable information (PII). Looking at the customers table, it has columns for first name, last name, email, password and street address. I don’t want those in the data warehouse – for my analyses, customer id, city, state and ZIP Code suffice.
mysql> describe customers; +-------------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------------+--------------+------+-----+---------+----------------+ | customer_id | int(11) | NO | PRI | NULL | auto_increment | | customer_fname | varchar(45) | NO | | NULL | | | customer_lname | varchar(45) | NO | | NULL | | | customer_email | varchar(45) | NO | | NULL | | | customer_password | varchar(45) | NO | | NULL | | | customer_street | varchar(255) | NO | | NULL | | | customer_city | varchar(45) | NO | | NULL | | | customer_state | varchar(45) | NO | | NULL | | | customer_zipcode | varchar(45) | NO | | NULL | | +-------------------+--------------+------+-----+---------+----------------+ 9 rows in set (0.03 sec)
I separated out customer records in the pipeline with a Stream Selector with a condition
${record:attribute('jdbc.tables') == 'customers'}
A Field Remover then stripped the PII from the customer records
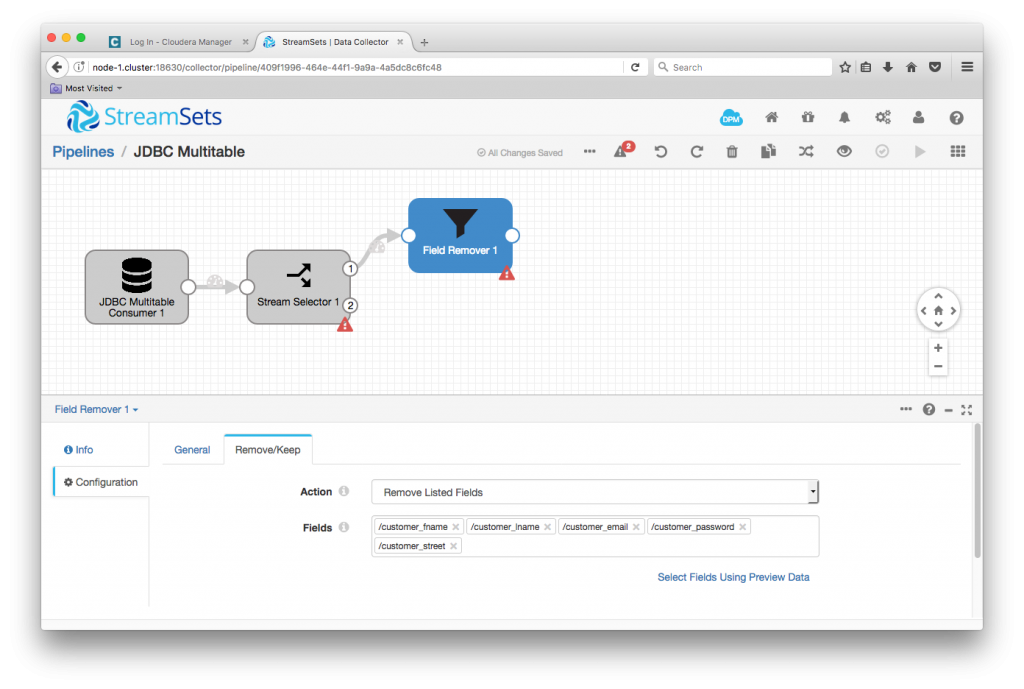
Writing Data to Hive
The combination of the Hive Metadata Processor and the Hadoop FS and Hive Metastore destinations allow us to write data to Hive without needing to predefine the Hive schema. The Hive Metadata Processor examines the schema of incoming records and reconciles any difference with the corresponding Hive schema, emitting data records for consumption by the Hadoop FS destination and metadata records for the Hive Metastore destination. See Ingesting Drifting Data into Hive and Impala for a detailed tutorial on setting it all up.
Configuration of the three stages mostly involves specifying the Hive JDBC URL and Hadoop FS location, but there is one piece of ‘magic’: I set the Hive Metadata Processor’s Table Name to retaildb-${record:attribute('jdbc.tables')}. This tells the processor to use each record’s table name attribute, as we saw in the preview above, to build the destination Hive table name. I’m prefixing the Hive table names with retaildb- so I can distinguish the tables from similarly named tables that might come from other upstream databases.
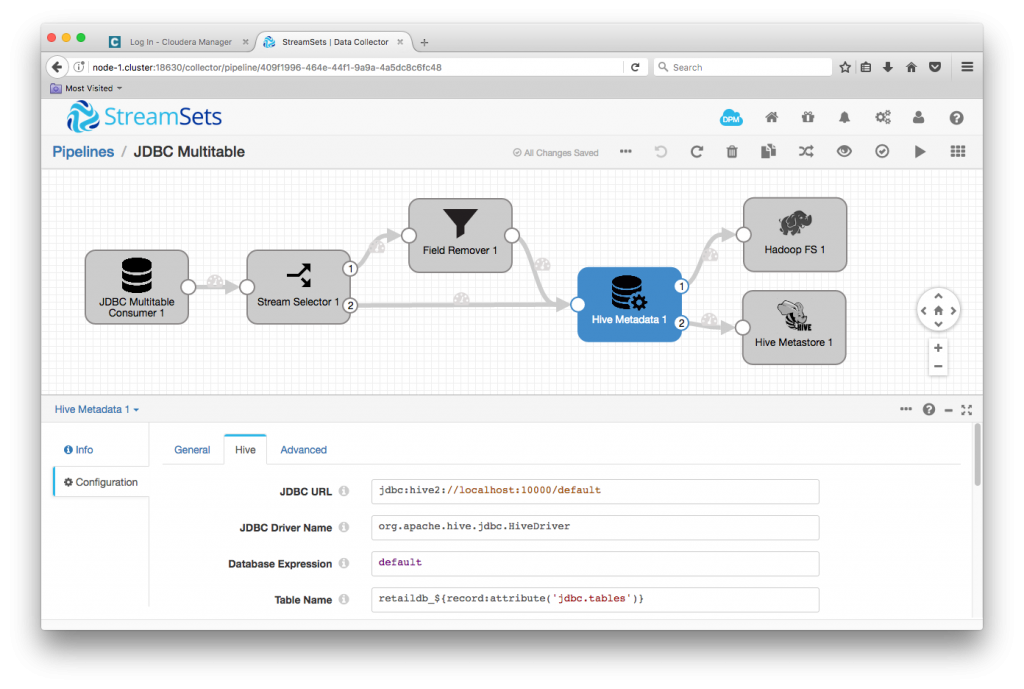
Since I was building a sample system, I changed the Hadoop FS destination’s Idle Timeout from its default ${1 * HOURS} to ${1 * MINUTES} – I was more interested in being able to quickly see records appearing in Hive, rather than maximizing the size of my output files!
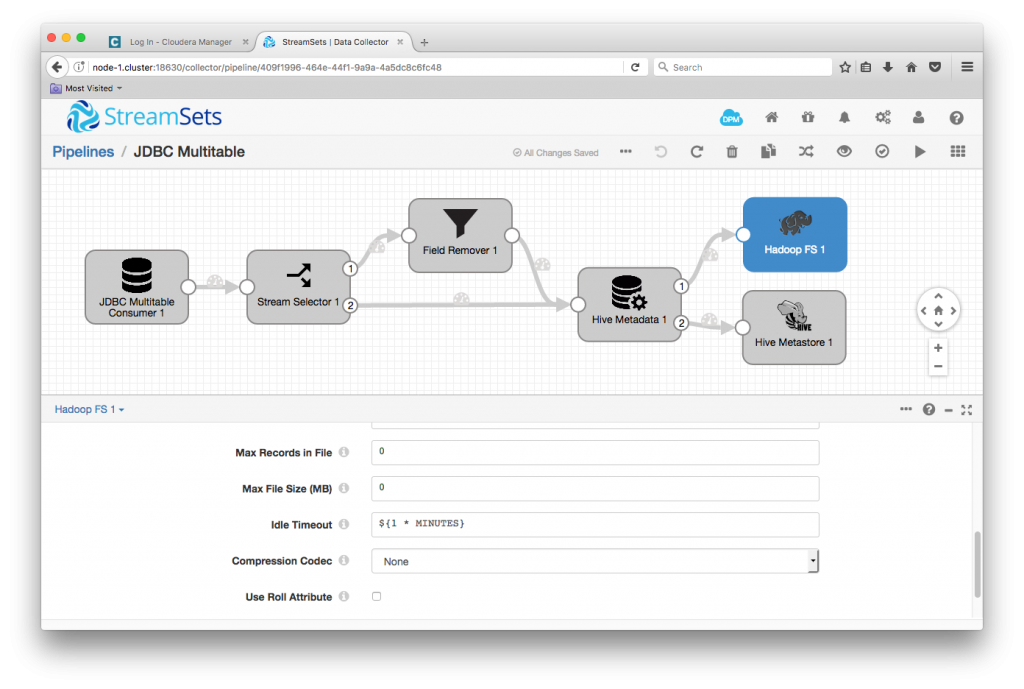
Refreshing Impala’s Metadata Cache
As it is now, this pipeline would read all of the data from MySQL and write it to Hive, but, if we were to use Impala to query Hive, we would not see any data. This is because we are writing data directly into Hadoop FS and metadata into Hive, we need to send Impala the INVALIDATE METADATA statement so that it reloads the metadata on the next query. We can do this automatically using SDC’s Event Framework. I just followed the Impala Metadata Updates for HDS case study, adding an Expression Evaluator and Hive Query Executor to automatically send INVALIDATE METADATA statements to Impala when closing a data file or changing metadata. Note that you’ll have to specify the Impala endpoint in the Hive Query Evaluator’s JDBC URL – for my setup, it was jdbc:hive2://node-2.cluster:21050/;auth=noSasl.
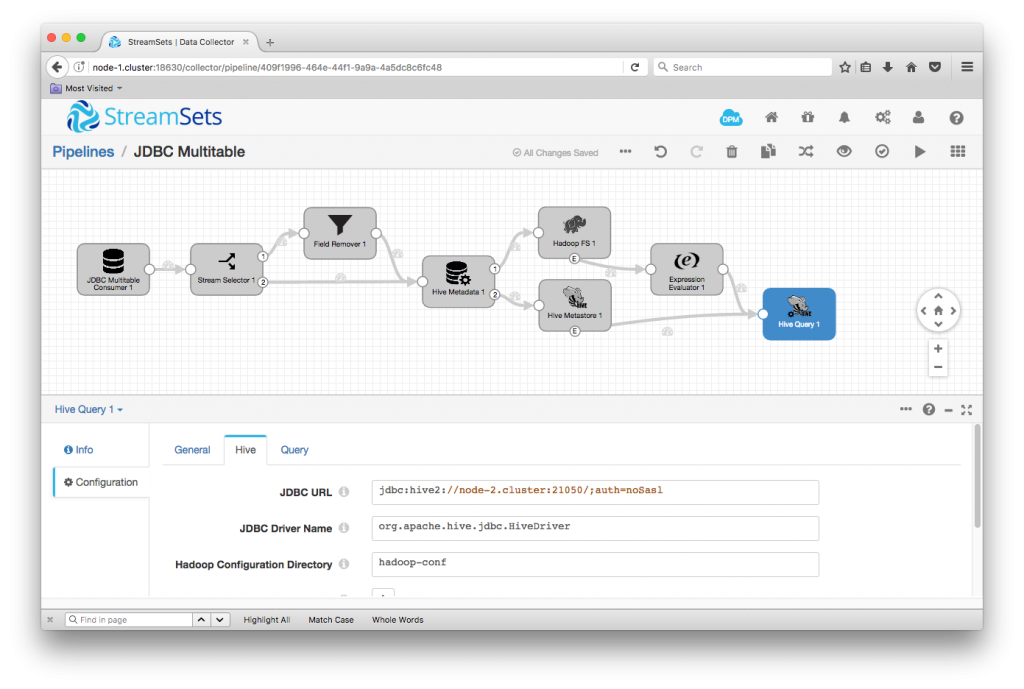
Once my pipeline was configured, I was able to run it. After a few minutes, the pipeline was quiet:
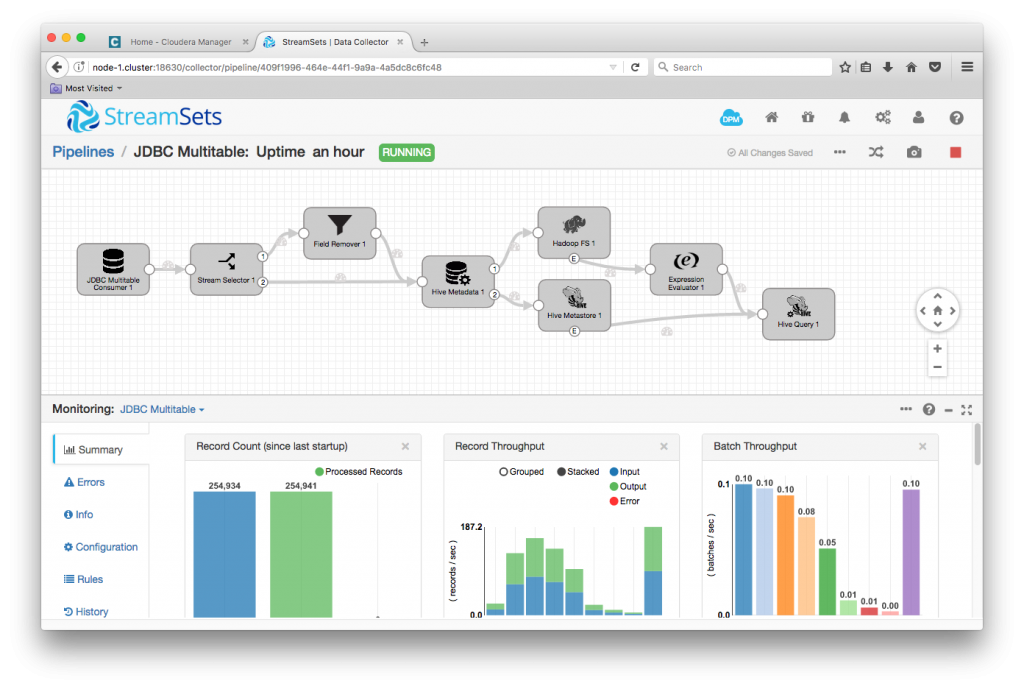
I was able to check that all the rows had been ingested by running SELECT COUNT(*) FROM tablename for each table in both MySQL and Impala:
[node-2.cluster:21000] > show tables; Query: show tables +--------------------------+ | name | +--------------------------+ | retaildb_categories | | retaildb_customers | | retaildb_departments | | retaildb_order_items | | retaildb_orders | | retaildb_products | | retaildb_shipping_events | +--------------------------+ Fetched 7 row(s) in 0.01s [node-2.cluster:21000] > select count(*) from retaildb_orders; Query: select count(*) from retaildb_orders Query submitted at: 2017-02-01 19:29:29 (Coordinator: http://node-2.cluster:25000) Query progress can be monitored at: http://node-2.cluster:25000/query_plan?query_id=b14f2b075be0e3b1:3e87dc1600000000 +----------+ | count(*) | +----------+ | 68883 | +----------+ Fetched 1 row(s) in 4.30s [node-2.cluster:21000] > select * from retaildb_orders order by order_id desc limit 3; Query: select * from retaildb_orders order by order_id desc limit 3 Query submitted at: 2017-02-01 19:30:05 (Coordinator: http://node-2.cluster:25000) Query progress can be monitored at: http://node-2.cluster:25000/query_plan?query_id=f441e0ae44664199:13321e9700000000 +----------+---------------------+-------------------+-----------------+ | order_id | order_date | order_customer_id | order_status | +----------+---------------------+-------------------+-----------------+ | 68883 | 2014-07-23 00:00:00 | 5533 | COMPLETE | | 68882 | 2014-07-22 00:00:00 | 10000 | ON_HOLD | | 68881 | 2014-07-19 00:00:00 | 2518 | PENDING_PAYMENT | +----------+---------------------+-------------------+-----------------+ Fetched 3 row(s) in 0.32s
Continuously Replicating Relational Databases
A key feature of the JDBC Multitable Consumer origin is that, like almost all SDC origins, it runs continuously. The origin retrieves records from each table in turn according to the configured interval, using a query of the form:
SELECT * FROM table WHERE offset_col > last_offset ORDER BY offset_col
In my sample, this will result in any new rows created in MySQL being copied across to Hive. Since I configured the Hadoop FS destination’s idle timeout to just one minute, I was able to quickly see data appear in the Hive table.
This short video highlights the key points in configuring the use case, and shows propagation of new rows from MySQL to Hive:
Conclusion on Replicating Relational Databases
The JDBC Multitable Consumer allows a single StreamSets Data Collector Engine pipeline to continuously ingest data from any number of tables in a relational database. Combined with the Hive Drift Solution you can quickly create powerful data pipelines to implement data warehouse use cases. Try it in StreamSets.